This project contains tasks for getting acquainted with the Spark MLlib library.
After getting acquainted with the structure of the project and installing the necessary dependencies, you can proceed to the task task1.md.
.
└───SparkMLCourse # Project folder
├──data # Folder with the data that will be required when performing the task
│ └──titanic # Folder with titanic data
│ ├──gender_submission.csv # Answers for the test set
│ ├──test.csv # Test set
│ └──train.csv # Training set
├──images # Images for README
├──lectures # Lectures folder
├──SparkCustomMLSkeleton # Code skeleton with custom transformers and estimators
├──SparkCustomMLPipeline # Code example with custom transformers and estimators and basic pipeline
├──SparkMLPipeline # Project example with Spark ML
├──task1.md # Task 1 description
└──README.md # Awesome README
As a rule, Spark is installed on clusters and allows you to run tasks on the nodes of this cluster. However, Spark can also be run in local mode. This allows you to install it on any computer or laptop and create and test pipelines on it, and then the same code can be used on a real cluster. This module provides instructions for installing the necessary components.
We will need:
- Java Development Kit (JDK) - is an implementation of either one of the Java Platform, Standard Edition, Java Platform, Enterprise Edition, or Java Platform, Micro Edition platforms released by Oracle Corporation in the form of a binary product aimed at Java developers on Solaris, Linux, macOS or Windows. The JDK includes a private JVM, and a few other resources to finish the development of a Java application. Since the introduction of the Java platform, it has been by far the most widely used Software Development Kit (SDK).
- Scala - is a strong statically typed general-purpose programming language which supports both object-oriented programming and functional programming.
- sbt - is an open-source build tool for Scala and Java projects, similar to Apache's Maven and Ant.
- Python - is an interpreted high-level general-purpose programming language.
- Apache Spark - is an open-source unified analytics engine for large-scale data processing.
- Integrated development environment (IDE) - is any code redactor.
It is recommended to use JDK11.
- Go to: https://www.oracle.com/java/technologies/javase-jdk11-downloads.html
- Choose your platform and download the installer.
- Install it.

It is recommended to use the latest version.
- Go to https://www.scala-sbt.org/download.html
- Depending on your platform, run the appropriate commands, or download the archive with the installer and install it.

It is recommended to use Scala 2.12.x.
- Go to https://www.scala-lang.org/download/2.12.14.html
- Choose your platform and download the installer.
- Install it.

It is recommended to use Spark 3.x.x.
- Go to https://archive.apache.org/dist/spark/spark-3.1.2/
- Download "without-hadoop" version.
- Install it.

It is recommended to use Python 3.x.x.
- Go to https://www.python.org/downloads/
- Choose your platform and download the installer.
- Install it.

You can develop in any code editor that is convenient for you. We recommend using Intellij IDEA.
To install Intellij IDEA:
- Go to https://www.jetbrains.com/idea/download/#section=mac
- Choose your platform and download the installer.
- Install it. NOTE: During installation, it is also recommended installing the Scala plugin.

docker pull jupyter/all-spark-notebook
docker run -p 4040:4041 -p 8888:8888 --rm -it -v "${PWD}":/home/jovyan --name all-spark-notebook jupyter/all-spark-notebook
To access to notebooks use url with token from terminal (It will be appear when you run docker run). Example of this url:
http://127.0.0.1:8888/?token=ba4ac51b4c0c7d9f98a9e99f0e4043e9dce9ed219cd43c44
To upload data:
- Create folder
data: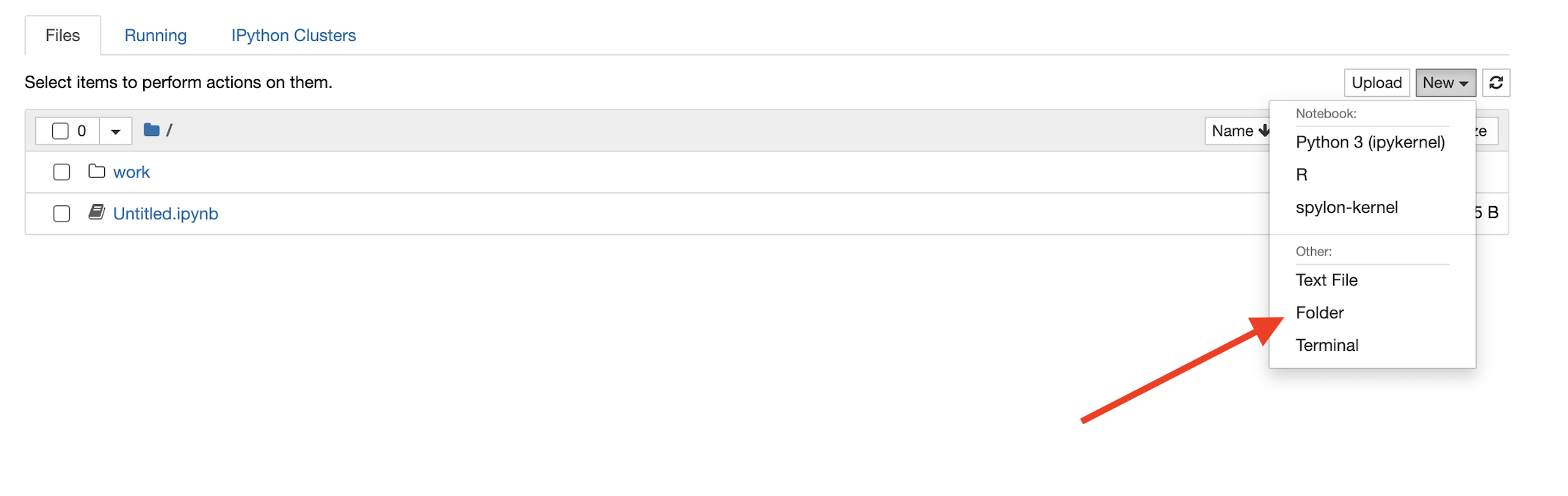
- Create folder
mllibin folderdata - Click on
uploadbutton:
- Choose file and click on
openbutton - Click on
uploadbutton


Note: To execute example Spark ML ALS you should create folder als in folder mllib and upload file sample_movielens_ratings.txt to this folder
To create new notebook:
- Click on
New - Choose
spylon-kernel
You can find these examples here: Spark mllib examples
In examples there are used next examples:
- sample_binary_classification_data.txt
- sample_kmeans_data.txt
- sample_libsvm_data.txt
- sample_linear_regression_data.txt
- sample_movielens_data.txt
- sample_multiclass_classification_data.txt
- als/sample_movielens_ratings.txt
- Open this link in browser: https://github.com/apache/spark/blob/master/data/mllib/sample_libsvm_data.txt
- Locate the "Raw" button adjacent to the "Blame" button.
- Press "Alt" ("Option" on Macbook) on your keyboard and left-click on your mouse at the same time.
- The file will download automatically in a ".txt" format (it did for me)
- Download file to your data folder