Note for CKAN users: The DataProxy is not actively maintained. Users looking for a structured API for tabular data and robust visualizations should use the CKAN DataStore
Data Proxy is a web service for converting data resources into structured form such as json.
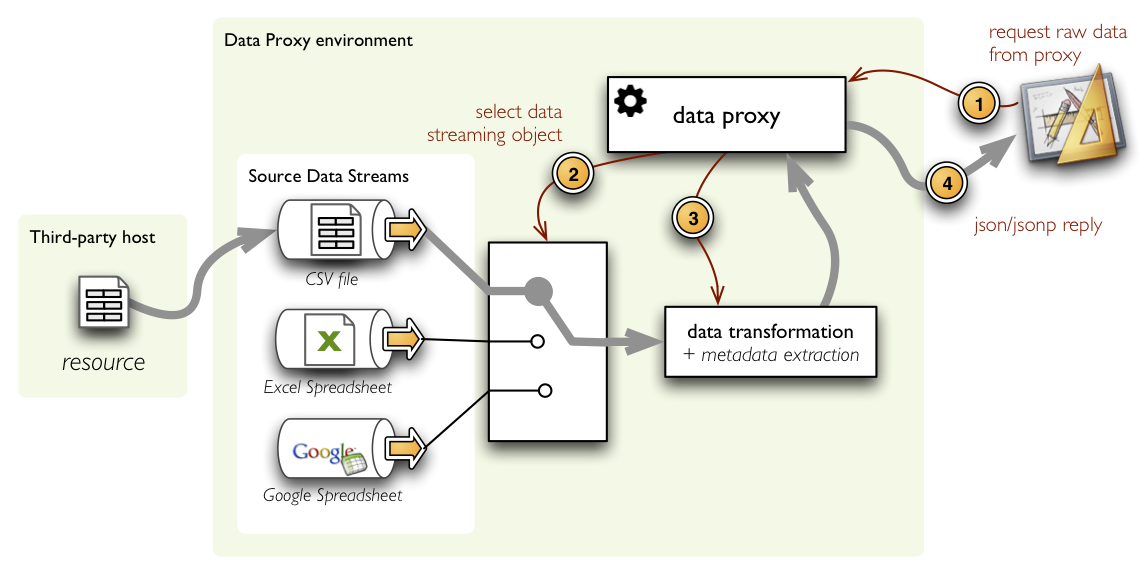
Supported resource/file types (type= parameter or file extension):
| Type | Description |
|---|---|
| csv | Comma separated values text file |
| xls | Microsoft Excel Spreadsheet |
| xlsx | Microsoft Excel Spreadsheet (xlsx) |
Supported reply format (format= parameter) types:
- json
- jsonp (default)
http://jsonpdataproxy.appspot.com/
Use:
DATA_PROXY_URL?url=...
| Parameter | Description |
|---|---|
url |
URL of data resource, such as XLS or CSV file. This is required |
type |
Resource/file type. This overrides autodetection based on file extension. You should also use this if there is no file extension in the URL but you know the type of the resource. |
max-results |
Maximum nuber of results (rows) returned |
format |
Output format. Currently json and
jsonp are supported |
guess-types |
If set attempt to do type guessing on source data return the guessed type in metadata and using the type to cast data |
XLS(X) Parameters:
| Parameter | Description |
|---|---|
worksheet |
Worksheet number (first sheet is 1, etc) |
CSV Parameters:
| Parameter | Description |
|---|---|
encoding |
Source character encoding. |
Get whole file as json:
DATA_PROXY_URL?url=http://democracyfarm.org/f/ckan/foo.csv&format=json
result:
{
"data" : [
[ "first-value", "second-value", "third-value" ],
...
],
"url" : "http://democracyfarm.org/f/ckan/foo.csv",
// backwards compatibility - will be deprecated at some point - use metadata
"fields": [
"first-field-id",
"second-field-id",
...
],
"metadata": {
"fields": [
// follows http://www.dataprotocols.org/en/latest/json-table-schema.html
{
"id": "field-name",
// if we guess types ...
"type": "type-name"
},
...
]
}
}
Get only first 3 rows as json:
DATA_PROXY_URL?url=http://democracyfarm.org/f/ckan/foo.csv&max-results=3&format=json
result:
{
"response" : [
[ "name","type","amount" ],
[ "apple","fruit",10 ],
[ "bananna","fruit",20 ],
],
"max-results": 3,
"header" : {
"url" : "http://democracyfarm.org/f/ckan/foo.csv",
}
}
| Error | Resolution |
|---|---|
| Unknown reply format | Specify supported reply format (json, jsonp) |
| No url= option found | Provide obligatory url parameter |
| Could not determine the file type | URL file/resource has no known file extension,
provide file type in type parameter:
type=csv |
| Resource type not supported | There is no tranformation module available for given resource/file type. Please refer to the list of supported resource types. |
| Only http is allowed | Only HTTP URL scheme is currently supported. Make sure that you are accessing HTTP only or try to find HTTP alternative for the resource. |
| Could not fetch file | It was not possible to access resource at given URL Check the URL or resource hosting server. |
| The requested file is too big to proxy | Proxy handles files only within certain size limit. Use alternative smaller resource if possible. |
| Data transformation error | An error occured during transformation of resource to structured data. Please refer to the additional message to learn what went wrong. |
Get the repo:
git clone https://github.com/okfn/dataproxy
Install the submodules (we use submodules or downloaded libraries rather than requirements file as we need to deploy to app engine):
git submobule init git submodule update
This is a Python google app engine application. We deploy in the usual way. Specifically,
# ./google_appengine is the location of your python SDK # if this is somewhere else amend the pathes accordingly cd ./google_appengine # now deploy ./appcfg.py update ../dataproxy/
- Downloading a range in a single sheet (add
range=A1:K3to the URL) [a bit nasty for CSV files but will do I think] - Choosing a limited set of rows within the sheet (add
row=5&row=7&row_range=10:100000:5000- rowrange format would be give me a row between 10 and 100000 every 5000 rows)
- Some data sets are not in text-based formats => Don't handle them at this stage
- Some data sets are huge => don't proxy more than 100K of data - up to the user to filter it down if needed
- Some applications might be wildly popular and put strain on the system -> perhaps API keys and rate limiting are needed so that individual apps/feeds can be disabled.