This repository contains the source code of our paper: Yin Wei, Yifan Liu, Chunhua Shen, Youliang Yan, Enforcing geometric constraints of virtual normal for depth prediction (accepted for publication in ICCV' 2019).




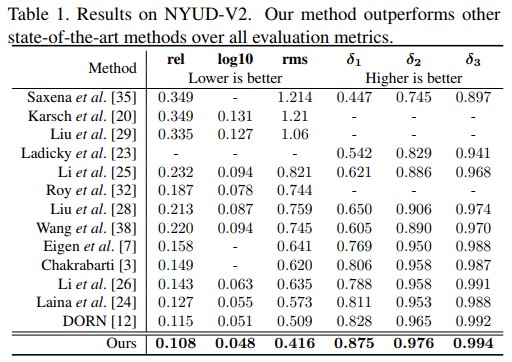
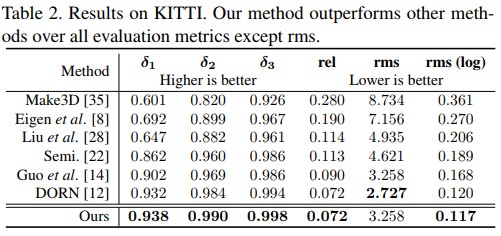
- State-of-the-art performance: The comparisons with other SOTA methods on NYU and KITTI are illustrated as follow. The published model trained on NYU can achieve 10.5% on absrel.


- Please refer to Installation.
-
NYUDV2 The details of datasets can be found here. The Eigen split of labeled images can be downloaded here. Please extract it to ./datasets. Our SOTA model is trained on the around 20K unlabled images.
-
KITTI The details of KITTI benchmark for monocular depth prediction is here. We use both the official split and Eigen split. You can find the filenames here.
- ResNext101_32x4d backbone, trained on NYU dataset, download here
- ResNext101_32x4d backbone, trained on KITTI dataset (Eigen split), download here
- ResNext101_32x4d backbone, trained on KITTI dataset (Official split), download here
# Run the inferece on NYUDV2 dataset
python ./tools/test_nyu_metric.py \
--dataroot ./datasets/NYUDV2 \
--dataset nyudv2 \
--cfg_file lib/configs/resnext101_32x4d_nyudv2_class \
--load_ckpt ./nyu_rawdata.pth
# Test depth predictions on any images, please replace the data dir in test_any_images.py
python ./tools/test_any_images.py \
--dataroot ./ \
--dataset any \
--cfg_file lib/configs/resnext101_32x4d_nyudv2_class \
--load_ckpt ./nyu_rawdata.pth If you want to test the kitti dataset, please see here
@inproceedings{Yin2019enforcing,
title={Enforcing geometric constraints of virtual normal for depth prediction},
author={Yin, Wei and Liu, Yifan and Shen, Chunhua and Yan, Youliang},
booktitle= {The IEEE International Conference on Computer Vision (ICCV)},
year={2019}
}
Wei Yin: wei.yin@adelaide.edu.au