As of early/mid 2020, KataGo is one of the strongest open source Go bots available online, and on most common hardware should be moderately stronger than Leela Zero in most positions if tuned for performance. KataGo was trained using AlphaZero-like training with many modifications and enhancements that greatly improve the self-play learning, starting entirely from scratch with no outside data. Some of its enhancements take advantage of game-specific features and training targets, but also many of the techniques are general and could be applied in other games. Due to these enhancements, early training is immensely faster than in other zero-style bots - with only a few strong GPUs for a few days, even a single researcher/enthusiast should be able to train a neural net from nothing to high amateur dan strength on the full 19x19 board.
KataGo's latest run used about 29 GPUs, rather than thousands (like AlphaZero and ELF), first reached superhuman levels on that hardware in perhaps just three to six days, and reached strength similar to ELF in about 14 days. With minor adjustments and a few more GPUs, starting around 40 days it roughly began to match or surpass Leela Zero in some tests with different configurations, time controls, and hardware. And finally after about four months of training time, the current run may be wrapping up fairly soon, but we hope to be able to continue it or begin another run in the future.
Paper about the major new ideas and techniques used in KataGo: Accelerating Self-Play Learning in Go (arXiv). A few further improvements have been found and incorporated into the latest run that are not described in this paper - some post about this might happen eventually.
Many thanks to Jane Street for providing the computation power necessary to train KataGo, as well to run numerous many smaller testing runs and experiments. Blog posts about the initial release and some interesting subsequent experiments:
KataGo's engine also aims to be a useful tool for Go players and developers, and supports the following features:
- Estimates territory and score, rather than only "winrate", helping analyze kyu and amateur dan games besides only on moves that actually would swing the game outcome at pro/superhuman-levels of play.
- Cares about maximizing score, enabling strong play in handicap games when far behind, and reducing slack play in the endgame when winning.
- Supports alternative values of komi (including integer values) and good high-handicap game play.
- Supports board sizes ranging from 7x7 to 19x19, and as of May 2020 may be the strongest open-source bot on both 9x9 and 13x13 as well.
- Supports a wide variety of rules, including rules that match Japanese rules in almost all common cases, and ancient stone-counting-like rules.
- For tool/back-end developers - supports a JSON-based analysis engine that can batch multiple-game evaluations efficiently and be easier to use than GTP.
KataGo is on its third major official run! As of May 2020 after about 4 months of actual training time, it appears to be overall moderately stronger than Leela Zero's final official 40-block nets at moderate numbers of playouts (thousands to low tens of thousands), including with only its 20-block net, except for one notable opening pattern that Leela Zero still handles much better. Earlier, it also surpassed the prior 19-day official run from June 2019 in only about 12-14 days, and at this point is more than 700 Elo stronger. This is due to various training improvements which were not present in prior runs. In addition to reaching stronger faster, this third run adds support for Japanese rules, stronger handicap play, and more accurate score estimation.
Strong networks are available for download! See the releases page for the latest release and these neural nets. A history of older and alternative neural nets can be found here, including a few very strong smaller nets. These include a fast 10-block network that nearly matches the strength of many earlier 15 block nets, including KataGo best 15-block net from last year and Leela Zero's LZ150. This new run also features a very strong 15-block network that should be approximately the strength of ELFv2, a 20-block network, at least at low thousands of playouts. Hopefully they are useful for users with weaker hardware.
