Zooming-Slow-Mo (CVPR-2020)
By Xiaoyu Xiang*, Yapeng Tian*, Yulun Zhang, Yun Fu, Jan P. Allebach+, Chenliang Xu+ (* equal contributions, + equal advising)
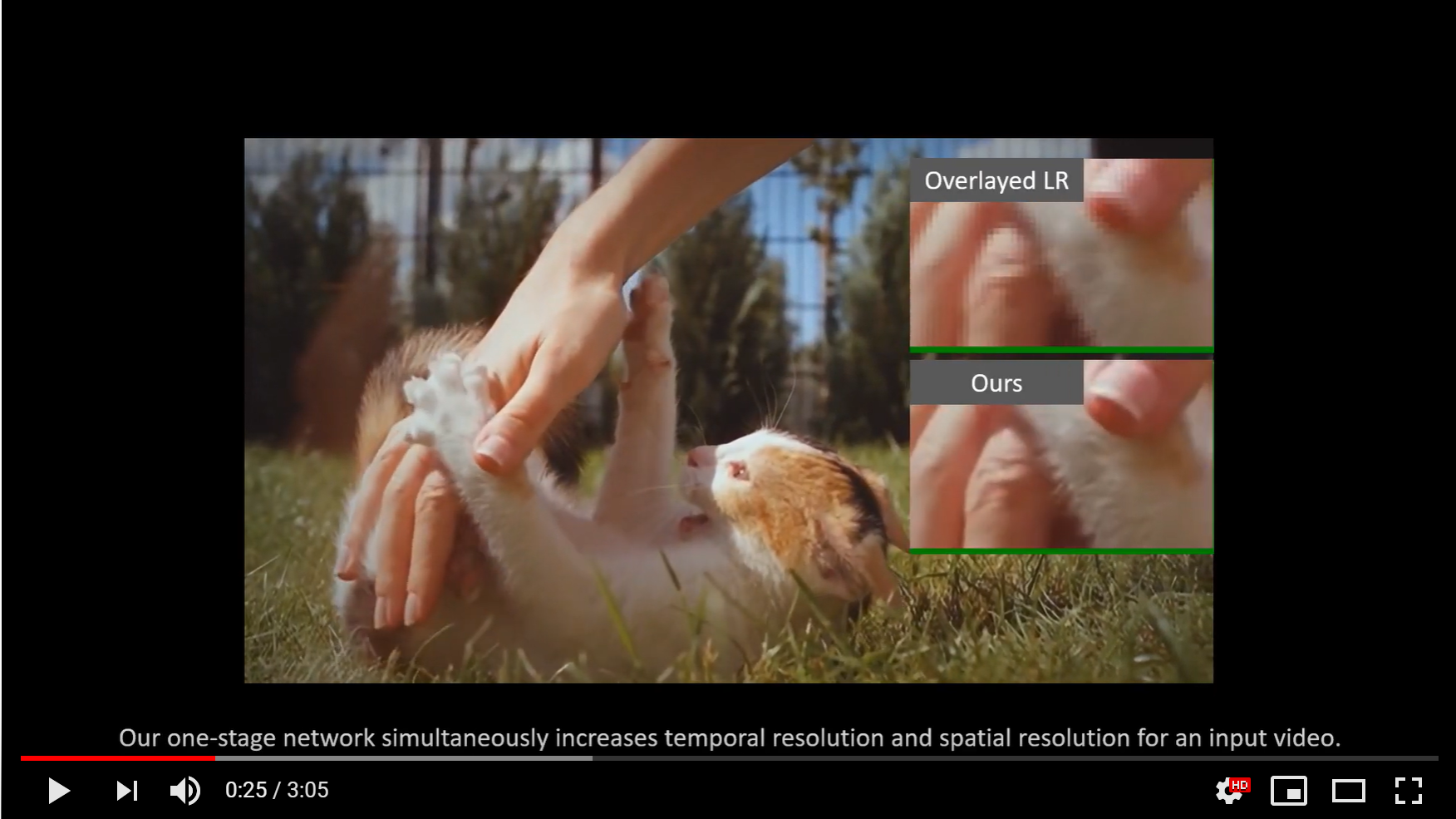
This is the official Pytorch implementation of Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution.
Paper | [Project Page] | Demo Video
Updates
- 2020.3.13 Add meta-info of datasets used in this paper
- 2020.3.11 Add new function: video converter
- 2020.3.10: Upload the complete code and pretrained models
Contents
Introduction
The repository contains the entire project (including all the preprocessing) for one-stage space-time video super-resolution with Zooming Slow-Mo.
Zooming Slow-Mo is a recently proposed joint video frame interpolation (VFI) and video super-resolution (VSR) method, which directly synthesizes an HR slow-motion video from an LFR, LR video. It is going to be published in CVPR 2020. The most up-to-date paper with supplementary materials can be found at arXiv.
In Zooming Slow-Mo, we firstly temporally interpolate features of the missing LR frame by the proposed feature temporal interpolation network. Then, we propose a deformable ConvLSTM to align and aggregate temporal information simultaneously. Finally, a deep reconstruction network is adopted to predict HR slow-motion video frames. If our proposed architectures also help your research, please consider citing our paper.
