Implementation of "Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning"
To train the model require GPU with 12GB Memory, if you do not have GPU, you can directly use the pretrained model for inference.
This code is written in Lua and requires Torch. The preprocssinng code is in Python, and you need to install NLTK if you want to use NLTK to tokenize the caption.
You also need to install the following package in order to sucessfully run the code.
The pre-trained model for COCO can be download here. The pre-trained model for Flickr30K can be download here.
Download the corresponding Vocabulary file for COCO and Flickr30k
The first thing you need to do is to download the data and do some preprocessing. Head over to the data/ folder and run the correspodning ipython script. It will download, preprocess and generate coco_raw.json.
Download COCO and Flickr30k image dataset, extract the image and put under somewhere.

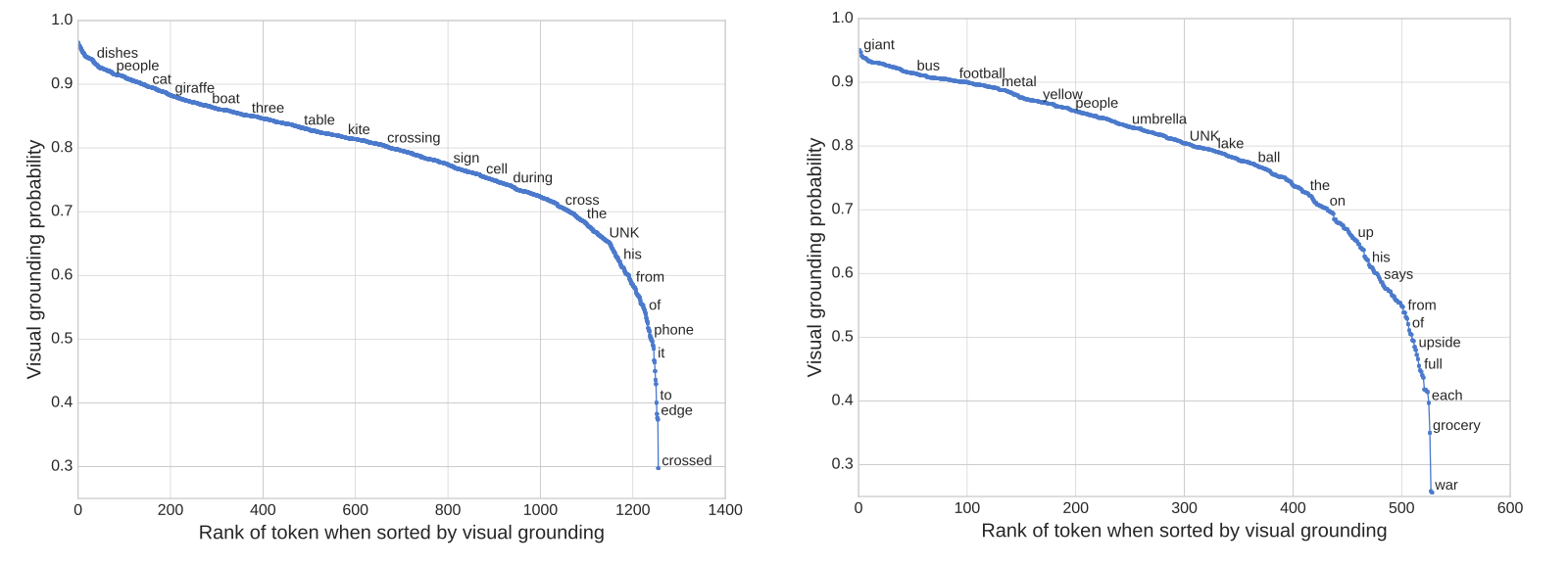
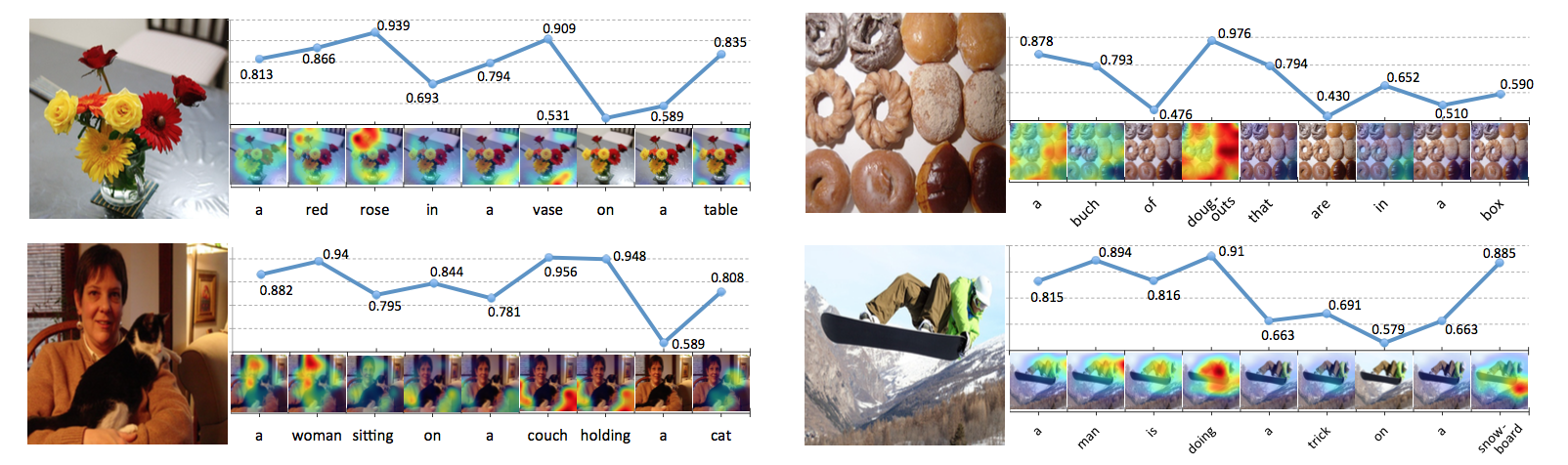
For more visualization result, you can visit here (it will load more than 1000 image and their result...)
If you use this code as part of any published research, please acknowledge the following paper
@misc{Lu2017Adaptive,
author = {Lu, Jiasen and Xiong, Caiming and Parikh, Devi and Socher, Richard},
title = {Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning},
journal = {CVPR},
year = {2017}
}
This code is developed based on NeuralTalk2.