
👉 Ver todas las notas
- Base de Datos
- Qué problema resuelven las bases de datos
- Conceptos
- Bases de Datos Relacionales (SQL) vs No Relacionales (NoSQL)
- ORMs
- SQL
- PostgreSQL
Una base de datos es un conjunto de datos relacionados entre si y almacenados sistemáticamente (agrupados o estructurados de cierta forma) para facilitar su posterior uso.
Nos permiten guardar grandes cantidades de información de forma organizada, para que luego podamos encontrarla y utilizarla más fácilmente.
Una base de datos nos permite tener persistencia en los datos.
Para más detalles, ver Database - Wikipedia
Tenemos datos que necesitamos almacenar, que pueden ser de diferentes tipos (como datos de clientes, información sobre un producto, nombres, fechas de nacimiento, cantidades, etc). Pero el problema no pasa por tener datos en si, este no es un motivo suficiente para necesitar usar una base de datos. Los problemas que enfrentamos son los siguientes:
- tamaño: la cantidad de datos que tenemos que manejar puede ir creciendo con el tiempo
- facilidad de actualización de los datos: qué pasaría si, por ejemplo, 2 personas quieren editar datos a la vez?
- precisión: hay algo que prevenga que ingresemos datos con el formato incorrecto?
- seguridad: quién puede acceder a estos datos? cómo controlamos el acceso y diferentes permisos o privilegios?
- redundancia: la duplicación de datos genera conflictos, cómo sabemos cuál es el correcto?
- importancia: no queremos perder datos ni el trabajo realizado frente a imprevistos

👉 Una base de datos nos da una estructura y nos permite setear un conjunto de reglas sobre los datos que guardamos. A través de una base de datos, podemos almacenar, manipular y obtener datos.
Una base de datos relacional es una colección de 1 o más tablas (de 2 dimensiones), relacionadas entre sí.
También se conoce a las bases de datos relacionales, más coloquialmente, como Bases de Datos SQL, aunque es más correcto llamarlas relacionales, dado que hay DBs que utilizan otros lenguajes aparte de SQL para realizar consultas.
Organizamos los datos en tablas. Las tablas forman los bloques fundamentales de los que se compone una DB.
👉 Para una guía visual, ver A Shelfish Starter Guide to Databases.
Cada tabla contiene filas y columnas, que a su vez contienen datos. En las tablas definimos la estructura y los tipos de datos que estas van a almacenar, al definir las columnas de las mismas.
Cada columna le da un nombre y un tipo (texto, numérico, fecha, etc.) al dato almacenado y cada fila (registro) debe seguir esta estructura.
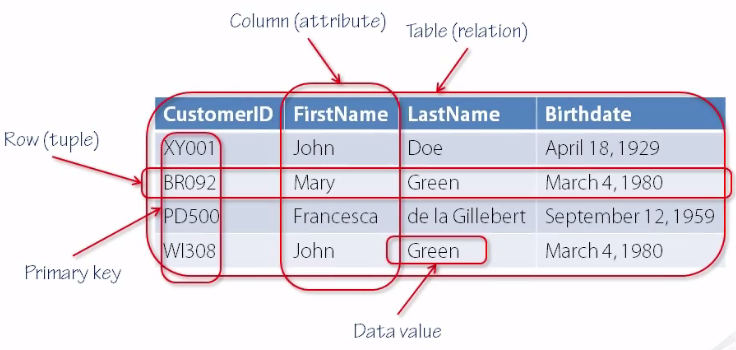
👉 Al definir las columnas de una tabla, estamos estableciendo reglas sobre los datos que contiene una tabla, que el DBMS se encargará de hacer cumplir.
Los datos de las diferentes tablas pueden estar, como dijimos antes, relacionados entre sí (de ahí el nombre de bases de datos relacionales).
👉 Las tablas y sus columnas deben definirse de antemano, antes de poder cargar datos en la DB.
Vamos a llamar registro (record) a cada una de las filas de una tabla, que representan una unidad de información.
La forma y organización de los datos dentro de una base de datos, se conoce como schema. Representa la colección y asociación de tablas.
👉 En una base de datos relacional, el schema debe definirse antes de poder interactuar con la misma. Todos los registros de una base de datos relacional deben seguir el esquema definido.
En bases de datos relacionales como Postgres, tenemos que especificar el tipo de datos que vamos a almacenar en un determinado campo. Algunos de los tipos de datos que nos provee Postgres son:
SERIAL: entero auto-incrementable, usualmente utilizado para IDs.TEXT: fragmentos de texto (muy similar aVARCHAR).VARCHAR: caracteres de longitud variable.CHAR: caracteres de longitud fija.BOOLEAN: un booleano.INTEGER: un entero.REAL: un número de punto flotante (por ejemplo,3.141593).DECIMAL, NUMERIC: valores numéricos de punto flotante con una precisión definida.DATE: para almacenar fechas.MONEY: valores numéricos de punto flotante para representar dinero.ARRAY: un array de otros datos (poco usual).
Para leer sobre la diferencia entre los tipos TEXT, VARCHAR y CHAR, ver este post de StackOverflow.
Para más detalles, ver PostgreSQL Data Types
Las constraints son ciertas restricciones aplicadas sobre una tabla, creadas implícita o explícitamente por el schema. Constraints son una parte clave del DDL.
👉 Violar una constraint va a generar un error de parte de la base de datos y (generalmente) abortar la operación.
Establece que al crear o actualizar un registro, el valor de un campo no puede ser NULL.
CREATE TABLE college_students (
id SERIAL PRIMARY KEY,
last_name VARCHAR(50),
first_name VARCHAR(50),
major VARCHAR(50) NOT NULL
);Establece que el valor de un campo para un registro debe ser único en la tabla.
CREATE TABLE phonebook (
id SERIAL PRIMARY KEY,
last_name VARCHAR(50),
first_name VARCHAR(50),
phone_number VARCHAR(7) UNIQUE
);Una Primary Key identifica un registro, el cual tiene a su vez, la propiedad de ser tanto UNIQUE como NOT NULL.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
first_name TEXT,
last_name TEXT
);Asocia los datos de una columna a los de otra columna, en una tabla diferente.
👉 La base de datos se asegura de que los datos de la Foreign key existan en la tabla que la Foreign Key referencia.
CREATE TABLE people (
id SERIAL PRIMARY KEY,
first_name TEXT,
last_name TEXT
);
CREATE TABLE interests (
id SERIAL PRIMARY KEY,
interest TEXT,
people_id INTEGER REFERENCES people
);En el ejemplo anterior, los valores de la columna people_id referencian al id de la tabla people.
Recibe una expresión que debe evaluar a true para que la operación se concrete.
CREATE TABLE products (
product_no SERIAL PRIMARY KEY,
name TEXT,
price NUMERIC CHECK (price > 0)
);- datos organizados en tablas, relacionadas entre sí
- schema estricto, definido al comienzo
- las columnas de cada tabla tienen tipos de datos definidos
Oracle, MySQL, PostgreSQL, MongoDB, etc. no son bases de datos en si, sino Database Management Systems (DBMS). Un DBMS es un software que utilizamos para crear y administrar bases de datos, permitiéndonos acceder a los datos de forma rápida y estructurada.
👉 Un DBMS puede administrar 1 o varias bases de datos.
En el caso de las bases de datos relacionales, utilizamos más específicamente, Relational Database Management Systems o RDBMS (subcategoría dentro de los DBMS). Los principios y conceptos que usaremos aplican para las diferentes variantes mencionadas anteriormente.
La mayoría de las bases de datos siguen la arquitectura cliente-servidor.
Es en el server donde se encuentran alojados los datos.
El server de la base de datos además, se encarga de correr el DBMS (Database Management System). A través de un cliente, nos conectamos al server de la DB, para crear nuestra base de datos e interactuar con ella.
Es un valor de una columna (o conjunto de columnas) que identifica unívocamente (1 y sólo 1) cada registro (o fila) de una tabla. Generalmente se corresponde con el campo id de la tabla.
👉 Toda tabla de una base de datos relacional debería tener definida una Primary Key.

