
[2024.7.14]  Our AI Platform PodGPT is publicly available.
It is an online platform for deploying our latest multimodal foundation models for education and research.
Please try it out if you are interested!
Our AI Platform PodGPT is publicly available.
It is an online platform for deploying our latest multimodal foundation models for education and research.
Please try it out if you are interested!
[2024.7.12] Our preprint is available online! Please check it!
[2024.7.12] We are releasing a new benchmark encompassing the latest USMLE Step 1, Step 2, Step 3, and Ethics to further advance the filed. Check our database here.
[2024.7.11] We open-sourced the source codes of our PodGPT: LLMs in your pocket and benchmarking multilingual LLMs.
- Installation
- Quick Start
- Performance Evaluation
- Dataset Description
- Benchmarks and Results
- Real-world Deployment
- Automatic Speech Recognition
- Dataset Builder
- Upload and Download Models
- Structure of the Code
- Citation
- Contact
- Contribution
- Acknowledgement
pip install -r requirements.txtFor lightweight models (2B, 7B, and 8B), we optimize the entire model. Please check and setup hyper-parameters in config_small.yml.
python main_small.pyFor lager and heavy models (>8B), we optimize the Low-rank Adapter (LoRA). Please check and setup hyper-parameters in config_large.yml.
python main_large.pyWe also provide support for quantizing larger models, e.g., LLaMA 3 70B model, using the GPTQ algorithm and then optimizing the LoRA. The large models can be deployed on consumer GPUs after quantization.
We can directly use the Hugging Face transformers package to conduct quantization.
python quantization_HF.py --repo "meta-llama/Meta-Llama-3-70B-Instruct" --bits 4 --group_size 128Alternatively, we also provide a quantization script by using the Python AutoGPTQ package.
python quantization.py "meta-llama/Meta-Llama-3-70B-Instruct" "./gptq_model" "medical" --bits 4 --group_size 128 --desc_act 1 --dtype float16 --seqlen 2048 --damp 0.01Then, we need to upload the model to Hugging Face,
python upload_quantized_model.py --repo "shuyuej/MedLLaMA3-70B-BASE-MODEL-QUANT" --folder_path "./gptq_model"Lastly, we optimize the LoRA module,
python main_quantization.pyAll inferences are conducted using the vLLM engine. We use inference_pretrain.py and inference_single_model.py for larger models (>8B) and inference_sequential.py for smaller models (2B/7B/8B). Please check here for more information.
Note
Mistral 7B on Hindi MMLU Benchmarks:
Please un-comment this line.
To address the issue of repeated content in some responses, we applied a repetition_penalty during inference.
We simply use Directly answer the best option: instead of Answer: to better guide LLMs to generate the best option
and to easier extract the best option from the responses.
Please modify these lines
if you wanna try other prompts.
Note
LLaMA 3 8B on Hindi MMLU Benchmarks:
Please modify these lines.
Because most responses are in mixed English-Hindi or English, we used कृपया प्रश्न का उत्तर हिंदी में दें और सीधे सबसे अच्छे विकल्प के साथ जवाब दें: (Please answer the question in Hindi and directly answer the best option:) to guide the model.
english_prompt = "Directly answer the best option:"
english_prompt_pubmedqa = "Directly answer yes/no/maybe:"
hindi_prompt = "सीधे सबसे अच्छे विकल्प के साथ जवाब दें:"
french_prompt = "Répondez directement avec la meilleure option:"
spanish_prompt = "Responde directamente con la mejor opción:"
chinese_prompt = "直接回答最优选项:"Important
Please note that if you wanna conduct model inference using multiple GPUs, the GPUs' memory cannot be successfully released.
Please modify these lines
and make use of this sh file.
Sequentially evaluate the performance of multiple checkpoints (models).
Please note that we use --eval_pretrain to indicate whether to evaluate the original pre-trained model.
python inference_sequential.py --eval_pretrain True --id 35166 52749 70332 87915Sequentially evaluate the performance of the original pre-trained model and all the checkpoints.
Special Notice: Please change the checkpoint IDs and CUDA_VISIBLE_DEVICES
in the inference_large.sh file.
sh inference_large.shOnly evaluate the performance of the original pre-trained model.
python inference_pretrain.pyOnly evaluate the performance of a single checkpoint (model).
Please note that --id is the checkpoint id.
python inference_single_model.py --id 35166We also offer support for running OpenAI ChatGPT inference using API. Please enter your OpenAI API Key here.
Warning
Please note that OpenAI ChatGPT API is extremely expensive.
Please only use it if you have a budget for it!
python inference_chatgpt.pyPlease follow our instructions to transcribe your own podcasts and build your own dataset.