Here is a graph of the improvement so far as of about 120 days:
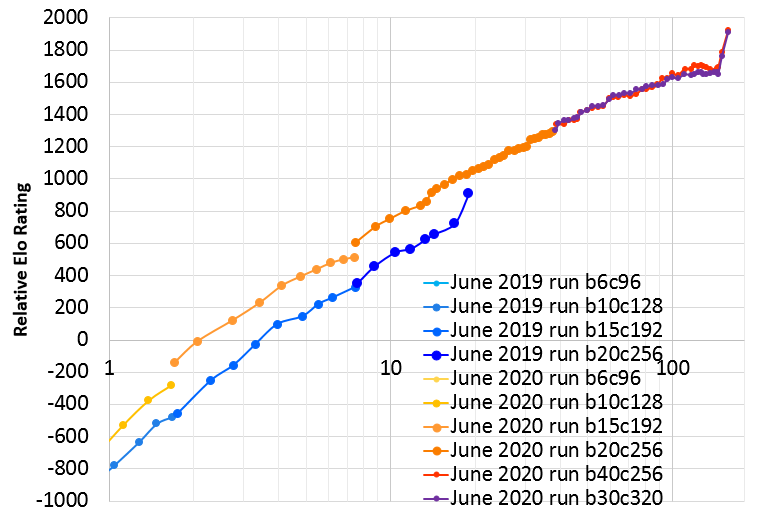 |
| X axis is days of training, log scale. (note: hardware is about the same but not entirely identical). Y axis is relative Elo rating based on some 1200-visit test matches. The abrupt jump at the end of the June 2019 run is due to a LR drop in that run that the current run applied in a more gradual way. |
Currently the run is using about 47 GPUs (40 of which are for self-play data generation). Only 29 GPUs were used to surpass last year's run in the first 14 days. After 14 days this was increased to 37 GPUs, then after 24 more days increased again to the current 47 GPUs.
Just for fun, here's a table of the Elo strength of selected versions, based on a few tens of thousands of games between these and other versions in a pool (1200 visits). These are based on fixed search tree size, NOT fixed computation time. Current run:
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b6c96-s175395328-d26788732 | (last selfplay 6 block) | 0.75 | -1184 |
| g170-b10c128-s197428736-d67404019 | (last selfplay 10 block) | 1.75 | -280 |
| g170e-b10c128-s1141046784-d204142634 | (extended training 10 block) | - | 300 |
| g170-b15c192-s497233664-d149638345 | (last selfplay 15 block) | 7.5 | 512 |
| g170e-b15c192-s1305382144-d335919935 | (extended training 15 block) | - | 876 |
| g170e-b15c192-s1672170752-d466197061 | (extended training 15 block) | - | 935 |
| g170-b20c256x2-s668214784-d222255714 | (20 block) | 15.5 | 959 |
| g170-b20c256x2-s1039565568-d285739972 | (20 block) | 21.5 | 1073 |
| g170-b20c256x2-s1420141824-d350969033 | (20 block) | 27.5 | 1176 |
| g170-b20c256x2-s1913382912-d435450331 | (20 block) | 35.5 | 1269 |
| g170-b20c256x2-s2107843328-d468617949 | (last selfplay 20 block) | 38.5 | 1293 |
| g170e-b20c256x2-s2430231552-d525879064 | (extended training 20 block) | 47.5 | 1346 |
| g170-b30c320x2-s1287828224-d525929064 | (30 block more channels) | 47.5 | 1412 |
| g170-b40c256x2-s1349368064-d524332537 | (40 block less channels) | 47 | 1406 |
| g170e-b20c256x2-s2971705856-d633407024 | (extended training 20 block) | 64.5 | 1413 |
| g170-b30c320x2-s1840604672-d633482024 | (30 block more channels) | 64.5 | 1524 |
| g170-b40c256x2-s1929311744-d633132024 | (40 block less channels) | 64.5 | 1510 |
| g170e-b20c256x2-s3354994176-d716845198 | (extended training 20 block) | 78 | 1455 |
| g170-b30c320x2-s2271129088-d716970897 | (30 block more channels) | 78 | 1551 |
| g170-b40c256x2-s2383550464-d716628997 | (40 block less channels) | 78 | 1554 |
| g170e-b20c256x2-s3761649408-d809581368 | (extended training 20 block) | 92 | 1513 |
| g170-b30c320x2-s2846858752-d829865719 | (30 block more channels) | 96 | 1619 |
| g170-b40c256x2-s2990766336-d830712531 | (40 block less channels) | 96 | 1613 |
| g170e-b20c256x2-s4384473088-d968438914 | (extended training 20 block) | 117 | 1529 |
| g170-b30c320x2-s3530176512-d968463914 | (30 block more channels) | 117 | 1643 |
| g170-b40c256x2-s3708042240-d967973220 | (40 block less channels) | 117 | 1687 |
And for comparison to the old 2019 June official run (Elos computed within the same pool):
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g104-b6c96-s97778688-d23397744 | (last selfplay 6 block) | 0.75 | -1146 |
| g104-b10c128-s110887936-d54937276 | (last selfplay 10 block) | 1.75 | -476 |
| g104-b15c192-s297383936-d140330251 | (last selfplay 15 block) | 7.5 | 327 |
| g104-b20c256-s447913472-d241840887 | (last selfplay 20 block) | 19 | 908 |
The first serious run of KataGo ran for 7 days in February 2019 on up to 35xV100 GPUs. This is the run featured the early versions of KataGo's research paper. It achieved close to LZ130 strength before it was halted, or up to just barely superhuman.