Ver Primary Key
Se conocen como natural keys (claves naturales) a las Primary Keys que se generan a partir de los datos de una tabla.
Son valores de columnas naturalmente únicos, que tienen relación con el resto de las columnas de un registro dado. Por ejemplo, el email, número de seguridad social, número de pasaporte, ISBN, etc.
Se conocen como synthetic keys o surrogate keys (claves sustitutas) a las Primary Keys generadas por la base de datos al insertar un nuevo registro: estas no derivan de los datos de la tabla, es decir, es una columna extra que agregamos sólo con este propósito.
Se trata generalmente de valores numéricos, como pueden ser product_id o customer_id, etc.
Para más detalles, ver Natural Key vs Surrogate Key.
Es un valor o campo (o grupo de campos) que identifica unívocamente un registro (fila) de otra tabla, es decir, hace referencia a una columna de otra tabla que tenga la constraint UNIQUE (generalmente será una Primary Key).
El tipo de dato es indistinto, lo importante es que la columna que elijamos como Primary Key no contenga valores repetidos.
👉 Una tabla puede contener múltiples Foreign Keys, dependiendo de sus relaciones con otras tablas.

Ver Foreign Key
👉 Ver Bases de Datos - Relaciones.
Cuando necesitamos combinar datos de una (self join) o más tablas, utilizamos JOIN, basándonos en las columnas en común entre las tablas. Las columnas en común suelen ser la Primary Key de la primer tabla y la Foreign Key de la segunda tabla.


👉 Para ver la sintaxis y cómo escribir los diferentes tipos de joins, ver Bases de Datos - SQL (Joins).
👉 Para un resumen de los diferentes tipos de Joins, ver PostgreSQL Joins.