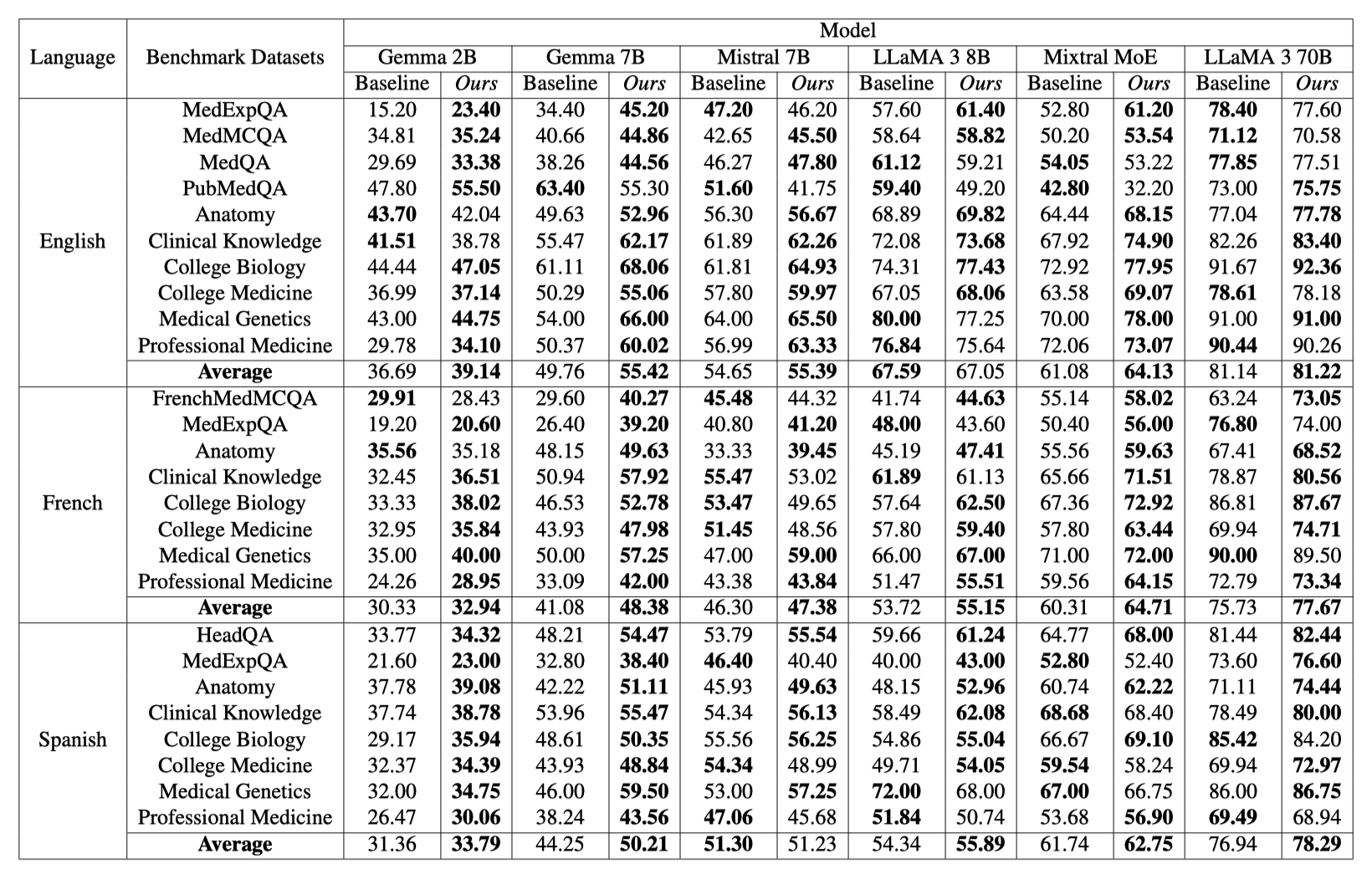
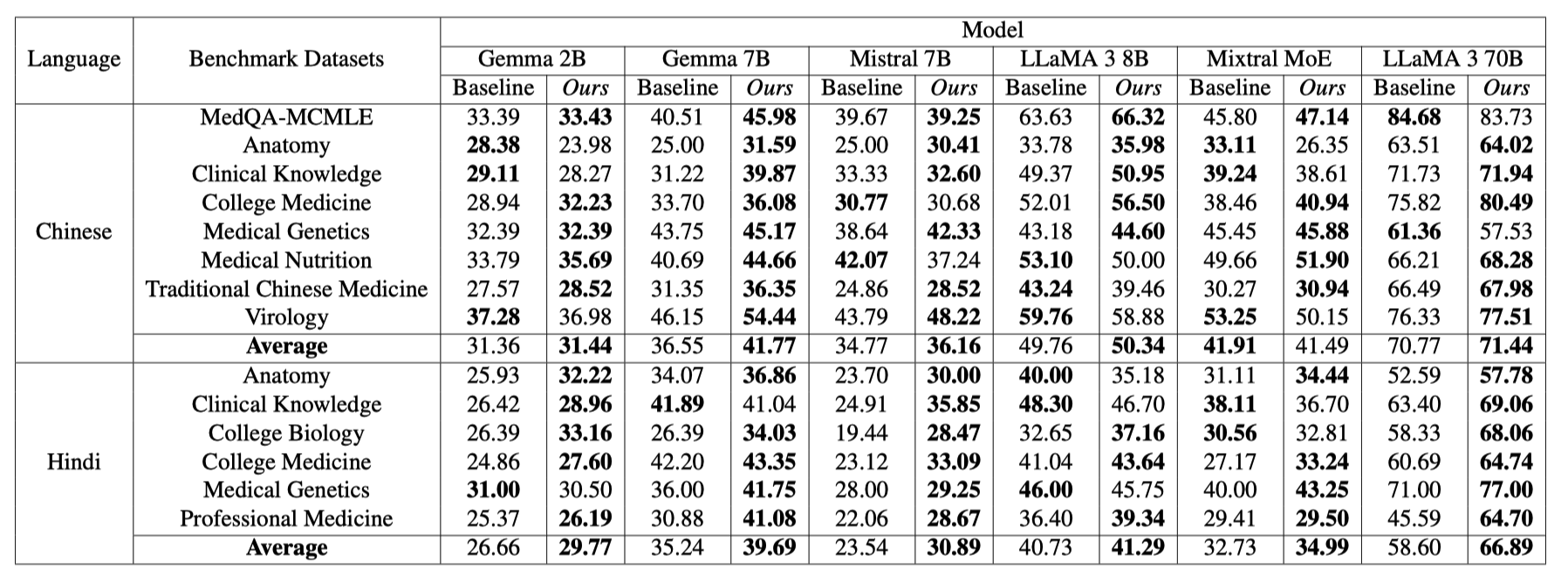
We utilized a comprehensive set of medical benchmarks from the most widely spoken languages in the world, including English, Mandarin, French, Spanish, and Hindi.
| Language | Dataset | # test examples | # of choices | Link | Ref |
|---|---|---|---|---|---|
| English | MedExpQA | 125 | 5 | Link | Paper |
| MedQA | 1273 | 4 | Link | Paper | |
| MedMCQA | 4183 | 4 | Link | Paper | |
| PubMedQA | 500 | 3 | Link | Paper | |
| MMLU - Anatomy | 135 | 4 | Link | Paper | |
| MMLU - Clinical Knowledge | 265 | 4 | Link | Paper | |
| MMLU - College Biology | 144 | 4 | Link | Paper | |
| MMLU - College Medicine | 173 | 4 | Link | Paper | |
| MMLU - Medical Genetics | 100 | 4 | Link | Paper | |
| MMLU - Professional Medicine | 272 | 4 | Link | Paper | |
| French | MedExpQA | 125 | 5 | Link | Paper |
| MedMCQA | 622 | 5 | Link | Paper | |
| MMLU - Anatomy | 135 | 4 | Link | Paper | |
| MMLU - Clinical Knowledge | 265 | 4 | Link | Paper | |
| MMLU - College Biology | 144 | 4 | Link | Paper | |
| MMLU - College Medicine | 173 | 4 | Link | Paper | |
| MMLU - Medical Genetics | 100 | 4 | Link | Paper | |
| MMLU - Professional Medicine | 272 | 4 | Link | Paper | |
