Unsupervised DepthNet
This codebase implements the system described in the paper:
Learning Structure From Motion From Motion
Clement Pinard, Laure Chevalley, Antoine Manzanera, David Filliat
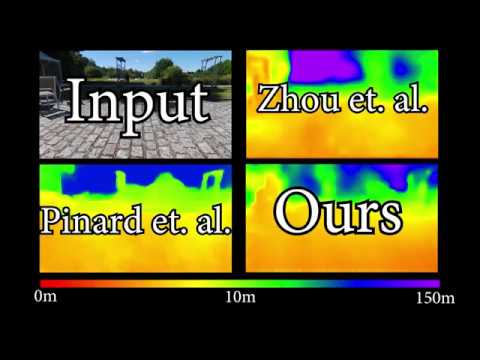
See the project webpage for more details.
Preamble
This codebase was developed and tested with Pytorch 0.4.1, CUDA 9.2 and Ubuntu 16.04.
Prerequisite
pip3 install -r requirements.txtor install manually the following packages :
pytorch>=0.4.1
scipy
imageio
argparse
tensorboardX
blessings
progressbar2
path.py
It is also advised to have python3 bindings for opencv for tensorboard visualizations
Preparing training data
For KITTI, preparation is roughly the same command as in SFM Learner. Note that here you can get the pose at the same time. If translation data is not very precise (see note here), rotation for stabilization is pretty accurate, which can make it a drone-like training environment.
For StillBox, every thing is already setup. For this training, a new version with rotations has been developped, which you will be able to download soon. The rotation-less version can be found here via a torrent link.
To get KITTI, first download the dataset using this script provided on the official website, and then run the following command. The --with-pose option will get pose matrices, especially for supervision of rotation compensation. The --with-depth option will save resized copies of depth groundtruth for validation set, to help you setting hyper parameters.
python3 data/prepare_train_data.py /path/to/raw/kitti/dataset/ --dataset-format 'kitti' --dump-root /path/to/resulting/formatted/data/ --width 416 --height 128 --num-threads 4 [--static-frames /path/to/static_frames.txt] [--with-pose] [--with-gt]For Cityscapes, download the following packages: 1) leftImg8bit_sequence_trainvaltest.zip, 2) camera_trainvaltest.zip. You will probably need to contact the administrators to be able to get it. No pose is currently available, but metadata would be theoritcally possible to use to get them. Then run the following command
python3 data/prepare_train_data.py /path/to/cityscapes/dataset/ --dataset-format 'cityscapes' --dump-root /path/to/resulting/formatted/data/ --width 416 --height 171 --num-threads 4Notice that for Cityscapes the img_height is set to 171 because we crop out the bottom part of the image that contains the car logo, and the resulting image will have height 128.
Training
Once the data are formatted following the above instructions, you should be able to train the model by running the following command
python3 train_img_pairs.py /path/to/the/formatted/data/ -b4 -s3.0 --ssim 0.1 --epoch-size 3000 --sequence-length 3 --log-output [--with-gt] [--supervise-pose]You can then start a tensorboard session in this folder by
tensorboard --logdir=checkpoints/and visualize the training progress by opening https://localhost:6006 on your browser.
Some useful options, with points not discussed in paper
rotation-mode: Lets you change between euler and quaternion. In practice, does not have noticable effect.--network-input-size: Lets you downsample the picture before feeding to Pose and Depth networks, this is especially useful for large images, that can have more spatial information for Photometric loss, but still having small input for networks. This has been tested with pictures of size832 x 256without much effect in KITTI.--training-milestones: During training, I_t and I_r can be anything within the frame sequence, but for stability, especially from scratch, it can be interesting to first fix them. first milestone is the epoch after which I_r is not fixed anymore. Likewise, second milestone is for I_t.
Flexible shifts training
As an experimental training, you can try flexible shifts. This will every N epochs (N is argument) recompute optimal shifts for a given sample. The goal is to avoid sequences with too much disparity (by reducing shift) or static scenes (by increasing shift). A proper dataset has yet to be constructed to check if this is a good idea or not. See the equivalent for SFMLearner here
python3 train_flexible_shifts.py /path/to/the/formatted/data/ -b4 -s3.0 --ssim 0.1 --epoch-size 3000 --sequence-length 3 --log-output [--with-gt] [--supervise-pose] -D 30 -r5Evaluation
Depth evaluation is avalaible
python3 test_disp.py --pretrained-dispnet /path/to/dispnet --pretrained-posenet /path/to/posenet --dataset-dir /path/to/KITTI_raw --dataset-list /path/to/test_files_listTest file list is available in kitti eval folder. To get fair comparison with SFM learner evaluation code, it should be tested only with depth scale from GT pose, and from kitti_eval/test_files_eigen_filtered.txt, a filtered subset of kitti_eval/test_files_eigen.txt with which the GPS accuracy was measured to be good.
Pose evaluation is available by using this code
Pretrained Nets
Soon to be available
Depth Results
KITTI
| Abs Rel | Sq Rel | RMSE | RMSE(log) | Acc.1 | Acc.2 | Acc.3 |
|---|---|---|---|---|---|---|
| 0.294 | 3.992 | 7.573 | 0.356 | 0.609 | 0.833 | 0.909 |
KITTI stabilized
| Abs Rel | Sq Rel | RMSE | RMSE(log) | Acc.1 | Acc.2 | Acc.3 |
|---|---|---|---|---|---|---|
| 0.271 | 4.495 | 7.312 | 0.345 | 0.678 | 0.856 | 0.924 |
Still Box
| Abs Rel | Sq Rel | RMSE | RMSE(log) | Acc.1 | Acc.2 | Acc.3 |
|---|---|---|---|---|---|---|
| 0.468 | 10.924 | 15.756 | 0.544 | 0.452 | 0.573 | 0.714 |
Still Box stabilized
| Abs Rel | Sq Rel | RMSE | RMSE(log) | Acc.1 | Acc.2 | Acc.3 |
|---|---|---|---|---|---|---|
| 0.297 | 5.253 | 10.509 | 0.404 | 0.668 | 0.840 | 0.906 |
FYI, here are Still Box stabilized results from a supervised training.
Still Box stabilized supervised
| Abs Rel | Sq Rel | RMSE | RMSE(log) | Acc.1 | Acc.2 | Acc.3 |
|---|---|---|---|---|---|---|
| 0.212 | 2.064 | 7.067 | 0.296 | 0.709 | 0.881 | 0.946 |