This is a JAX implementation of NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. This code is created and maintained by Boyang Deng, Jon Barron, and Pratul Srinivasan.
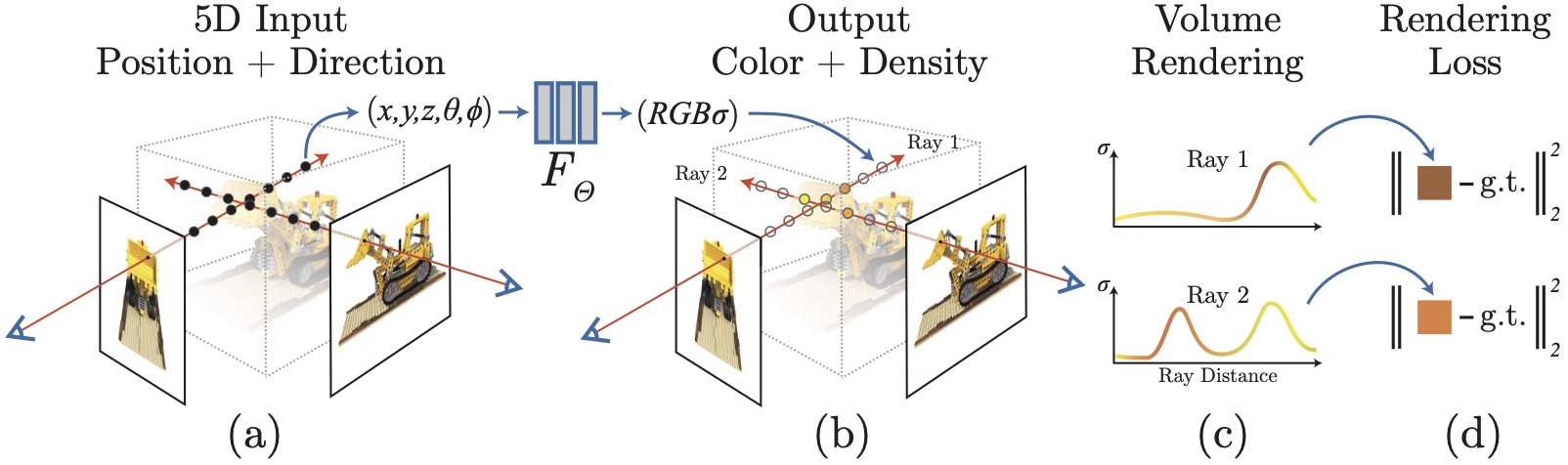
Our JAX implementation currently supports:
| Platform | Single-Host GPU | Multi-Device TPU | ||
|---|---|---|---|---|
| Type | Single-Device | Multi-Device | Single-Host | Multi-Host |
| Training |  |
|
|
|
| Evaluation | |
|
|
|
The training job on 128 TPUv2 cores can be done in 2.5 hours (v.s 3 days for TF NeRF) for 1 million optimization steps. In other words, JaxNeRF trains to the best while trains very fast.
As for inference speed, here are the statistics of rendering an image with 800x800 resolution (numbers are averaged over 50 rendering passes):
| Platform | 1 x NVIDIA V100 | 8 x NVIDIA V100 | 128 x TPUv2 |
|---|---|---|---|
| TF NeRF | 27.74 secs |  |
|
| JaxNeRF | 20.77 secs | 2.65 secs | 0.35 secs |
The code is tested and reviewed carefully to match the original TF NeRF implementation. If you have any issues using this code, please do not open an issue as the repo is shared by all projects under Google Research. Instead, just email jaxnerf@google.com.
We recommend using Anaconda to set up the environment. Run the following commands:
# Clone the repo
svn export https://github.com/google-research/google-research/trunk/jaxnerf
# Create a conda environment, note you can use python 3.6-3.8 as
# one of the dependencies (TensorFlow) hasn't supported python 3.9 yet.
conda create --name jaxnerf python=3.6.12; conda activate jaxnerf
# Prepare pip
conda install pip; pip install --upgrade pip
# Install requirements
pip install -r jaxnerf/requirements.txt
# [Optional] Install GPU and TPU support for Jax
# Remember to change cuda101 to your CUDA version, e.g. cuda110 for CUDA 11.0.
pip install --upgrade jax jaxlib==0.1.57+cuda101 -f https://storage.googleapis.com/jax-releases/jax_releases.html
Then, you'll need to download the datasets
from the NeRF official Google Drive.
Please download the nerf_synthetic.zip and nerf_llff_data.zip and unzip them
in the place you like. Let's assume they are placed under /tmp/jaxnerf/data/.
