Microservicio de alto rendimiento para consultar la información del centro de votación de un ciudadano en unas elecciones españolas.
Agradecimientos especiales a:
- Ajuntament de Sant Vicenç dels Horts por financiar este desarrollo.
- Jesus Gomiz Gálvez del Ajuntament de Rubí por su apoyo en proporcionar el formato del Censo Electoral extraído del Instituto Nacional de Estadística para los ayuntamientos.
- Miquel Estapé Valls del Consorci AOC por sus consejos en materia de seguridad y protección de datos sobre WhatsApp y Telegram.
TL;TR
docker run -d -p 8080:8080 -v /ruta/a/censo:/data -e TOKEN=12345 harbor.videoatencion.com/library/censo-electoral:latestEste microservicio analiza un archivo CSV descargado del INE. Extrae solo la información de parte del DNI, parte de la fecha de nacimiento para minimizar los datos requeridos (cumplimiento LOPD/GDPR) y los datos del Centro de votación, y crea una base de datos Sqlite con esta información. Una vez analizado, el CSV original es eliminado para que no se pueda obtener información adicional de él.
Si el servicio se reinicia, buscará un nuevo CSV. Si hay uno nuevo, reconstruirá la base de datos con los nuevos datos. Si no hay un nuevo CSV y existe la base de datos, iniciará el servicio.
El microservicio se ha probado en un hardware doméstico con un rendimiento excelente:
Tamaño de la base de datos: 3.000.000
Solicitudes paralelas: 25
Solicitudes por segundo: 624
CPUs utilizadas: 0.4
Por lo tanto, puede determinar el centro de votación a una tasa de 2,24 millones de solicitudes por hora con menos de 1 CPU y 128 MB de RAM.
- Descargue el censo del INE.
- En "Generar Fichero" deje todas las opciones en "Todos" y Ámbito Censal en "CER y CERE".
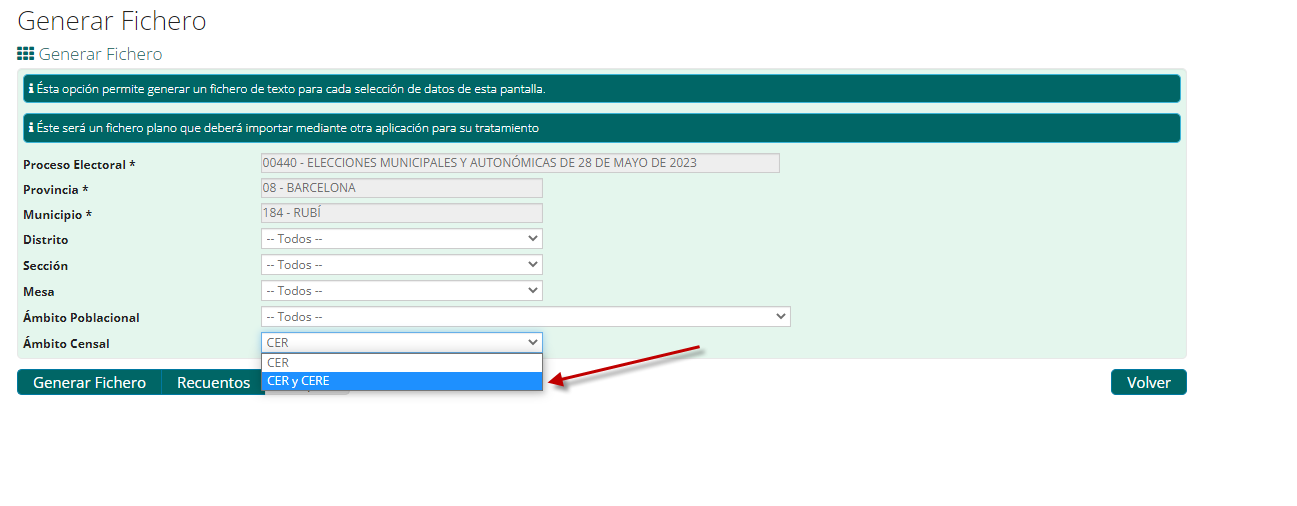
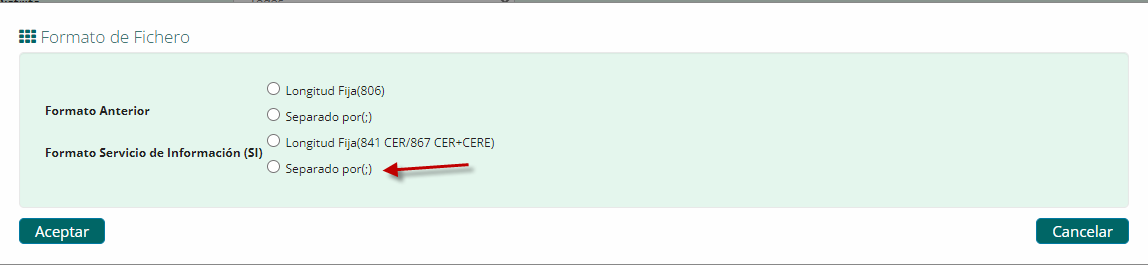
- Seleccione "Formato Servicio de Información (SI)" Separado por (;)


El formato del archivo exportado tiene este aspecto:
"NIE";"CPRO";"LMUN";"DIST";"SECC";"MESA";"NLOCAL";"NLOCALB";"INFADICIONAL";"DIRMESA1";"DIRMESA2";"DIRMESA3";"DIRMESA4";"NOMBRE";"APE1";"APE2";"DOMI1";"DOMI2";"DOMI3";"ENTI1";"ENTI2";"ENTI3";"CPOSTAL";"CPRON";"CNMUN";"FNAC";"SEXO";"IDENT";"CPOSTAM";"NIA";"GESCO";"NORDEN";"NACIONALIDAD";"INTENCIONVOTO";
- Coloque ese archivo en una carpeta sin más archivos. La extensión debe de ser .txt o .csv.
