Implementation of Linear Inverse Reinforcement Learning Algorithm (IRL) on Mountain Car Environment. Mainly for experimental & educational purposes.
- The concept of Reinforcement learning was developed based on the sole presupposition that
Reward functions are the most succinct, robust and transferable defination of a task.But, in cases like robotic manipulations and self driving cars, defining a reward function or hand-manifacturing a reward function become difficult or in some cases, almost impossible.
- The first LIRL algorithm was published in a paper Algorithms for IRL (Ng & Russel 2000) in which they proposed an iterative algorithm to extract the reward function given optimal/expert behavior policy for obtaining the goal in that particular environment.
- This code is an attempt to test IRL algorithm on Mountain Car environment given
mexpert trajectories. - Following Section 5 of IRL paper(Ng & Russel).


- Expert Policy Generation
- Used Q-learning algorithm with linear approximators to train the agent for generating expert policy.(This is done as it becomes difficult for humans to generate expert policies in Mountain Car)
- IRL implementation
- Given the best expert policy, IRL algorithm learns the best reward function for the agent and returns it to the agent.
- How good is the learnt reward function?
- Timesteps required to converge to the optimal solution.
- Using the learnt reward function, it was observed that the timesteps to learn were significantly less than the default reward function inbuilt in the Mountain car env.
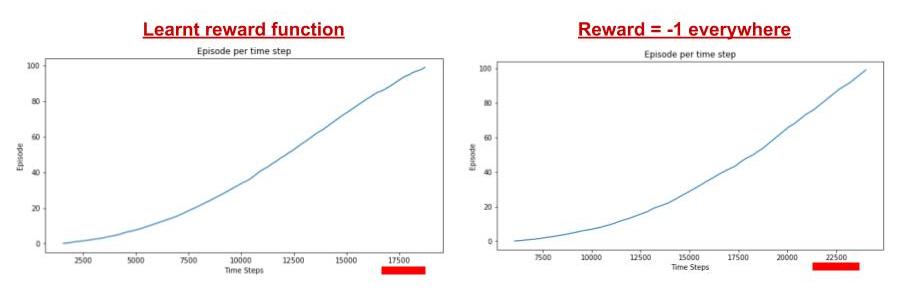
- Using the learnt reward function, it was observed that the timesteps to learn were significantly less than the default reward function inbuilt in the Mountain car env.
- Average reward after completion of task.
- There is a code block for generating results in the notebook which basically averages reward over 100 trajectories with random start position using the learnt policy based on: 1) Learnt reward function 2) Default reward function.
- Timesteps required to converge to the optimal solution.

git clonethe repository.- Execute the jupyter notebook code blocks in order.
- The notebook is explained in a very detailed manner for gaining deeper understanding into the code and results. Improvements and future work are desribed in the notebook.
- Scikit Learn
- Gym
- Scipy
- Numpy
- MatPlotLib
Install them using pip
Please feel free to create a Pull Request for adding implementations of the IRL algorithms and improvements. If you are a beginner, you can refer to this for getting started.
If you found this useful, please consider starring(★) the repo so that it can reach a broader audience.
This project is licensed under the MIT License - see the LICENSE file for details.