👉 Ver PostgreSQL INNER JOIN

👉 Ver PostgreSQL LEFT JOIN


👉 Ver PostgreSQL SELF JOIN
👉 Ver PostgreSQL CROSS JOIN
👉 Ver PostgreSQL UNION
Cuando buscamos datos en una tabla (SELECT, WHERE), la base de datos tiene que mirar registro por registro para encontrar aquellos que coincidan con los criterios especificados. Si tenemos un gran volumen de datos, esta operación puede ser muy lenta.
Para solucionar este problema existen los índices, que permiten que nuestras queries sean rápidas y eficientes, mejorando en consecuencia la performance.
Podemos indexar tablas por 1 o más columnas. Una tabla puede tener más de un índice.
⚠️ Agregar índices a una DB requiere espacio extra de almacenamiento (espacio en disco), aparte del espacio necesario para almacenar los datos. Además, cada vez que agreguemos un nuevo registro a una tabla, se actualizarán los índices correspondientes, haciendo esta operación más costosa. Por lo tanto, hay que utilizarlos con la precaución y planificación necesaria.
- cuando tenemos más operaciones de lectura que de escritura
- espacio en disco suficiente
- alta cardinalidad de un atributo (como PKs)
- alta frecuencia de búsqueda/filtrado/ordenamiento
Una transacción es una unidad combinada de trabajo, una serie de pasos que debemos ejecutar en cierto orden y que se considera exitosa si y sólo si todos los pasos se ejecutan correctamente. Si algún paso falla, la transacción entera se cancela y se revierten todos los pasos individuales, volviendo al estado original, previo a la operación.
👉 Ver PostgreSQL Transaction y más detalles en la documentación de Postgres
Es un acrónimo que define qué características debe cumplir una transacción, para garantizar la integridad, consistencia y seguridad de los datos durante una operación.
- A: Atómica (atomic). Se refiere a que es una unidad de trabajo indivisible (aunque hoy en día sabemos que los átomos pueden dividirse pero quedó el nombre), la transacción se realiza completa o se revierte.
- C: Consistente (consistent). Significa que cualquier transacción debe llevar a la db de un estado válido a otro estado válido (los estados intermedios no son visibles), según las reglas definidas por el DBMS.
- I: Aislada (isolated). Durante una transacción, los datos involucrados se encuentran aislados, no pudiendo ser accedidos y/o modificados por otra operación.
- D: Persistente (durable). Si la transacción se realiza de forma exitosa, debe estar garantizada su persistencia en la db (por ejemplo, si inmediatamente ocurre algún error después).
(WIP)
(WIP)
Para un resumen de las diferencias, ver SQL vs NoSQL or MySQL vs MongoDB
Los ORMs (Object Relational Mapping) nos permiten mapear entidades de bases de datos (relacionales) a objetos nativos del lenguaje que estemos utilizando en el backend (por ejemplo JS con Node).
Introducen una capa intermedia entre la db y el código del backend (data layer), que se encarga de realizar esta conversión por nosotros y nos permite interactuar con la DB a través de los objetos y métodos que nos provee.
- Siempre trabajamos con objetos nativos del lenguaje
- Reduce la cantidad de código que tenemos que escribir (principalmente las queries)
- Ahorra trabajo repetitivo
- Facilita el testing
- Es una capa más de abstracción
- Agrega más conceptos para aprender
- Tenemos menos control
- Algunas queries se complejizan bastante
- Dificulta entender la lógica detrás de las operaciones que estamos realizando
- Dificulta el mantenimiento (por ejemplo compatibilidad con diferentes DMBS) y debugging
- Impacto en la performance de las operaciones vs raw SQL
Es el lenguaje que vamos a utilizar para hacer consultas e interactuar con una base de datos relacional.
👉 Ver notas de SQL.
PostgreSQL, también conocido como Postgres a secas, es un RDBMS para bases de datos relacionales, de propósito general, open-source y gratuito, tanto para uso personal como comercial. Se trata también de una de las bases de datos relacionales más avanzadas y populares que existen.
Provee soporte para la mayor parte del standard SQL y agrega algunas features propias (incluso podemos utilizar JavaScript para crear funciones custom).
Al tratarse de una base de datos relacional, vamos a urilizar SQL para realizar queries con los datos almacenados en esta.
Lo más fácil es ir a la sección de descargas de PostgreSQL y descargar el instalador interactivo correspondiente a nuestro Sistema Operativo.
En el caso de OS X, podemos usar homebrew para instalarlo:
brew install postgresqly luego iniciar el servicio como daemon, es decir, que se quede corriendo de fondo, escuchando en el puerto default
brew services start postgresqlPara actualizar, hacemos
brew upgrade postgresql
brew postgresql-upgrade-database
brew services restart postgresql👉 Para más detalles, ver PostgreSQL (Postgres) - Installation & Overview.
1 Ver Cuándo usar UNION.