Following some further improvements and much-improved hyperparameters, KataGo performed a second serious run in May-June a max of 28xV100 GPUs, surpassing the February run after just three and a half days. The run was halted after 19 days, with the final 20-block networks reaching a final strength slightly stronger than LZ-ELFv2! (This is Facebook's very strong 20-block ELF network, running on Leela Zero's search architecture). Comparing to the yet larger Leela Zero 40-block networks, KataGo's network falls somewhere around LZ200 at visit parity, despite only itself being 20 blocks. Recent versions of the paper have been updated to reflect this run. Here is a graph of Elo ratings of KataGo's June run compared to Leela Zero and ELF based on a set of test games, where the X axis is an approximate measure of self-play computation required (note: log scale).
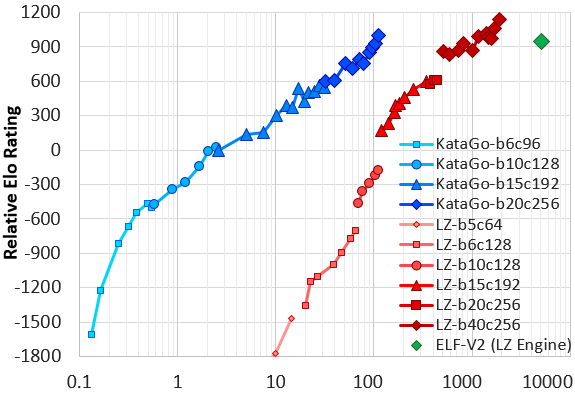 |
| June run of KataGo vs LZ and ELF. X axis is approx selfplay compute spent, log scale. Y axis is relative Elo rating. Leela Zero goes up to LZ225 on this graph. KataGo trains efficiently compared to other bots. See paper for details. |
The self-play training data from the run and full history of accepted models of these two older runs is available here.
See also https://github.com/lightvector/GoNN for some earlier research. KataGo is essentially a continuation of that research, but that old repo has been preserved since the changes in this repo are not backwards compatible, and to leave the old repo intact to continue as a showcase of the many earlier experiments performed there.
You can download precompiled executables for KataGo on the releases page for Windows and Linux.
You can download a few selected neural nets from the releases page or download additional other neural nets from here). There are two different model formats, indicated by ".txt.gz" versus ".bin.gz". Starting with v1.3.3, KataGo is moving to ".bin.gz" which is a binary format that is a little smaller on disk and faster to load. ".bin.gz" files will only work with v1.3.3 and later, but v1.3.3 and later can still load all earlier formats.
See sections below, particularly "How To Use" and "Tuning for Performance" sections below for how to use KataGo and things you may want to do before actually using KataGo.
If using the OpenCL version, KataGo will need to tune itself the first time it starts - try running the benchmark command described below.
KataGo implements just a GTP engine - GTP is a simple text protocol that Go software uses to communicate with engines. It does NOT have a graphical interface on its own. So generally, you will want to use KataGo along with a GUI or analysis program, such as Lizzie or Sabaki. Both of these programs also support KataGo's score estimates and visualization as well.
