Creating user graphs to map user influence and subreddit graph to analyze similar subreddits. Project Presentation
The motivation behind this project was to use 2.5 TB of raw JSON data taken from the reddit API and create two large graphs, one of users and another of subreddits. The users are connected via submissions and comments. Reddit allows for users to post submissions on different subreddits and it allows for commenters to post on those submissions. The edges between users are created when one user comments on another users post. The edge is directed from the commenter to the submitter, this will create a directed graph. The subreddit graph is different, the edges represent the number of intersecting users. To be more specific, the edges represent the number of users two subreddits have in common and the weight of the edge is a number value representing the number of intersecting users. The final product will allow somebody to query a database and recieve information on user pagerank and similar subreddits.
The size of the total raw JSON data is 2.5 TB, the data is grouped in monthly batches. There are approximately 600,000 subreddits that exist to date and 234 million unique users every month (2017). The 2017 year averages about 40 million user interactions per month and on average since 2006 there have been 22 million user interactions every month.
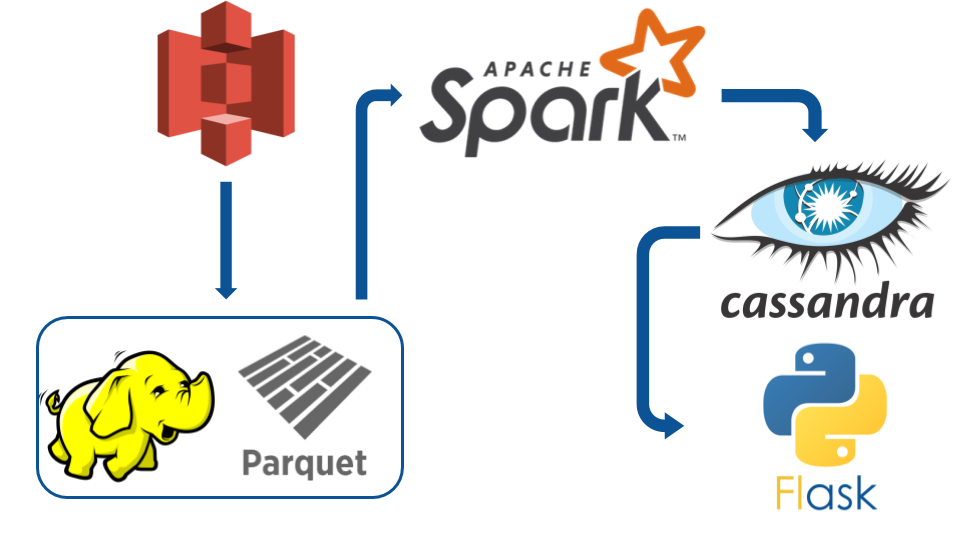
The raw data exists on S3 initially and it was stored there using the shell script in the ToS3 directory. The raw JSON on s3 is
pulled into Spark where feature extraction occurs and unimportant data is dropped, the final datasets are pushed to HDFS with parquet
file format. Parquet is a columnar storage format, it allows for easy compressability. In this case the extracted Reddit data
compressed to parquet with a 50 to 1 compression ratio. This allows for the Spark Batch Process to quickly read from the parquet files
and perform the batch processes on large datasets without much latency. The Spark Batch process then creates the user and subreddit graphs
performs a incremental PageRank calculation on the user graph and calculates the intersections of the subreddit graphs. The data is
written to Cassandra, a high performance key-value distributed database. There is a Flask webapp that allows users to explore the data.