Link production hosted on AWS EC2: http://ec2-54-87-20-150.compute-1.amazonaws.com:30000/
Conferences and conventions are hotspots for making connections. Professionals in attendance often share the same interests and can make valuable business and personal connections with one another. At the same time, these events draw a large crowd and it's often hard to make these connections in the midst of all of these events' excitement and energy. To help attendees make connections, we are building the infrastructure for a service that can inform attendees if they have attended the same booths and presentations at an event.
You work for a company that is building a app that uses location data from mobile devices. Your company has built a POC application to ingest location data named UdaTracker. This POC was built with the core functionality of ingesting location and identifying individuals who have shared a close geographic proximity.
Management loved the POC so now that there is buy-in, we want to enhance this application. You have been tasked to enhance the POC application into a MVP to handle the large volume of location data that will be ingested.
To do so, you will refactor this application into a microservice architecture using message passing techniques that you have learned in this course. It’s easy to get lost in the countless optimizations and changes that can be made: your priority should be to approach the task as an architect and refactor the application into microservices. File organization, code linting -- these are important but don’t affect the core functionality and can possibly be tagged as TODO’s for now!
- Flask - API webserver
- SQLAlchemy - Database ORM
- PostgreSQL - Relational database
- PostGIS - Spatial plug-in for PostgreSQL enabling geographic queries]
- Vagrant - Tool for managing virtual deployed environments
- VirtualBox - Hypervisor allowing you to run multiple operating systems
- K3s - Lightweight distribution of K8s to easily develop against a local cluster

The project has been set up such that you should be able to have the project up and running with Kubernetes.
We will be installing the tools that we'll need to use for getting our environment set up properly.
- Install Docker
- Set up a DockerHub account
- Set up
kubectl - Install VirtualBox with at least version 6.0
- Install Vagrant with at least version 2.0
To run the application, you will need a K8s cluster running locally and to interface with it via kubectl. We will be using Vagrant with VirtualBox to run K3s.
In this project's root, run vagrant up.
$ vagrant upThe command will take a while and will leverage VirtualBox to load an openSUSE OS and automatically install K3s. When we are taking a break from development, we can run vagrant suspend to conserve some ouf our system's resources and vagrant resume when we want to bring our resources back up. Some useful vagrant commands can be found in this cheatsheet.
After vagrant up is done, you will SSH into the Vagrant environment and retrieve the Kubernetes config file used by kubectl. We want to copy the contents of this file into our local environment so that kubectl knows how to communicate with the K3s cluster.
$ vagrant sshYou will now be connected inside of the virtual OS. Run sudo cat /etc/rancher/k3s/k3s.yaml to print out the contents of the file. You should see output similar to the one that I've shown below. Note that the output below is just for your reference: every configuration is unique and you should NOT copy the output I have below.
Copy the contents from the output issued from your own command into your clipboard -- we will be pasting it somewhere soon!
$ sudo cat /etc/rancher/k3s/k3s.yaml
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUJWekNCL3FBREFnRUNBZ0VBTUFvR0NDcUdTTTQ5QkFNQ01DTXhJVEFmQmdOVkJBTU1HR3N6Y3kxelpYSjIKWlhJdFkyRkFNVFU1T1RrNE9EYzFNekFlRncweU1EQTVNVE13T1RFNU1UTmFGdzB6TURBNU1URXdPVEU1TVROYQpNQ014SVRBZkJnTlZCQU1NR0dzemN5MXpaWEoyWlhJdFkyRkFNVFU1T1RrNE9EYzFNekJaTUJNR0J5cUdTTTQ5CkFnRUdDQ3FHU000OUF3RUhBMElBQk9rc2IvV1FEVVVXczJacUlJWlF4alN2MHFseE9rZXdvRWdBMGtSN2gzZHEKUzFhRjN3L3pnZ0FNNEZNOU1jbFBSMW1sNXZINUVsZUFOV0VTQWRZUnhJeWpJekFoTUE0R0ExVWREd0VCL3dRRQpBd0lDcERBUEJnTlZIUk1CQWY4RUJUQURBUUgvTUFvR0NDcUdTTTQ5QkFNQ0EwZ0FNRVVDSVFERjczbWZ4YXBwCmZNS2RnMTF1dCswd3BXcWQvMk5pWE9HL0RvZUo0SnpOYlFJZ1JPcnlvRXMrMnFKUkZ5WC8xQmIydnoyZXpwOHkKZ1dKMkxNYUxrMGJzNXcwPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
server: https://127.0.0.1:6443
name: default
contexts:
- context:
cluster: default
user: default
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: default
user:
password: 485084ed2cc05d84494d5893160836c9
username: adminType exit to exit the virtual OS and you will find yourself back in your computer's session. Create the file (or replace if it already exists) ~/.kube/config and paste the contents of the k3s.yaml output here.