Warning: the version of KataGo packaged directly with Lizzie is fairly OLD. The net is quite weak compared to the latest nets, and the executable may not support the latest models or features. Download a newer version of both the net and executable from the releases page.
KataGo currently officially supports both Windows and Linux, with precompiled executables provided each release. Not all different OS versions and compilers have been tested, so if you encounter problems, feel free to open an issue. KataGo can also of course be compiled from source on Windows via MSVC on Windows or on Linux via usual compilers like g++, documented further down.
The community also provides KataGo packages for Homebrew on MacOS - releases there may lag behind official releases slightly.
Use brew install katago. The latest config files and networks are installed in KataGo's share directory. Find them via brew list --verbose katago. A basic way to run katago will be katago gtp -config $(brew list --verbose katago | grep gtp) -model $(brew list --verbose katago | grep .gz | head -1). You should choose the Network according to the release notes here and customize the provided example config as with every other way of installing KataGo.
KataGo has both an OpenCL version and a CUDA version.
- The CUDA version requires installing CUDA and CUDNN and a modern NVIDIA GPU.
- The OpenCL version should be able to run with many other GPUs or accelerators that support OpenCL, such AMD GPUs, as well CPU-based OpenCL implementations or things like Intel Integrated Graphics. (Note: Intel integrated graphics though is a toss-up - many versions of Intel's OpenCL seem to be buggy). It also doesn't require the hassle of CUDA and CUDNN and is more likely to work out of the box so long as you do have a decently modern GPU.
Depending on hardware and settings, in practice the OpenCL version seems to range from anywhere to several times slower to moderately faster than the CUDA version. More optimization work may happen in the future though - the OpenCL version has definitely not reached the limit of how well it can be optimized. It also has not been tested for self-play training with extremely large batch sizes to run hundreds of games in parallel, all of KataGo's main training runs so far have been performed with the CUDA implementation.
If your GPU is a top-end NVIDIA GPU and supports FP16 and tensor cores, then the CUDA version is likely to be by far the fastest and strongest, so long you specifically set KataGo to use FP16, and you increase and tune threads and batch size appropriately. See "Tuning for Performance" below.
KataGo supports a few commands. All of these commands require a "model" file that contains the neural net. Most also require a "config" file that specifies parameters for how KataGo behaves. KataGo's precompiled releases should come packaged with example configs (gtp_example.cfg). If you care about performance, you will likely want to edit this config for yourself - extensive comments and notes are provided in the config.
If you are running KataGo for the first time, you probably want to run the benchmark OR the genconfig options before anything else, to test if KataGo works and pick a number of threads. And on the OpenCL version, to give KataGo a chance to autotune itself, which could take a while.
For all of the below commands, you can omit the -model argument if you've put the model file into the same directory as the katago executable as default_model.bin.gz or default_model.txt.gz.
For all of the commands that require a GTP config, you can omit the -config argument if you've put the GTP config file into the same directory as the katago executable as default_gtp.cfg.
To run a benchmark to test performance and help you choose how many threads to use for best performance. You can then manually edit your GTP config to use this many threads:
./katago benchmark -tune -model <NEURALNET>.gz -config <GTP_CONFIG>.cfg
Or for example as noted above in bold, if you have a default config and model in the right place:
./katago benchmark -tune
To automatically tune threads and other settings for you based on asking simple questions, and generate a GTP config for you:
./katago genconfig -model <NEURALNET>.gz -output <PATH_TO_SAVE_GTP_CONFIG>.cfg
To run a GTP engine using a downloaded KataGo neural net and GTP config:
./katago gtp -model <NEURALNET>.gz -config <GTP_CONFIG>.cfg- Or from a different path:
whatever/path/to/katago gtp -model whatever/path/to/<NEURALNET>.gz -config /whatever/path/to/<GTP_CONFIG>.cfg - This is the command to tell your GUI (Lizzie, Sabaki, GoGui, etc) to use to run KataGo (with the actual paths to everything substituted currectly, of course).
