Implemented Map reduce jobs for processing SQL Queries on Amazon product reviews dataset available at https://s3.amazonaws.com/amazon-reviews-pds/readme.html


-
converted given unstructured data into 4 tables named
product,similar,category, andreview, using a script which reads given file line by line and using regular expressions parse it and creates csv files. Read script here -
Some entries from the tables
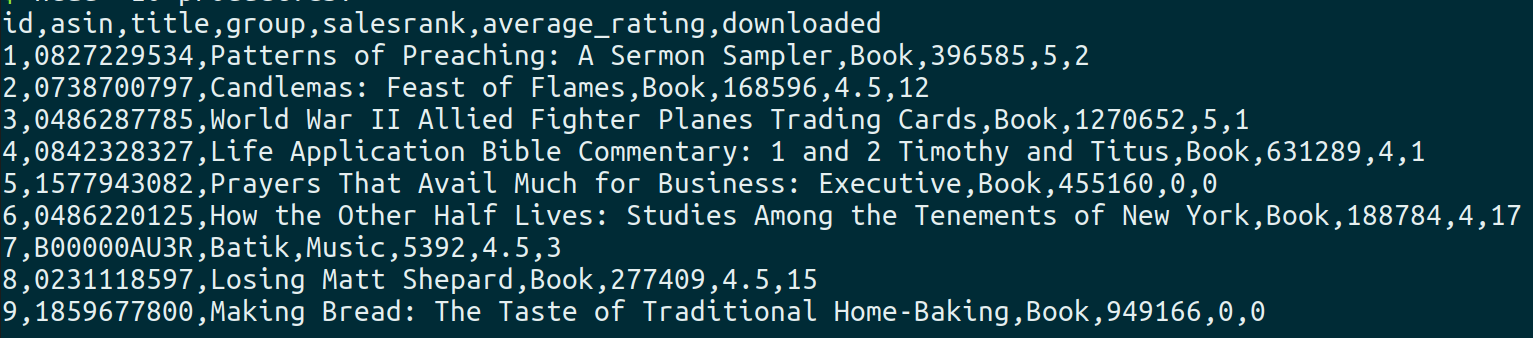
- Product
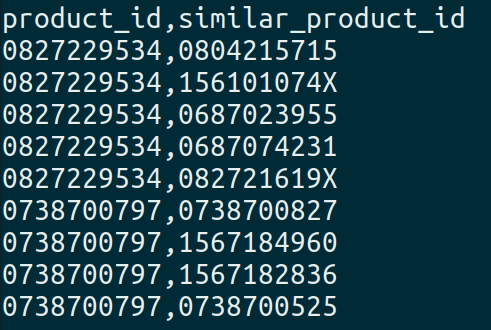
- Similar
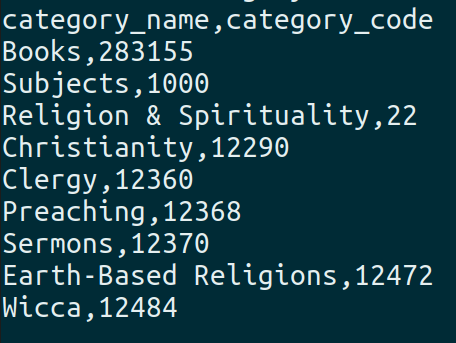
- Category
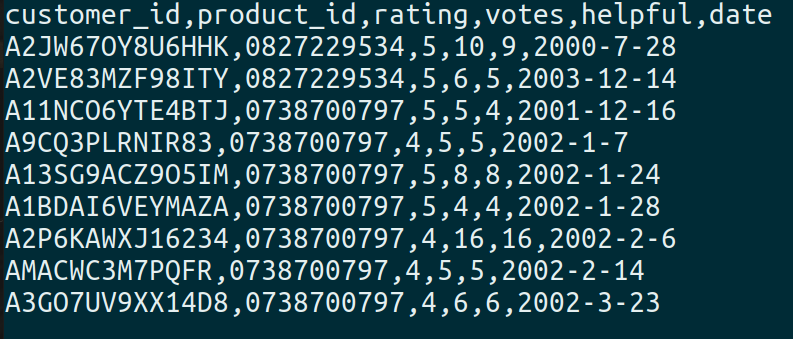
- Review
- Product
-
Then for hadoop program
- SQL query is parsed and a json object is constructed out of it which is accessed by mapper and reducer
- For query
select category_name, count(category_code) from category where category_name = 'Books' group by category_name having count(category_code) > 0, JSON generated is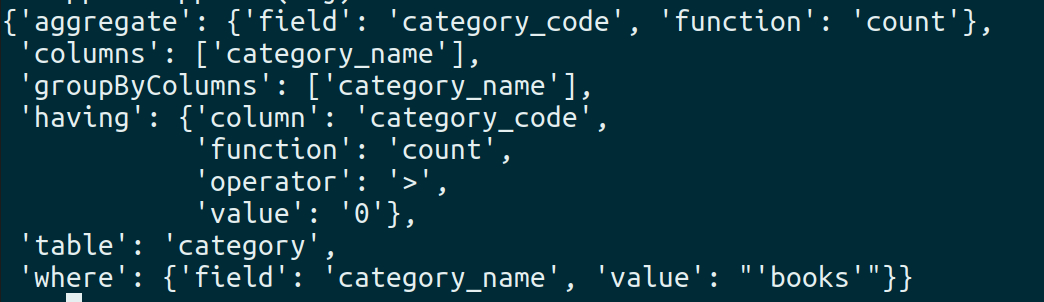
- The mapper uses this JSON to identify which rows satisfy WHERE condition, and it outputs all rows satisfying WHERE conditions as it is with key as the concatenation of values of columns present in group by clause
- Then reducer calculates aggregate condition and checks if that collection of rows satisfy that aggregate condition or not, if they do, it outputs all columns present in selct clause and aggregate column value, else it ignores it.
-
For Spark program
- the query is parsed and SparkSQL is used to run the query
-
Sample outputs of both programs for SQL query





select category_name, count(category_code) from category where category_name = Books group by category_name having count(category_code) > 0- Hadoop


select category_name, count(category_code) from category where category_name = 'Books' group by category_name having count(category_code) > 0- Spark

- Some Sample queries to try
select product_id, count(similar_product_id) from similar where product_id = 1559362022 group by product_id having count(similar_product_id) > 0
select category_name, count(category_code) from category where category_name = Books group by category_name having count(category_code) > 0
select asin, title, sum(downloaded) from product where asin = 0827229534 group by asin, title having sum(downloaded) > 0
select customer_id, max(rating) from review where customer_id = A2JW67OY8U6HHK group by customer_id having max(rating) > 0- For Hadoop, do not enclose strings in
'', but do it in spark - Before running the job, delete
data/outputfolder everytime
| Name | ID |
|---|---|
| Harpinder Jot Singh | 2017A7PS0057P |
| Vishal Mittal | 2017A7PS0080P |