| Spanish | HEAD-QA | 2742 | 4 | Link | Paper |
| MedExpQA | 125 | 5 | Link | Paper | |
| MMLU - Anatomy | 135 | 4 | Link | Paper | |
| MMLU - Clinical Knowledge | 265 | 4 | Link | Paper | |
| MMLU - College Biology | 144 | 4 | Link | Paper | |
| MMLU - College Medicine | 173 | 4 | Link | Paper | |
| MMLU - Medical Genetics | 100 | 4 | Link | Paper | |
| MMLU - Professional Medicine | 272 | 4 | Link | Paper | |
| Chinese | MedQA-MCMLE | 3426 | 4 | Link | Paper |
| CMMLU - Anatomy | 148 | 4 | Link | Paper | |
| CMMLU - Clinical Knowledge | 237 | 4 | Link | Paper | |
| CMMLU - College Medicine | 273 | 4 | Link | Paper | |
| CMMLU - Medical Genetics | 176 | 4 | Link | Paper | |
| CMMLU - Traditional Chinese Medicine | 185 | 4 | Link | Paper | |
| CMMLU - Virology | 169 | 4 | Link | Paper | |
| Hindi | MMLU - Anatomy | 135 | 4 | Link | Paper |
| MMLU - Clinical Knowledge | 265 | 4 | Link | Paper | |
| MMLU - College Biology | 144 | 4 | Link | Paper | |
| MMLU - College Medicine | 173 | 4 | Link | Paper | |
| MMLU - Medical Genetics | 100 | 4 | Link | Paper | |
| MMLU - Professional Medicine | 272 | 4 | Link | Paper |
For real-world deployment, please refer to the vLLM Distributed Inference and Serving and OpenAI Compatible Server.