Or for example as noted earlier above in bold, if you have a default config and model in the right place:
./katago gtp- Or from a different path:
whatever/path/to/katago gtp - Alternatively, this is the command you want to tell your GUI (Lizzie, Sabaki, GoGui, etc) to use to run KataGo (if you have a default config and model file).
Run a JSON-based analysis engine that can do efficient batched evaluations for a backend Go service:
./katago analysis -model <NEURALNET>.gz -config <ANALYSIS_CONFIG>.cfg -analysis-threads N
For OpenCL only: run or re-run the tuner to optimize for your particular GPU.
./katago tuner -model <NEURALNET>.gz
You will very likely want to tune some of the parameters in gtp_example.cfg or configs/gtp_example.cfg for your system for good performance, including the number of threads, fp16 usage (CUDA only), NN cache size, pondering settings, and so on. You can also adjust things like KataGo's resign threshold or utility function. All of this should be documented already directly in that example config file.
The OpenCL version will also automatically run a tuner on the first startup to optimize the neural net for your particular device or GPU. This might take a little time, but is completely normal and expected.
To test KataGo's performance with different settings you're trying and also to help choose a number of threads:
./katago benchmark -model <NEURALNET>.gz -config <GTP_CONFIG>.cfg
Or to do so automatically and generate a config appropriately:
./katago genconfig -model <NEURALNET>.gz -output <PATH_TO_SAVE_GTP_CONFIG>.cfg
This section summarizes a number of common issues that some users have encountered that caused KataGo to not be able to run.
If you are observing any crashes in KataGo while attempting to run the benchmark or the program itself, and you have one of the below GPUs, then this is likely the reason.
- AMD Radeon RX 5700 - AMD's drivers for OpenCL for this GPU have been buggy ever since this GPU was released, and as of May 2020 AMD has still never released a fix. If you are using this GPU, you will just not be able to run KataGo (Leela Zero and other Go engines will probably fail too) and will probably also obtain incorrect calculations or crash if doing anything else scientific or mathematical that uses OpenCL. See for example these reddit threads: [1] or [2] or this L19 thread.
- OpenCL Mesa - These drivers for OpenCL on AMD GPUs are buggy. If you are using an AMD GPU and on startup before crashing you see KataGo printing something like
Found OpenCL Platform 0: ... (Mesa) (OpenCL 1.1 Mesa ...) ...then you are using the Mesa drivers. You will need to change your drivers, see for example this KataGo issue which links to this thread. - Intel Integrated Graphics - For weaker/older machines or laptops or devices that don't have a dedicated GPU, KataGo might end up using the weak "Intel Integrated Graphics" that is built in with the CPU. Often this will work fine (although KataGo will be slow and only get a tiny number of playouts compared to using a real GPU), but various versions of Intel Integrated Graphics can also be buggy and not work at all. If a driver update doesn't work for you, then the only solution is to upgrade to a better GPU. See for example this issue or this issue, or this other Github's issue.
-
KataGo seems to hang or is "loading" forever on startup in Lizzie/Sabaki/q5go/GoReviewPartner/etc.
- Likely either you have some misconfiguration, have specified file paths incorrectly, a bad GPU, etc. Almost all of these GUIs do a poor job of reporting errors and may completely swallow the error message from KataGo that would have told you what was wrong. Try running KataGo's
benchmarkorgtpdirectly on the command line, as described above. - Sometimes there is no error at all, it is merely that the first time KataGo runs on a given network size, it needs to do some expensive tuning, which may take a few minutes. Again this is clearer if you run the
benchmarkcommand directly in the command line. After tuning, then subsequent runs will be faster.
- Likely either you have some misconfiguration, have specified file paths incorrectly, a bad GPU, etc. Almost all of these GUIs do a poor job of reporting errors and may completely swallow the error message from KataGo that would have told you what was wrong. Try running KataGo's
-
KataGo works on the command line but having trouble specfying the right file paths for Lizzie/Sabaki/ZBaduk/etc.