Afterwards, you can test that kubectl works by running a command like kubectl describe services. It should not return any errors.
kubectl apply -f deployment/configmaps/- Set up environment variables for the podskubectl apply -f deployment/secrets/- Set up secrets for the podskubectl apply -f deployment/postgres.yaml- Set up a Postgres database running PostGISsh scripts/run_db_command.sh <POD_NAME>- Seed your database against thepostgrespod. (kubectl get podswill give you thePOD_NAME)kubectl apply -f deployment/udaconnect-api.yaml- Set up the service and deployment for the APIkubectl apply -f deployment/udaconnect-app.yaml- Set up the service and deployment for the web appkubectl apply -f deployment/udaconnect-persons-api.yaml- Set up the service and deployment for the Persons APIkubectl apply -f deployment/udaconnect-connections-api.yaml- Set up the service and deployment for the Connections API- Setup the messaging queue as follows
# Install helm on the guest VM curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 chmod 700 get_helm.sh ./get_helm.sh helm repo add bitnami https://charts.bitnami.com/bitnami helm install udaconnect-kafka bitnami/kafka # verify the installation kubectl get pods # Wait until 'kafka-0' pod is in the running state, then run the following commands # Get the pod name for the kafka container export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=kafka,app.kubernetes.io/instance=udaconnect-kafka,app.kubernetes.io/component=kafka" -o jsonpath="{.items[0].metadata.name}") export BOOTSTRAP_SERVER=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=kafka,app.kubernetes.io/instance=udaconnect-kafka,app.kubernetes.io/component=kafka" -o jsonpath="{.items[0].spec.subdomain}") # Set the topic name export TOPIC="location-data" # Create topic kubectl exec -it $POD_NAME -- kafka-topics.sh \ --create --bootstrap-server $BOOTSTRAP_SERVER:9092 \ --replication-factor 1 --partitions 1 \ --topic $TOPIC
kubectl apply -f deployment/udaconnect-location-consumer.yaml- Set up the location consumer servicekubectl apply -f deployment/udaconnect-location-producer.yaml- Set up the location producer service
Manually applying each of the individual yaml files is cumbersome but going through each step provides some context on the content of the starter project. In practice, we would have reduced the number of steps by running the command against a directory to apply of the contents: kubectl apply -f deployment/.