In the scripts folder, we provide Automatic Speech Recognition (ASR) service.
python audio2text.pyWe used the following codes to pre-process our transcripts and generate training dataset. Please check these lines for different languages support.
python database_builder.pypython merge_database.pyIn the scripts folder, we offer support for both uploading and downloading models.
To upload your checkpoints to Hugging Face model repo,
python upload_model.py --repo "shuyuej/DrGemma2B" --id 35166 52749 70332 87915To download your model or files from Hugging Face repo,
python download_model.py --repo "shuyuej/DrGemma2B" --repo_type "model" --save_dir "./save_folder"At the root of the project, you will see:
├── requirements.txt
├── main_small.py
├── main_large.py
├── main_quantization.py
├── config_small.yml
├── config_large.yml
├── config_quantization.yml
├── config_chatgpt.yml
├── lib
│ ├── data_manager.py
│ ├── model_loader_small.py
│ ├── model_loader_large.py
│ ├── model_loader_quantization.py
│ ├── evaluation_small.py
│ ├── evaluation_large.py
│ └── evaluation_chatgpt.py
├── inference
│ ├── inference_large.sh
│ ├── inference_chatgpt.py
│ ├── inference_pretrain.py
│ ├── inference_sequential.py
│ └── inference_single_model.py
├── download_files
│ ├── download_model_from_hf.py
│ └── download_model_to_local.py
├── quantization
│ ├── quantization.py
│ └── upload_quantized_model.py
├── scripts
│ ├── audio2text.py
│ ├── download_model.py
│ ├── upload_model.py
│ ├── database_builder.py
│ └── merge_database.py
├── benchmark
│ ├── chinese_cmmlu
│ ├── chinese_mcmle
│ ├── english_medexpqa
│ ├── english_medmcqa
│ ├── english_medqa
│ ├── english_mmlu
│ ├── english_pubmedqa
│ ├── english_usmle
│ ├── french_medexpqa
│ ├── french_medmcqa
│ ├── french_mmlu
│ ├── hindi_mmlu
│ ├── spanish_headqa
│ ├── spanish_medexpqa
│ └── spanish_mmlu
└── utils
├── answer_utils.py
├── benchmark_utils.py
├── eval_chatgpt_utils.py
├── eval_large_utils.py
├── eval_small_utils.py
├── test_extraction_chinese.py
├── test_extraction_english.py
├── test_extraction_french.py
├── test_extraction_hindi.py
├── test_extraction_spanish.py
└── utils.py
If you find our work useful in your research, please consider citing it in your publications. We provide a BibTeX entry below.
@article {Jia2024medpodgpt,
author = {Jia, Shuyue and Bit, Subhrangshu and Searls, Edward and Claus, Lindsey and Fan, Pengrui and Jasodanand, Varuna H. and Lauber, Meagan V. and Veerapaneni, Divya and Wang, William M. and Au, Rhoda and Kolachalama, Vijaya B},
title = {{MedPodGPT}: A multilingual audio-augmented large language model for medical research and education},
elocation-id = {2024.07.11.24310304},
year = {2024},
doi = {10.1101/2024.07.11.24310304},
publisher = {Cold Spring Harbor Laboratory Press},
URL = {https://www.medrxiv.org/content/early/2024/07/12/2024.07.11.24310304},
eprint = {https://www.medrxiv.org/content/early/2024/07/12/2024.07.11.24310304.full.pdf},
journal = {medRxiv}
}Core Contributor and Maintainer:
Database Contributor and Maintainer:
If you have any questions, please drop us an email at brucejia@bu.edu, sbit@bu.edu, and nsearls@bu.edu.
We always welcome contributions to help make PodGPT Library better. If you would like to contribute, please submit a pull request.
The PodGPT Library is created and maintained by the Kolachalama Laboratory.