- As described above, you can name your config
default_gtp.cfgand name whichever network file you've downloaded todefault_model.bin.gz(for newer.bin.gzmodels) ordefault_model.txt.gz(for older.txt.gzmodels). Stick those into the same directory as KataGo's executable, and then you don't need to specify-configor-modelpaths at all.
- As described above, you can name your config
-
KataGo gives an error like
Could not create filewhen trying to run the initial tuning.- KataGo probably does not have access permissions to write files in the directory where you placed it.
- On Windows for example, the
Program Filesdirectory and its subdirectories are often restricted to only allow writes with admin-level permissions. Try placing KataGo somewhere else.
In addition to a basic set of GTP commands, KataGo supports a few additional commands, for use with analysis tools and other programs.
KataGo's GTP extensions are documented here.
-
Notably: KataGo exposes a GTP command
kata-analyzethat in addition to policy and winrate, also reports an estimate of the expected score and a heatmap of the predicted territory ownership of every location of the board. Expected score should be particularly useful for reviewing handicap games or games of weaker players. Whereas the winrate for black will often remain pinned at nearly 100% in a handicap game even as black makes major mistakes (until finally the game becomes very close), expected score should make it more clear which earlier moves are losing points that allow white to catch up, and exactly how much or little those mistakes lose. If you're interested in adding support for this to any analysis tool, feel free to reach out, I'd be happy to answer questions and help. -
KataGo also exposes a few GTP extensions that allow setting what rules are in effect (Chinese, AGA, Japanese, etc). See again here for details.
KataGo also implements a separate engine that can evaluate much faster due to batching if you want to analyze whole games at once and might be much less of a hassle than GTP if you are working in an environment where JSON parsing is easy. See here for details.
KataGo is written in C++. It should compile on Linux or OSX via g++ that supports at least C++14, or on Windows via MSVC 15 (2017) and later. Other compilers and systems have not been tested yet. This is recommended if you want to run the full KataGo self-play training loop on your own and/or do your own research and experimentation, or if you want to run KataGo on an operating system for which there is no precompiled executable available.
- Requirements
- CMake with a minimum version of 3.10.2 - for example
sudo apt install cmakeon Debian, or download from https://cmake.org/download/ if that doesn't give you a recent-enough version. - Some version of g++ that supports at least C++14.
- If using the OpenCL backend, a modern GPU that supports OpenCL 1.2 or greater, or else something like this for CPU. (Of course, CPU implementations may be quite slow).
- If using the CUDA backend, CUDA 10.1 and CUDNN 7.6.1 (https://developer.nvidia.com/cuda-toolkit) (https://developer.nvidia.com/cudnn) and a GPU capable of supporting them. I'm unsure how version compatibility works with CUDA, there's a good chance that later versions than these work just as well, but they have not been tested.
- zlib, libzip, boost filesystem. With Debian packages (i.e. apt or apt-get), these should be
zlib1g-dev,libzip-dev,libboost-filesystem-dev. - If you want to do self-play training and research, probably Google perftools
libgoogle-perftools-devfor TCMalloc or some other better malloc implementation. For unknown reasons, the allocation pattern in self-play with large numbers of threads and parallel games causes a lot of memory fragmentation under glibc malloc that will eventually run your machine out of memory, but better mallocs handle it fine.
- CMake with a minimum version of 3.10.2 - for example
- Clone this repo:
git clone https://github.com/lightvector/KataGo.git
- Compile using CMake and make in the cpp directory:
cd KataGo/cppcmake . -DUSE_BACKEND=OPENCLorcmake . -DUSE_BACKEND=CUDAdepending on which backend you want. Specify also-DUSE_TCMALLOC=1if using TCMalloc. Compiling will also call git commands to embed the git hash into the compiled executable, specify also-DNO_GIT_REVISION=1to disable it if this is causing issues for you.make
- Done! You should now have a compiled
katagoexecutable in your working directory. - Pre-trained neural nets are available on the releases page or more from here.