Note: The first time you run this project, you will need to seed the database with dummy data. Use the command sh scripts/run_db_command.sh <POD_NAME> against the postgres pod. (kubectl get pods will give you the POD_NAME). Subsequent runs of kubectl apply for making changes to deployments or services shouldn't require you to seed the database again!
Once the project is up and running, you should be able to see 9 deployments and 9+ services in Kubernetes:
-
kubectl get podsshould return a list similar to the image below: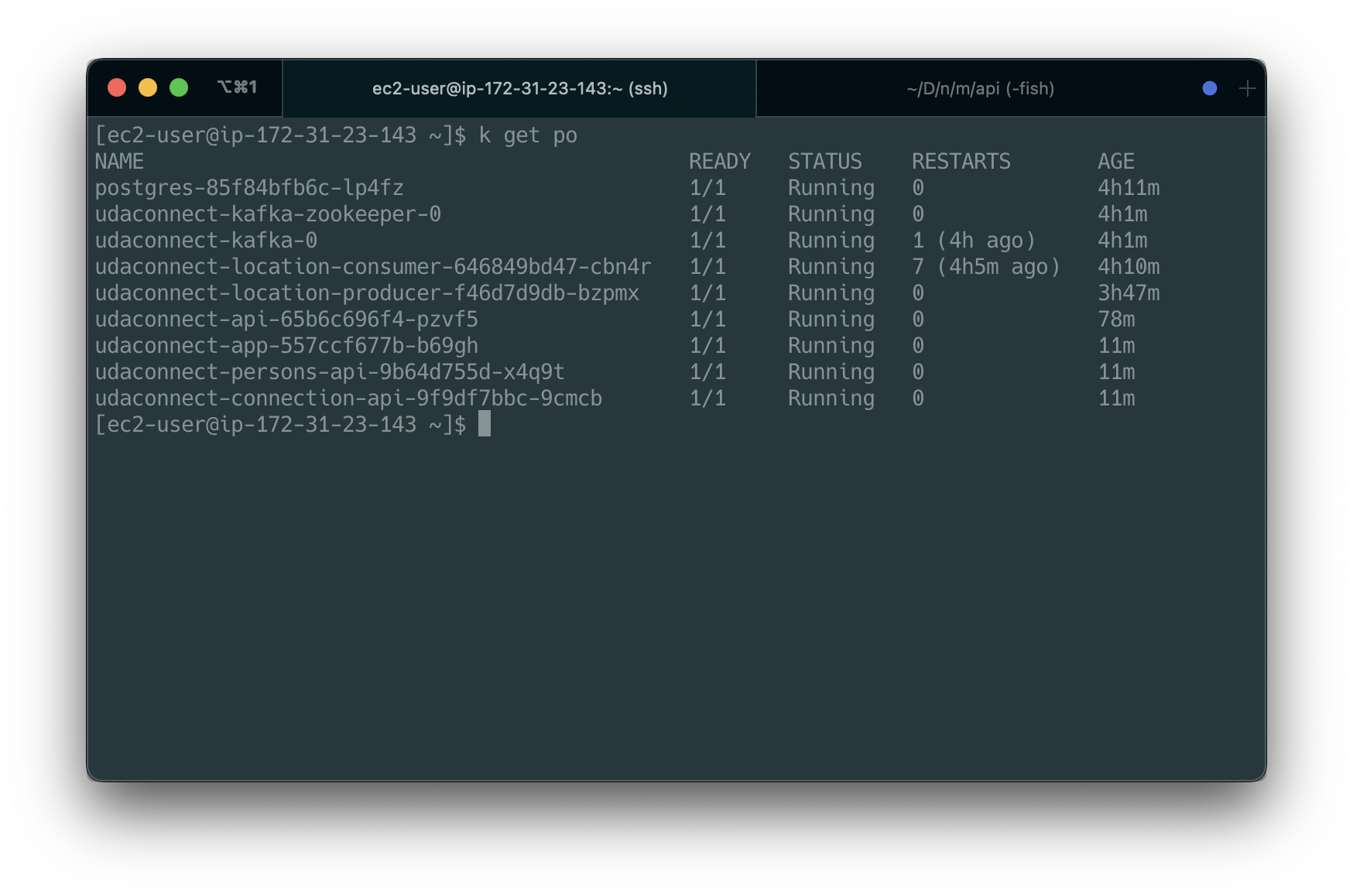
-
kubectl get servicesshould return a list similar to the image below: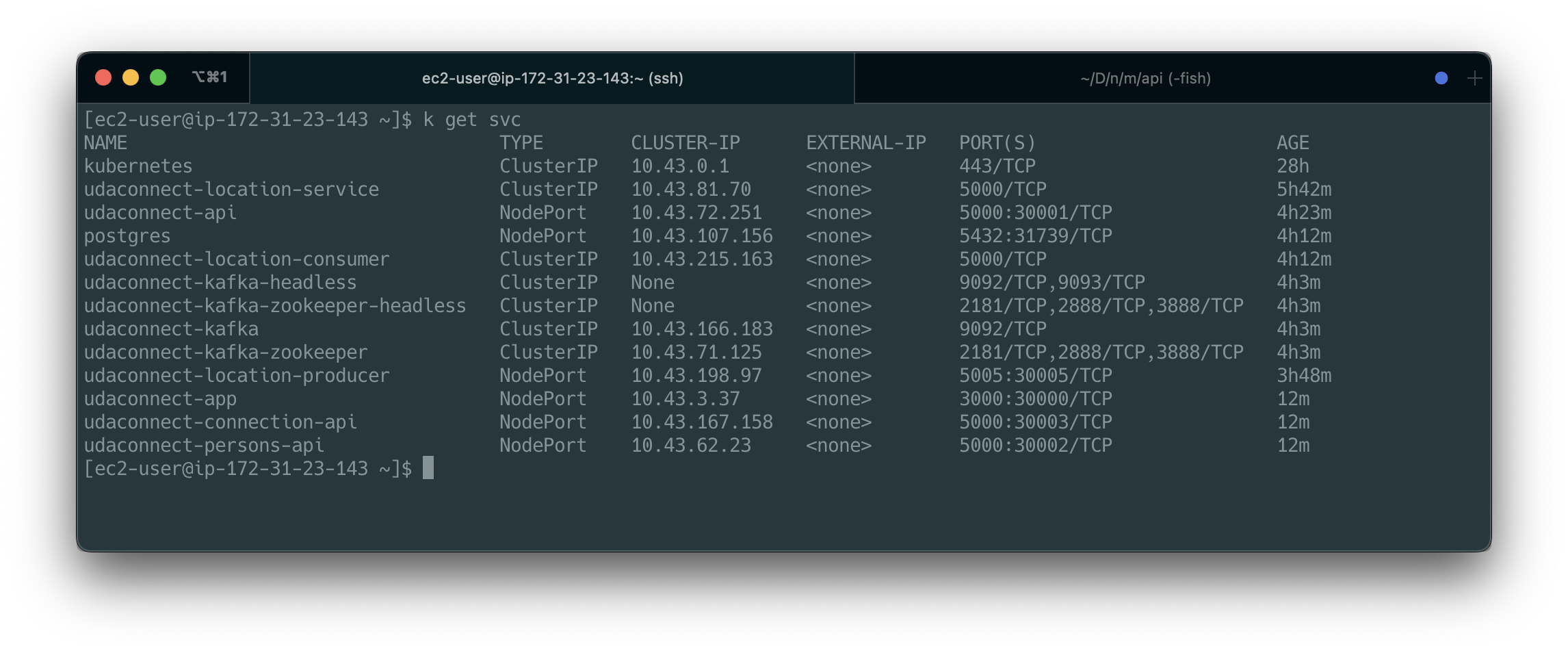


These pages should also load on your web browser:
http://locahost:30001/- OpenAPI Documentationhttp://locahost:30001/api/- Base path for APIhttp://locahost:30002/- OpenAPI Documentation for Person APIhttp://locahost:30002/api/persons- Base path for Person APIhttp://locahost:30003/- OpenAPI Documentation for Connection APIhttp://locahost:30003/api//persons/<person_id>/connection- Base path for Connection APIhttp://locahost:30000/- Frontend ReactJS Application
You can see it on production:
http://ec2-54-87-20-150.compute-1.amazonaws.com:30001/- OpenAPI Documentationhttp://ec2-54-87-20-150.compute-1.amazonaws.com:30001/api/- Base path for APIhttp://ec2-54-87-20-150.compute-1.amazonaws.com:30002/- OpenAPI Documentation for Person APIhttp://ec2-54-87-20-150.compute-1.amazonaws.com:30002/api/persons- Base path for Person APIhttp://ec2-54-87-20-150.compute-1.amazonaws.com:30003/- OpenAPI Documentation for Connection APIhttp://ec2-54-87-20-150.compute-1.amazonaws.com:30003/api//persons/<person_id>/connection- Base path for Connection APIhttp://ec2-54-87-20-150.compute-1.amazonaws.com:30000/- Frontend ReactJS Application
You may notice the odd port numbers being served to localhost. By default, Kubernetes services are only exposed to one another in an internal network. This means that udaconnect-app and udaconnect-api can talk to one another. For us to connect to the cluster as an "outsider", we need to a way to expose these services to localhost.
Connections to the Kubernetes services have been set up through a NodePort. (While we would use a technology like an Ingress Controller to expose our Kubernetes services in deployment, a NodePort will suffice for development.)
New services can be created inside of the modules/ subfolder. You can choose to write something new with Flask, copy and rework the modules/api service into something new, or just create a very simple Python application.