-
Construya su docker:
docker build . -t censo:latest
-
Ejecute el servicio:
docker run -e TOKEN=12345 -v /ruta/al/directorio/del/censo:/data -p 8080:8080 -d censo:latest o docker run -d -e TOKEN=12345 -e DOCUMENT_CHARS=5 -e FIRST_CHARS=true -e FIRST_CHARS_ADD_LETTER=true -e NAME_CHARS=2 -e DAY=true -e YEAR=true -e FN=true -e SN1=true -e SN2=false -e POST_CODE=false -v /data:/data harbor.videoatencion.com/library/censo-electoral:latest
Si miráis los logs, se verá algo así:
2023/04/28 10:48:13 CSV import process: 21368 rows read, 21360 rows imported
2023/04/28 10:48:13 citizen_id+sn1 = 98.69%
2023/04/28 10:48:13 citizen_id+day = 98.38%
2023/04/28 10:48:13 citizen_id+fn = 98.12%
2023/04/28 10:48:13 citizen_id+year = 92.43%
2023/04/28 10:48:13 citizen_id = 70.74%
2023/04/28 10:48:13 citizen_id+sn2 = 70.74%
2023/04/28 10:48:13 citizen_id+postCode = 70.74%
2023/04/28 10:48:13 Citizens loaded in 324.35326ms
Aquí podemos ver que el proceso de importación ha funcionado sin colisiones, y el % de resoluciones que podemos esperar sólo consultando el documento de identidad o el documento y un campo adicional. Los 8 registros no importados han sido causados por filas con el campo del documento de identidad o la fecha de nacimiento vacías.
-
Pruebe su servicio
curl -H 'Authorization: 12345' -X POST http://127.0.0.1:8080/consulta -d '{ "citizenId": "0123A", "day": "31", "year", "91", "sn1": "AL", "sn2": "MA" }'
{"poblacion":"RUBÍ","distrito":"01","seccion":"001","mesa":"A","colele":"ESCOLA RAMON LLULL","dircol":"AV FLORS 43","errorMessage":""}Sólo citizenId es obligatorio, cualquier otro parámetro es opcional. Si se encuentra más de un resultado, el sistema retorna un mensaje como este:
{"errorMessage":"[day year sn2]"}Esto indica qué otros campos pueden pasarse para obtener un resultado único.

También se proporciona un archivo docker-compose.yml para construir e iniciar el servicio. Recuerde cambiar el TOKEN, la ruta a la carpeta donde se almacena el CSV y la base de datos, además habilite HTTPS para garantizar comunicaciones seguras.
En caso de detectar una colisión de entradas, el proceso abortará la importación. Puede controlarse qué se indexa mediante las siguientes variables de entorno:
- DOCUMENT_CHARS (default=5): cuantos caracteres extrae del documento de identidad
- NAME_CHARS (default=2): número de caracteres a indexar para nombre o apellidos
- FIRST_CHARS=true (default=false): lee el documento desde el principio (true) o desde el final (false)
- FIRST_CHARS_ADD_LETTER=true (default=false): añadir la letra del final del documento [ 12345678A -> 12345A ]
- DAY=true (default=true): activa dd
- YEAR=true (default=false): activa yy
- FN=true (default=false): activa nombre
- SN1=true (default=false): activa apellido1
- SN2=true (default=false): activa apellido2
Si desea actualizar la base de datos, simplemente copie el nuevo CSV en /data y reinicie/elimine el contenedor.
Si necesita ayuda, contáctenos en hola arroba videoatencion.com.
High performance Microservice to return the voting center information of a citizen in a Spanish election.
Special Thanks to:
- Ajuntament de Sant Vicenç for funding this development.
- Jesus Gomiz Galvez from Ajuntament de Rubí for his support in providing the format of Censo Electoral extracted from the Instituto Nacional de Estadística for the city councils.