- You will probably want to edit
configs/gtp_example.cfg(see "Tuning for Performance" above). - If using OpenCL, you will want to verify that KataGo is picking up the correct device when you run it (e.g. some systems may have both an Intel CPU OpenCL and GPU OpenCL, if KataGo appears to pick the wrong one, you can correct this by specifying
openclGpuToUseinconfigs/gtp_example.cfg).
- Requirements
- CMake with a minimum version of 3.10.2, GUI version strongly recommended (https://cmake.org/download/)
- Microsoft Visual Studio for C++. Version 15 (2017) has been tested and should work, other versions might work as well.
- If using the OpenCL backend, a modern GPU that supports OpenCL 1.2 or greater, or else something like this for CPU. (Of course, CPU implementations may be quite slow).
- If using the CUDA backend, CUDA 10.1 and CUDNN 7.6.1 (https://developer.nvidia.com/cuda-toolkit) (https://developer.nvidia.com/cudnn) and a GPU capable of supporting them. I'm unsure how version compatibility works with CUDA, there's a good chance that later versions than these work just as well, but they have not been tested.
- Boost. You can obtain prebuilt libraries for Windows at: https://www.boost.org/users/download/ -> "Prebuilt windows binaries" -> "1.70.0". For example, boost_1_70_0-msvc-14.1-64.exe if you're on 64-bit windows. Note that MSVC 14.1 libraries (2015) are directly-compatible with MSVC 15 (2017).
- zlib. The following package might work, https://www.nuget.org/packages/zlib-vc140-static-64/, or alternatively you can build it yourself via something like: https://github.com/kiyolee/zlib-win-build
- libzip (optional, needed only for self-play training) - for example https://github.com/kiyolee/libzip-win-build
- Download/clone this repo to some folder
KataGo. - Configure using CMake GUI and compile in MSVC:
- Select
KataGo/cppas the source code directory in CMake GUI. - Set the build directory to wherever you would like the built executable to be produced.
- Click "Configure". For the generator select your MSVC version, and also select "x64" for the platform if you're on 64-bit windows.
- If you get errors where CMake has not automatically found Boost, ZLib, etc, point it to the appropriate places according to the error messages (by setting
BOOST_ROOT,ZLIB_INCLUDE_DIR,ZLIB_LIBRARY, etc). Note that "*_LIBRARY" expects to be pointed to the ".lib" file, whereas the ".dll" file is what you actually need to run. - Also set
USE_BACKENDtoOPENCLorCUDA, and adjust options likeNO_GIT_REVISIONif needed, and run "Configure" again as needed. - Once running "Configure" looks good, run "Generate" and then open MSVC and build as normal in MSVC.
- Select
- Done! You should now have a compiled
katago.exeexecutable in your working directory. - Note: You may need to copy the ".dll" files corresponding to the various ".lib" files you compiled with into the directory containing katago.exe.
- Note: If you had to update or install CUDA or GPU drivers, you will likely need to reboot before they will work.
- Pre-trained neural nets are available on the releases page or more from here.
- You will probably want to edit
configs/gtp_example.cfg(see "Tuning for Performance" above). - If using OpenCL, you will want to verify that KataGo is picking up the correct device (e.g. some systems may have both an Intel CPU OpenCL and GPU OpenCL, if KataGo appears to pick the wrong one, you can correct this by specifying
openclGpuToUseinconfigs/gtp_example.cfg).
If you'd also like to run the full self-play loop and train your own neural nets using the code here, see Selfplay Training.
Many thanks to the various people who have contributed to this project! See CONTRIBUTORS for a list of contributors.
Except for several external libraries that have been included together in this repo under cpp/external/ as well as the single file cpp/core/sha2.cpp, which all have their own individual licenses, all code and other content in this repo is released for free use, modification, or other purposes under a BSD-style license. See LICENSE file for details.
License aside, if you end up using any of the code in this repo to do any of your own cool new self-play or neural net training experiments, I (lightvector) would to love hear about it.