- monk : Data Set.
- shuttle_landing : Data Set.
- Soyabean_small : Data Set.
- spect_heart : Data Set.
- tic_tac_toe : Data Set.
- Answers.txt : File which reports the accuracy of the classifier.
- Implemented a naive bayes classifier for 5 different data sets. Not using inbuilt libraries but instead highlighting the math behind the classifier
- All the data set folders contains data contains following :-
- Main.py : Python3 script which implements naive bayes classifier and writes the accuracy to “Answers.txt”.
- data : Data points .(Some contain multiple data files).
- In Spect Heart set and Monk set we have been given data set and test data, in which we can test.
- In Shuttle Landing, Soyabean Small, Tic-Tac-Toe we have been given data set. But there are not predefined test data points, hence I have performed leave one out cross validation.
- In Monk Data Set, 3 different data set's and corresponding test data is given. I have treated these data sets as different data sets. Trained classifier on individual data set and tested it in the corresponding test data.
- In Shuttle Landing data set, certain points were given as don't care(‘’). I have used the following convention in this case. While calculating probabilities of different features, I did not considered don't care(‘’) as any of the feature. While predicting probability of different classes of the test data point, I have taken probability of don't care as 1, as don't care can be any feature
- Accuracy reported in this data set = (no. of passed test cases in all the three data sets)/(total number of data points).
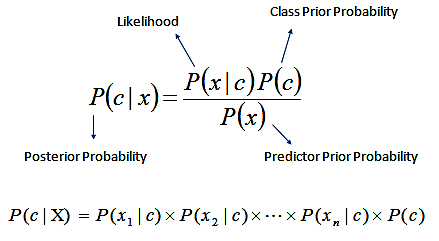
- Formula Used :
- Dataset's Downloaded From:
- Tic-Tac-Toe Endgame Data Set (https://archive.ics.uci.edu/ml/datasets/Tic-Tac-Toe+Endgame)
- SPECT Heart Data Set (https://archive.ics.uci.edu/ml/datasets/SPECT+Heart)
- Soybean (Small) Data Set (https://archive.ics.uci.edu/ml/datasets/Soybean+%28Small%29)
- Shuttle Landing Control Data Set (https://archive.ics.uci.edu/ml/datasets/Shuttle+Landing+Control)
- MONK's Problems Data Set (https://archive.ics.uci.edu/ml/datasets/MONK%27s+Problems)
- Numpy Module.
- Pandas Module.
- Python3