In this task your goal is to implement two different but simple searching algorithms and do a comparison of their performance. The performance is measured in time taken for varying sizes of data.
There are many occasions where we want to search for something. At home we might forget where our keys are so we naturally start looking for them every place we think they could be or we simply blame someone else for misplacing them, which is especially easy if you have kids :). But unfortunately the only one to blame when it comes to programming is the coder him/herself. A very common operation in relation to data structures is to check for the existance and/or location of a value within a datastructure. For example, we might want to check at which index the string "spaghetti hat" appears in a list (if it even exists). Most data structures already have some sort of built-in method for doing this but how do we actually go about implementing this ourselves? Let's take a look at the most straightforward and probably easiest search algorithm to implement: linear search.
You've just gotten yourself a lovely cabinet made out of 105% mahogany that looks something like this:

You also just lost one sock from your favorite pair and suspect that it might be in one of the drawers. To find out if that is indeed the case, what do you do? It's simple: you start with the top drawer and check if it's there. If not you move on to the next drawer just below the first one and repeat the check. If it's not there you move on to the third drawer and so forth. At the end of this procedure you're going to know either which drawer the missing sock is in or you're going to know that the sock is not in the cabinet at all. Congratulations, you've just performed a real life linear search! And as we all know, everything we can do in real life we can do on a computer so let's take a look at how the linear search work on a sequential data structure like list, here's a visualisation:

And here is the pseudocode for it:
Linear search (v, L)
------------------
1 for i = 0 to L.length
2 if L[i] == v
3 return i
4 return -1You have been provided with some different classes, among them a test class for the search at src/test/SearchTest.java that asserts that
Search is correctly implemented. If you go ahead and run the tests will see that some if not all
tests fail. Your job is to implement the linearSearch method within the Search class (using linear search of course) so that
the tests for linear search pass.
Assistant's note: Linear search only accounts for half of the tests so don't expect all tests to pass after implementing it (although all tests that are named linearSearch should pass).
Hopefully implementing linear search was a breeze, if not... well it get's more interesting (read difficult). Let's go back to another more realistic scenario for this one:
Realistic real life example 1
Some random person on the street hands you an 800-page english–russian dictionary and seeing as you are a
curious and culturally cultivated
person you start looking up some useful words, beginning with the word potato. Now you could look
for the translation by starting at the very first page of the dictionary, checking if it is there and then
move on to the next page if not and then to the next page and so on. But you are way smarter than that, what
you probably do instead is jump directly roughly to page 500 and start looking from there. If the words you
are seeing on this page are alphabetically before the word potato you jump a bit more towards the end of the book
and vice-versa if the words are alphabetically after the word potato. Before long you reach the translation
for this lovely vegetable and see the translation картофель. Using this technique, you quickly become proficient in russian,
even learning to say things like "У меня так много картошки, я не знаю почему" which roughly translates to
"I care for you very much and wish you well".
That is pretty much how binary search works. As you can imagine, it is probably a bit faster than linear search but the thing is that it only works when the data structure is sorted! Imagine having to look through a completely unsorted dictionary for a translation. By the time you find the word you will have forgotten what word it was. Luckily, that is not reality. What is reality though is the binary search we're going to implement. Here's another visualization showing binary search in comparison to sequential (linear) search:
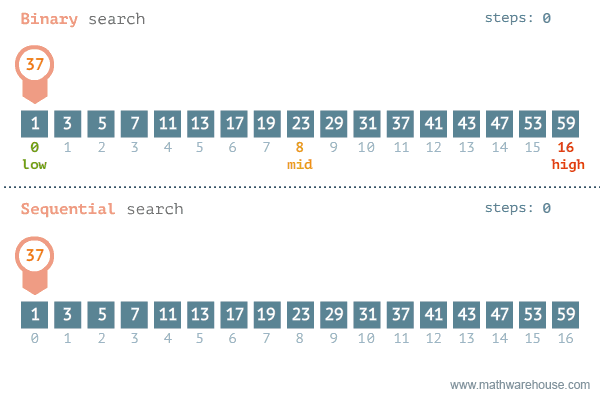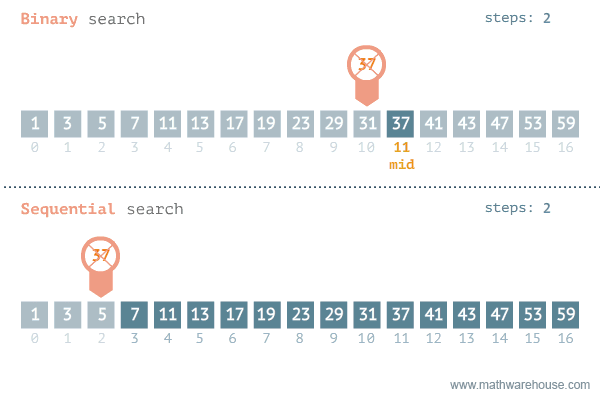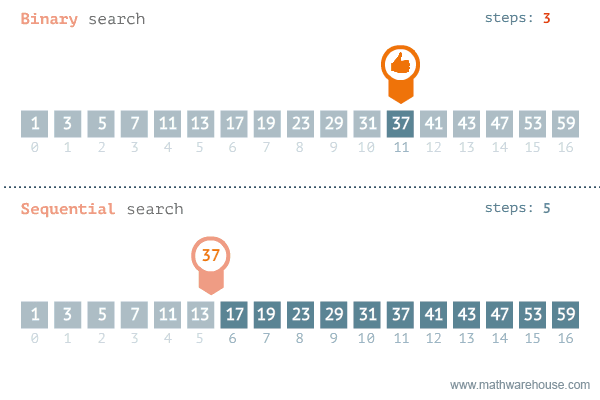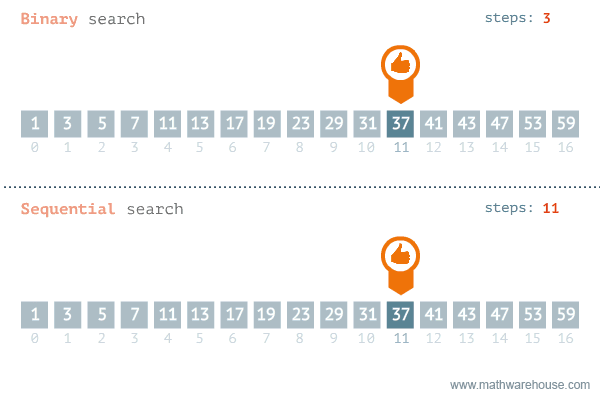
