Original repository address FastChat

Install Package
pip3 install --upgrade pip # enable PEP 660 support
pip3 install -e ".[model_worker,webui]"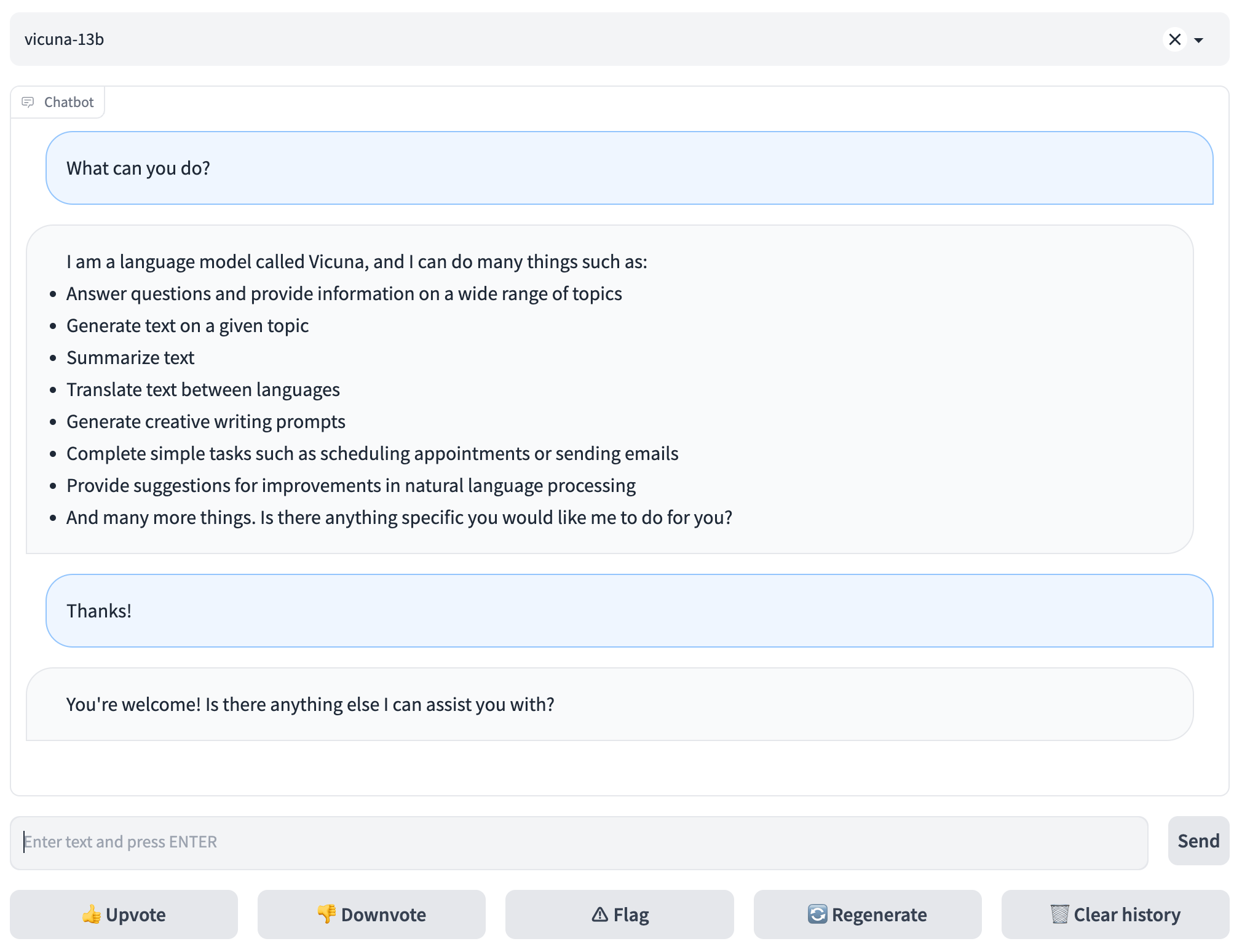
To serve using the web UI, you need three main components: web servers that interface with users, model workers that host one or more models, and a controller to coordinate the webserver and model workers. You can learn more about the architecture here.
Here are the commands to follow in your terminal:
python3 -m fastchat.serve.controllerThis controller manages the distributed workers.
python3 -m fastchat.serve.model_worker --model-path ./bmodel/chatglm3-6b --device tpu --dev_id 0Wait until the process finishes loading the model and you see "Uvicorn running on ...". The model worker will register itself to the controller .
To ensure that your model worker is connected to your controller properly, send a test message using the following command:
python3 -m fastchat.serve.test_message --model-path ./bmodel/chatglm3-6b --model-name chatglm3-6b --device tpu --dev_id 0You will see a short output.
python3 -m fastchat.serve.gradio_web_serverThis is the user interface that users will interact with.
By following these steps, you will be able to serve your models using the web UI. You can open your browser and chat with a model now. If the models do not show up, try to reboot the gradio web server.
- You can register multiple model workers to a single controller, which can be used for serving a single model with higher throughput or serving multiple models at the same time. When doing so, please allocate different GPUs and ports for different model workers.
# worker 0
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5 --controller http://localhost:21001 --port 31000 --worker http://localhost:31000
# worker 1
CUDA_VISIBLE_DEVICES=1 python3 -m fastchat.serve.model_worker --model-path lmsys/fastchat-t5-3b-v1.0 --controller http://localhost:21001 --port 31001 --worker http://localhost:31001
- You can also launch a multi-tab gradio server, which includes the Chatbot Arena tabs.
python3 -m fastchat.serve.gradio_web_server_multi- The default model worker based on huggingface/transformers has great compatibility but can be slow. If you want high-throughput batched serving, you can try vLLM integration.
- If you want to host it on your own UI or third party UI, see Third Party UI.
FastChat provides OpenAI-compatible APIs for its supported models, so you can use FastChat as a local drop-in replacement for OpenAI APIs. The FastChat server is compatible with both openai-python library and cURL commands. The REST API is capable of being executed from Google Colab free tier, as demonstrated in the FastChat_API_GoogleColab.ipynb notebook, available in our repository. See docs/openai_api.md.