-
This repo is a modification on the MAE repo. Installation and preparation follow that repo.
-
This repo is based on
timm==0.3.2, for which a fix is needed to work with PyTorch 1.8.1+. -
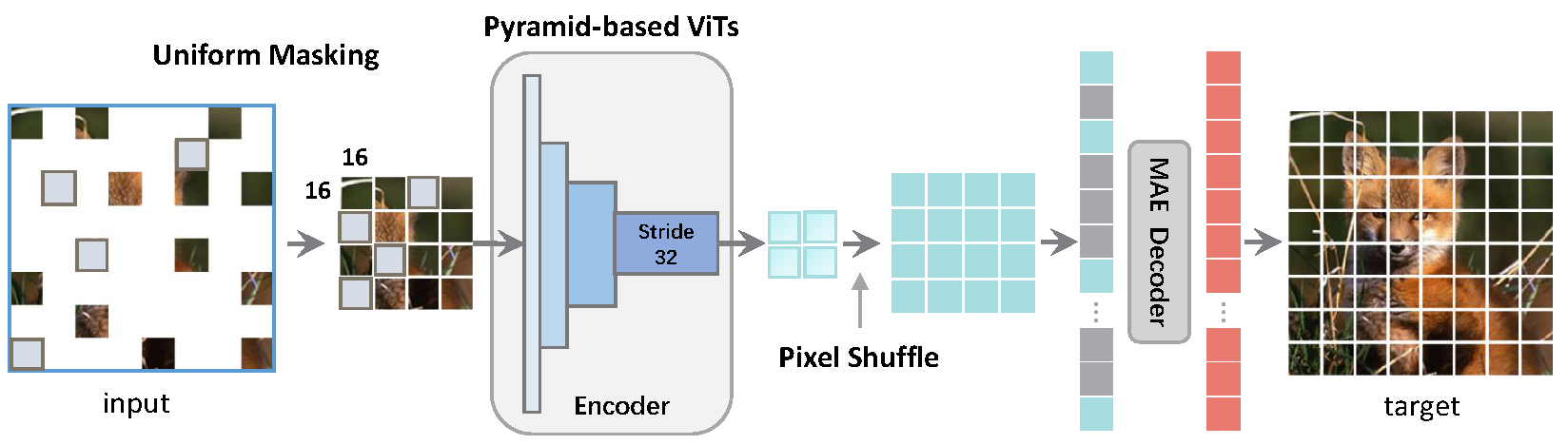
This repo is the official implementation of Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers with Locality. It includes codes and models for the following tasks:
ImageNet Pretrain: See PRETRAIN.md.
ImageNet Finetune: See FINETUNE.md.
Object Detection: See DETECTION.md.
Semantic Segmentation: See SEGMENTATION.md.
Visualization: See Colab notebook.
@article{Li2022ummae,
author = {Li, Xiang and Wang, Wenhai and Yang, Lingfeng and Yang, Jian},
journal = {arXiv:2205.10063},
title = {Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers with Locality},
year = {2022},
}
30/May/2022: Visualization code/demo is updated at Colab notebook.
26/May/2022: The Chinese blog of this paper is available at zhihu.
23/May/2022: The preprint version is public at arxiv.
(a) In MAE, the global window of Vanilla ViT can receive arbitrary subset of image patches by skipping random 75% of the total, whilst (b) skipping these 75% patches is unacceptable for Pyramid-based ViT as patch elements are not equivalent across the local windows. (c) A straightforward solution is to adopt the mask token for the encoder (e.g., SimMIM) at the cost of slower training. (d) Our Uniform Masking (UM) approach (including Uniform Sampling and Secondary Masking) enables the efficient MAE-style pre-training for Pyramid-based ViTs while keeping its competitive fine-tuning accuracy.

UM-MAE is an efficient and general technique that supports MAE-style MIM Pre-training for popular Pyramid-based Vision Transformers (e.g., PVT, Swin).
- We propose Uniform Masking, which successfully enables MAE pre-training (i.e., UM-MAE) for popular Pyramid-based ViTs.
- We empirically show that UM-MAE considerably speeds up pre-training efficiency by ~2X and reduces the GPU memory consumption by at least ~2X compared to the existing sota Masked Image Modelling (MIM) framework (i.e, SimMIM) for Pyramid-based ViTs, whilst maintaining the competitive fine-tuning performance. Notably, using HTC++ detector, the pre-trained Swin-Large backbone self-supervised under UM-MAE only in ImageNet-1K (57.4 AP^bbox, 49.8 AP^mask) can even outperform the one supervised in ImageNet-22K (57.1 AP^bbox, 49.5 AP^mask).
- We also reveal and discuss several notable different behaviors between Vanilla ViT and Pyramid-based ViTs under MIM.

| Models | Pre-train Method | Sampling Strategy | Secondary Mask Ratio | Encoder Ratio | Pretrain Epochs | Pretrain Hours | FT acc@1(%) | FT weight/log |
|---|---|---|---|---|---|---|---|---|
| ViT-B | MAE | RS | -- | 25% | 200 | todo | 82.88 | weight/log |
| ViT-B | MAE | UM | 25% | 25% | 200 | todo | 82.88 | weight/log |
| PVT-S | SimMIM | RS | -- | 100% | 200 | 38.0 | 79.28 | weight/log |
| PVT-S | UM-MAE | UM | 25% | 25% | 200 | 21.3 | 79.31 | weight/log |
| Swin-T | SimMIM | RS | -- | 100% | 200 | 49.3 | 82.20 | weight/log |
| Swin-T | UM-MAE | UM | 25% | 25% | 200 | 25.0 | 82.04 | weight/log |
| Swin-L | SimMIM | RS | -- | 100% | 800 | -- | 85.4 | link |
| Swin-L | UM-MAE | UM | 25% | 25% | 800 | todo | 85.3 | weight/log |
RS: Random Sampling; UM: Uniform Masking, consisting of Uniform Sampling and Secondary Masking
The pretraining and finetuning of our project are based on DeiT, MAE and SimMIM. The object detection and semantic segmentation parts are based on MMDetection and MMSegmentation respectively. Thanks for their wonderful work.
This project is under the CC-BY-NC 4.0 license. See LICENSE for details.