Take good note of the binary search and you see that it has to keep track of low, mid and high to
know which section to look at. This is something you will have to take into account. Here is the algorithm in
form of pseudocode (taken straight from Wikipedia):
function binary_search(A, n, T) is
L := 0
R := n − 1
while L ≤ R do
m := floor((L + R) / 2)
if A[m] < T then
L := m + 1
else if A[m] > T then
R := m − 1
else:
return m
return unsuccessfulSome things to note in the above pseudocode:
Ais the array.- Input argument
nis the length of arrayA. In Java this argument is not necessary as you can get the length by usingA.length. And before you ask... yes, there are programming languages where you can't get the length directly from the array (C/C++). Lis equivalent tolowif we compare with the visualization.Ris equivalent tohighif we compare with the visualization.mis equivalent tomidif we compare with the visualization.- Instead of returning
unsuccessfulyou should return-1.
Once again in the Search class we have to implement a method. This time we're implementing the
binarySearch method. And of course, we will be implementing it using the binary search algorithm iteratively (using
for/while loops).
When your binary search is done, all tests for binarySearch (iterative) in SearchTest should pass. Note that
the tests called binarySearchRecursive will still fail.
So the final method in Search that is to be implemented is the binarySearchRecursive method. It uses the very same
binary search algorithm but this time it does it recursively (make sure you've read about recursion). In short, it means
that it should not use for or while instead it should use a method call to itself with certain parameters.
For this to work, two things must happen:
- The parameters' value need to change with each method call because if we call the same method with exactly the same values in parameters we will end up in an infinite loop.
- There needs to be a so called base case (or stop condition) based on the parameter values where the recursion stops (no more method calls).
- With each recursion, the values of the parameters need to be one step closer to the base case.
If the above are not fulfilled, you usually end up with an infinite loop, and a stack overflow error.
When your recursive binary search is done, all tests in SearchTest should pass.
So, now that we've finally implemented these search algorithms, it is time to look a bit deeper into how they differ performance-wise. We suspect that they have differences in runtime but just how big are the differences?
Take a look at the Timer class which is used to measure the time performance of your
implementations by generating a sorted array with a given length (DATASIZE) and calculating
the time taken to search it for a random value. There is a block of code that has been commented out so go ahead and uncomment
that block and run the main method several times with different values for DATASIZE.
For example, you can run the main method with DATASIZE values 2000, 20000, 200000, etc. or choose your own
values. The only requirements are:
- You have to do it for at least 5 different values.
- Each next value should differ in size from the previous value by a factor of 10.
- No need to use both iterative and recursive binary search, you can choose one of them.
Here's a template you should use to fill in the results.
Now that you've timed the values you should be able to see that there are some differences in their runtime. But what is even more interesting is the change of runtime as input size gets larger.
- Which one of the algorithms is actually faster?
- Why is it faster?
- Is it faster for all sizes of data? Why or why not?
- Bonus (Optional) How does recursion compare to iteration? What are the advantages/disadvantages? Here it could be a good idea to think about it in regards to ease of implementation and also thinking about other operations on other datastructures. Take the recursive binary tree search example from the lecture, how would that look iteratively?
- Bonus (Optional) Now, take a look at this video explaining something called the Big-O notation. Try to classify linear search and binary search using this notation and motivate why that is.
Assistant's note: The last question might be a bit difficult for the binary search, as it requires some mathematical thinking, try solving it together with your team. Big-O notation is one of the classifications used in scientific research of algorithms when measuring performance. There are also other notations but this is probably the most common one.