As a reminder, each module should have:
Dockerfile- Its own corresponding DockerHub repository
requirements.txtforpippackages__init__.py
udaconnect-app and udaconnect-api use docker images from udacity/nd064-udaconnect-app and udacity/nd064-udaconnect-api. To make changes to the application, build your own Docker image and push it to your own DockerHub repository. Replace the existing container registry path with your own.
In deployment/db-secret.yaml, the secret variable is d293aW1zb3NlY3VyZQ==. The value is simply encoded and not encrypted -- this is not secure! Anyone can decode it to see what it is.
# Decodes the value into plaintext
echo "d293aW1zb3NlY3VyZQ==" | base64 -d
# Encodes the value to base64 encoding. K8s expects your secrets passed in with base64
echo "hotdogsfordinner" | base64This is okay for development against an exclusively local environment and we want to keep the setup simple so that you can focus on the project tasks. However, in practice we should not commit our code with secret values into our repository. A CI/CD pipeline can help prevent that.
The database uses a plug-in named PostGIS that supports geographic queries. It introduces GEOMETRY types and functions that we leverage to calculate distance between ST_POINT's which represent latitude and longitude.
You may find it helpful to be able to connect to the database. In general, most of the database complexity is abstracted from you. The Docker container in the starter should be configured with PostGIS. Seed scripts are provided to set up the database table and some rows.
While the Kubernetes service for postgres is running (you can use kubectl get services to check), you can expose the service to connect locally:
kubectl port-forward svc/postgres 5432:5432This will enable you to connect to the database at localhost. You should then be able to connect to postgresql://localhost:5432/geoconnections. This is assuming you use the built-in values in the deployment config map.
To manually connect to the database, you will need software compatible with PostgreSQL.
- CLI users will find psql to be the industry standard.
- GUI users will find pgAdmin to be a popular open-source solution.
- We can access a running Docker container using
kubectl exec -it <pod_id> sh. From there, we cancurlan endpoint to debug network issues. - The starter project uses Python Flask. Flask doesn't work well with
asyncioout-of-the-box. Consider usingmultiprocessingto create threads for asynchronous behavior in a standard Flask application.