- Miquel Estapé Valls from Consorci AOC for his advice in security and RGPD compliance on WhatsApp and Telegram.
TL;TR
docker run -d -p 8080:8080 -v /path/to/census:/data -e TOKEN=12345 harbor.videoatencion.com/library/censo-electoral:latestThis microservice parses a CSV file downloaded from INE. It extracts just part of the DNI and part of the Birth Date to minimize required data (GDPR compliance) plus the information of the Polling station, then it creates a Sqlite database with that information. Once parsed, the CSV is deleted so no additional information can be gathered from it.
If the service gets restarted, it will look for a new CSV. If there's a new one, it will rebuild the database with the new data. If there's no new CSV and a the database exists, it will start the service.
The microservice has been tested in commodity hardware with excellent performance:
Database size: 3.000.000
Parallel requests: 25
Requests per second: 624
CPUs used: 0.4
So, it can determine the polling station at a rate of 2.24M requests / hour with less than 1 CPU and 128MB of RAM.
- Download census from INE.
- In "Generar Fichero" leave all options as "Todos" and Ámbito Censal to "CER y CERE".
- Select "Formato Servicio de Información (SI)" Separado por (;)
The format will look like this:
"NIE";"CPRO";"LMUN";"DIST";"SECC";"MESA";"NLOCAL";"NLOCALB";"INFADICIONAL";"DIRMESA1";"DIRMESA2";"DIRMESA3";"DIRMESA4";"NOMBRE";"APE1";"APE2";"DOMI1";"DOMI2";"DOMI3";"ENTI1";"ENTI2";"ENTI3";"CPOSTAL";"CPRON";"CNMUN";"FNAC";"SEXO";"IDENT";"CPOSTAM";"NIA";"GESCO";"NORDEN";"NACIONALIDAD";"INTENCIONVOTO";
- Place that file in a folder without any other files. The extension must be .txt or .csv.
-
Build your docker:
docker build . -t censo:latest
-
Run your service:
docker run -e TOKEN=12345 -v /path/to/census/folder:/data -p 8080:8080 -d censo:latest or docker run -d -e TOKEN=12345 -e DOCUMENT_CHARS=5 -e FIRST_CHARS=true -e FIRST_CHARS_ADD_LETTER=true -e NAME_CHARS=2 -e DAY=true -e YEAR=true -e FN=true -e SN1=true -e SN2=false -e POST_CODE=false -v /data:/data harbor.videoatencion.com/library/censo-electoral:latest
If you check the logs you will see something like this:
2023/04/28 10:48:13 CSV import process: 21368 rows read, 21360 rows imported
2023/04/28 10:48:13 citizen_id+sn1 = 98.69%
2023/04/28 10:48:13 citizen_id+day = 98.38%
2023/04/28 10:48:13 citizen_id+fn = 98.12%
2023/04/28 10:48:13 citizen_id+year = 92.43%
2023/04/28 10:48:13 citizen_id = 70.74%
2023/04/28 10:48:13 citizen_id+sn2 = 70.74%
2023/04/28 10:48:13 citizen_id+postCode = 70.74%
2023/04/28 10:48:13 Citizens loaded in 324.35326ms
Here we can see that the import process worked, and what % of resolutions can we expect with just the citizenId or citizenId + an optional field. The 8 rows not imported are caused by rows with citizenId or birthDate empty.
-
Try your service:
curl -H 'Authorization: 12345' -X POST http://127.0.0.1:8080/consulta -d '{ "citizenId": "0123A", "day": "31", "year", "91", "sn1": "AL", "sn2": "MA" }'
{"poblacion":"RUBÍ","distrito":"01","seccion":"001","mesa":"A","colele":"ESCOLA RAMON LLULL","dircol":"AV FLORS 43","errorMessage":""}Only citizenId is mandatory, any other parameter is optional. If more than 1 record match, the system will return a message like this:
{"errorMessage":"[day year sn2]"}This indicates every possible field that could be used to get a single record
A docker-compose.yml is also provided to build and launch the service. Remember to change the TOKEN, the path to the folder storing the CSV and the database add enable HTTPS to ensure secure communications.
In case the system detects a collision, the process will abort import. You can control what is indexed with the following environment variables:
- DOCUMENT_CHARS (default=5): how many characters to extract from the CitizenID
- NAME_CHARS (default=2): define the number of characters to index for the firstname or the surnames
- FIRST_CHARS=true (default=false): read the CitizenId from the beginning (true) of from the end (false)
- FIRST_CHARS_ADD_LETTER=true (default=false): if we should append the letter at the end of the CitizenID to the string
- DAY=true (default=true): enable dd
- YEAR=true (default=false): enable yy
- FN=true (default=false): enable firstname
- SN1=true (default=false): enable lastname1
- SN2=true (default=false): enable lastname2
If you want to update the database, just copy the new CSV under /data and restart/delete the container.
If you need help, contact us at hola at videoatencion.com.