Zooming Slow-Mo achieves state-of-the-art performance by PSNR and SSIM in Vid4, Vimeo test sets.

Prerequisites
- Python 3 (Recommend to use Anaconda)
- PyTorch >= 1.1
- NVIDIA GPU + CUDA
- Deformable Convolution v2, we adopt CharlesShang's implementation in the submodule.
- Python packages:
pip install numpy opencv-python lmdb pyyaml pickle matplotlib seaborn
Get Started
Installation
First, make sure your machine has a GPU, which is required for the DCNv2 module.
- Clone the Zooming Slow-Mo repository. We'll call the directory that you cloned Zooming Slow-Mo as ZOOMING_ROOT.
git clone --recursive https://github.com/Mukosame/Zooming-Slow-Mo-CVPR-2020.git- Compile the DCNv2:
cd $ZOOMING_ROOT/codes/models/modules/DCNv2
bash make.sh # build
python test.py # run examples and gradient check Please make sure the test script finishes successfully without any errors before running the following experiments.
Training
Part 1: Data Preparation
- Download the original training + test set of
Vimeo-septuplet(82 GB).
wget http://data.csail.mit.edu/tofu/dataset/vimeo_septuplet.zip
apt-get install unzip
unzip vimeo_septuplet.zip- Split the
Vimeo-septupletinto a training set and a test set, make sure you change the dataset's path to your download path in script, also you need to run for the training set and test set separately:
cd $ZOOMING_ROOT/codes/data_scripts/sep_vimeo_list.pyThis will create train and test folders in the directory of vimeo_septuplet/sequences.
- Generate low resolution (LR) images. You can either do this via MATLAB or Python (remember to configure the input and output path):
# In Matlab Command Window
run $ZOOMING_ROOT/codes/data_scripts/generate_LR_Vimeo90K.mpython $ZOOMING_ROOT/codes/data_scripts/generate_mod_LR_bic.py - Create the LMDB files for faster I/O speed. Note that you need to configure your input and output path in the following script:
python $ZOOMING_ROOT/codes/data_scripts/create_lmdb_mp.pyPart 2: Train
Note: In this part, we assume you are in the directory $ZOOMING_ROOT/codes/
-
Configure your training settings that can be found at options/train. Our training settings in the paper can be found at train_zsm.yml. We'll take this setting as an example to illustrate the following steps.
-
Train the Zooming Slow-Mo model.
python train.py -opt options/train/train_zsm.ymlAfter training, your model xxxx_G.pth and its training states, and a corresponding log file train_LunaTokis_scratch_b16p32f5b40n7l1_600k_Vimeo_xxxx.log are placed in the directory of $ZOOMING_ROOT/experiments/LunaTokis_scratch_b16p32f5b40n7l1_600k_Vimeo/.
Testing
We provide the test code for both standard test sets (Vid4, SPMC, etc.) and custom video frames.
Pretrained Models
Our pretrained model can be downloaded via GitHub or Google Drive.
From Video
If you have installed ffmpeg, you can convert any video to a high-resolution and high frame-rate video using video_to_zsm.py. The corresponding commands are:
cd $ZOOMING_ROOT/codes
python video_to_zsm.py --video PATH/TO/VIDEO.mp4 --model PATH/TO/PRETRAINED/MODEL.pth --output PATH/TO/OUTPUT.mp4We also write the above commands to a Shell script, so you can directly run:
bash zsm_my_video.shFrom Extracted Frames
As a quick start, we also provide some example images in the test_example folder. You can test the model with the following commands:
cd $ZOOMING_ROOT/codes
python test.py-
You can put your own test folders in the test_example too, or just change the input path, the number of frames, etc. in test.py.
-
Your custom test results will be saved to a folder here:
$ZOOMING_ROOT/results/your_data_name/.
Evaluate on Standard Test Sets
The test.py script also provides modes for evaluation on the following test sets: Vid4, SPMC, etc. We evaluate PSNR and SSIM on the Y-channels in YCrCb color space. The commands are the same with the ones above. All you need to do is the change the data_mode and corresponding path of the standard test set.
Citations
If you find the code helpful in your resarch or work, please cite the following papers.
@InProceedings{xiang2020zooming,
author = {Xiang, Xiaoyu and Tian, Yapeng and Zhang, Yulun and Fu, Yun and Jan, Allebach and Xu, Chenliang},
title = {Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time VideoSuper-Resolution},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
@InProceedings{tian2018tdan,
author={Yapeng Tian, Yulun Zhang, Yun Fu, and Chenliang Xu},
title={TDAN: Temporally Deformable Alignment Network for Video Super-Resolution},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
@InProceedings{wang2019edvr,
author = {Wang, Xintao and Chan, Kelvin C.K. and Yu, Ke and Dong, Chao and Loy, Chen Change},
title = {EDVR: Video restoration with enhanced deformable convolutional networks},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
month = {June},
year = {2019},
}Contact
Xiaoyu Xiang and Yapeng Tian.
You can also leave your questions as issues in the repository. We will be glad to answer them.
License
This project is released under the GNU General Public License v3.0.