That's it for installation. You're good to go. Notice: For the following instructions, you don't need to enter the jaxnerf folder. Just stay in the parent folder.
bash jaxnerf/train.sh demo /tmp/jaxnerf/data
bash jaxnerf/eval.sh demo /tmp/jaxnerf/data
Once both jobs are done running (which may take a while if you only have 1 GPU
or CPU), you'll have a folder, /tmp/jaxnerf/data/demo, with:
- Trained NeRF models for all scenes in the blender dataset.
- Rendered images and depth maps for all test views.
- The collected PSNRs of all scenes in a TXT file.
Note that we used the demo config here which is basically the blender config
in the paper except smaller batch size and much less train steps. Of course, you
can use other configs to replace demo and other data locations to replace
/tmp/jaxnerf/data.
We provide 2 configurations in the folder configs which match the original
configurations used in the paper for the blender dataset and the LLFF dataset.
Be careful when you use them. Their batch sizes are large so you may get OOM error if you have limited resources, for example, 1 GPU with small memory. Also, they have many many train steps so you may need days to finish training all scenes.
You can also train NeRF on only one scene. The easiest way is to use given configs:
python -m jaxnerf.train \
--data_dir=/PATH/TO/YOUR/SCENE/DATA \
--train_dir=/PATH/TO/THE/PLACE/YOU/WANT/TO/SAVE/CHECKPOINTS \
--config=configs/CONFIG_YOU_LIKE
Evaluating NeRF on one scene is similar:
python -m jaxnerf.eval \
--data_dir=/PATH/TO/YOUR/SCENE/DATA \
--train_dir=/PATH/TO/THE/PLACE/YOU/SAVED/CHECKPOINTS \
--config=configs/CONFIG_YOU_LIKE \
--chunk=4096
The chunk parameter defines how many rays are feed to the model in one go.
We recommend you to use the largest value that fits to your device's memory but
small values are fine, only a bit slow.
You can also define your own configurations by passing command line flags. Please refer to the define_flags function in nerf/utils.py for all the flags and their meanings.
Note: For the ficus scene in the blender dataset, we noticed that it's sensible to different initializations,
e.g. using different random seeds, if using the original learning rate schedule in the paper.
Therefore, we provide a simple tweak (turned off by default) for more stable trainings: using lr_delay_steps and lr_delay_mult.
This allows the training to start from a smaller learning rate (lr_init * lr_delay_mult) in the first lr_delay_steps.
We didn't use them for our pretrained models
but we tested lr_delay_steps=5000 with lr_delay_mult=0.2 and it works quite smoothly.
We provide a collection of pretrained NeRF models that match the numbers reported in the paper. Actually, ours are slightly better overall because we trained for more iterations (while still being much faster!). You can find our pretrained models here. The performances (in PSNR) of our pretrained NeRF models are listed below:
| Scene | Chair | Drums | Ficus | Hotdog | Lego | Materials | Mic | Ship | Mean |
|---|---|---|---|---|---|---|---|---|---|
| TF NeRF | 33.00 | 25.01 | 30.13 | 36.18 | 32.54 | 29.62 | 32.91 | 28.65 | 31.01 |
| JaxNeRF | 34.08 | 25.03 | 30.43 | 36.92 | 33.28 | 29.91 | 34.53 | 29.36 | 31.69 |
| Scene | Room | Fern | Leaves | Fortress | Orchids | Flower | T-Rex | Horns | Mean |
|---|---|---|---|---|---|---|---|---|---|
| TF NeRF | 32.70 | 25.17 | 20.92 | 31.16 | 20.36 | 27.40 | 26.80 | 27.45 | 26.50 |
| JaxNeRF | 33.04 | 24.83 | 21.23 | 31.76 | 20.27 | 28.07 | 27.42 | 28.10 | 26.84 |
If you use this software package, please cite it as:
@software{jaxnerf2020github,
author = {Boyang Deng and Jonathan T. Barron and Pratul P. Srinivasan},
title = {{JaxNeRF}: an efficient {JAX} implementation of {NeRF}},
url = {https://github.com/google-research/google-research/tree/master/jaxnerf},
version = {0.0},
year = {2020},
}
and also cite the original NeRF paper:
@inproceedings{mildenhall2020nerf,
title={NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis},
author={Ben Mildenhall and Pratul P. Srinivasan and Matthew Tancik and Jonathan T. Barron and Ravi Ramamoorthi and Ren Ng},
year={2020},
booktitle={ECCV},
}
We'd like to thank Daniel Duckworth, Dan Gnanapragasam, and James Bradbury for their help on reviewing and optimizing this code. We'd like to also thank the amazing JAX team for very insightful and helpful discussions on how to use JAX for NeRF.