This project builds a program that can play the original 1980 Atari Pacman. The approaches used are Deep-Q-Learning and Neuroevolution of Augmenting Topologies
Use the Makefile to run various parts of this project.
- NEAT
- Train -
make neat-train - Test -
make neat-test
- Train -
- DQN
- Train -
make rl-train - Test -
make rl-test
- Train -
- Q Learning Demo -
make q-learning
main.py usage
python3 main.py [algorithm] [train/test]Install the requirements with
pip install -r requirements.txtsudo make installAll files using NEAT are stored under NEAT/
Train the NEAT model:
make neat-trainTest the NEAT model:
make neat-testFor an explanation on a project using the same algorithm watch this video.
This program uses a mathematical model, called a neural network, which simulates the brain of a human being.
A neural network works by taking inputs and outputting probabilities for each of the outputs. This can be accomplished
by using a sigmoid function.
Neuroevolution of Augmenting Topologies, or NEAT is what this project uses. The way standard
neuroevolution works is by randomly initializing a population of neural networks and
using survival of the fittest to get the best model. The best networks in each generations
are bred and some mutations are introduced. NEAT introduces features like speciation to
make a much more effective neuroevolution model. Neuroevolution is known to do better than standard
reinforcement learning models.
All files using DQN are stored under DQN/
Train the DQN model:
make rl-trainTest the DQN model:
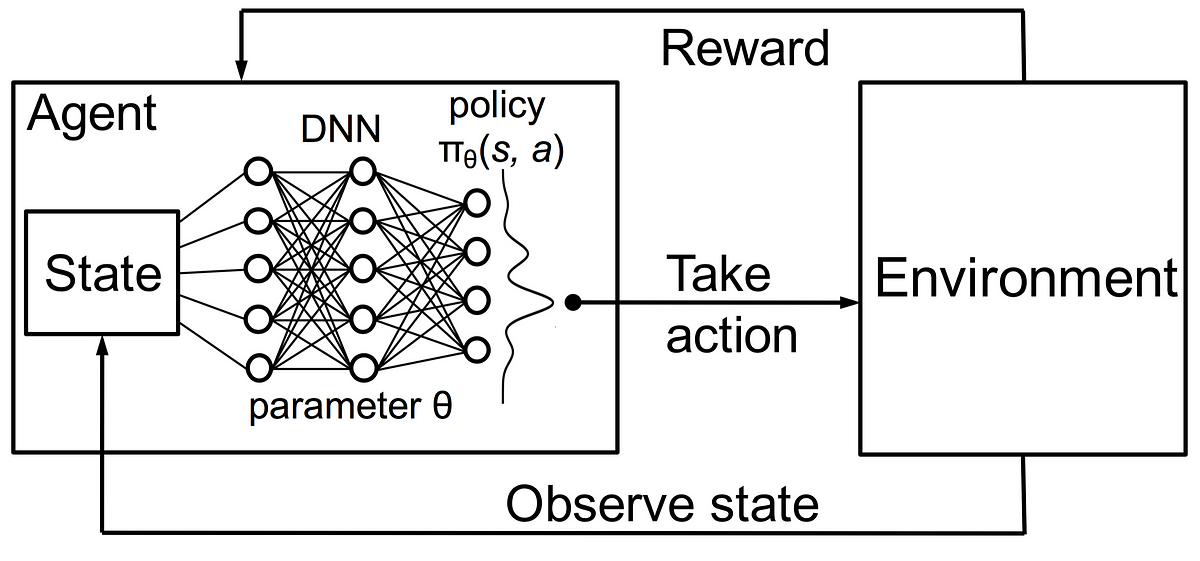
make rl-testQ-learning learns the action-value function Q(s, a): how good to take an action at a particular state. Here's what each term means:
-
state - The observation you take from the environment. In this case, it would be an image of the Pacman game or the RAM of the Atari console.
-
action - The program's output for this particular state. For example, an action would be to move left, up, right, or down in Pacman
-
reward - A reward is a number that tells how good or bad an episode was. In this case, the reward can be the score.
-
Q(s, a) - Q is called the action-value function. In Q Learning, we build an table, called the Q-Table for every state action pair. This Q Table helps determine what action to choose.

This kind of state-action-reward system where the next state depends on the
previous state is called Markov Decision Process.

Deep Q-learning is a special type of Q-Learning
where the Q-function is learnt by a deep neural network.
The input to the neural network is the state of the environment
and the outputs are the Q-Values.
The action with the maximum predicted Q-value is chosen as our action
to be taken in the environment.