DRLib:A concise deep reinforcement learning library which integrats amost all of off policy RL algos with HER and PER.
A concise deep reinforcement learning library which integrats amost all of off policy RL algos with HER and PER. The library is written based on the code in https://github.com/openai/spinningup, and can be achieved with tensorflow or pytorch. Compared with spinning up, the multi-process and experimental grid wrapper have been deleted for easy application. Besides, the code in our library is convenient to debug with pycharm~
欢迎大家关注我的最新工作RHER,简洁高效的HER变体: https://github.com/kaixindelele/RHER
最新的、全面的实验结果:

4种tf,3种torch的HER算法在三个操作任务的测试结果。
python spinup_utils/plot.py HER_DRLib_mpi1/2 --select Push
#如果是Windows建议用绝对路径,否则找不到文件
python train_torch_mpi_norm_save.py
python train_torch_mpi_norm_load.py
-
tf1和pytorch两个版本的算法,前者快,后者新,任君选择;
-
在spinup的基础上,封装了DDPG, TD3, SAC等主流强化算法,相比原来的函数形式的封装,调用更方便,且加了pytorch的GPU调用;
-
添加了HER和PER功能,非常适合做机器人相关任务的同学们;
-
实现了最简单的并行自动调参(ExperimentGrid)和多进程(MPI_fork-实现了,没有完全实现)部分,适合新手在pycharm中debug,原版的直接调试经常会报错~
教程链接:【Spinning Up】四、python同时启动多个不同参数脚本
多进程教程:没写~
我终于把tf版本-基于mpi的多进程调好了~
torch版本的没有测试完毕,有报错!
如果大家的CPU核心足够多的情况下,试试mpi多进程,性能会提升比较大的。
目前测试的结果是,tf-DDPG的性能最佳,TD3的结果竟然会比ddpg的差,简直了~
-
最后,全网最详细的环境配置教程!亲测两个小时内,从零配置完全套环境!
-
求三连,不行的话,求个star!
-
Clone the repo and cd into it:
git clone https://github.com/kaixindelele/DRLib.git cd DRLib -
Create anaconda DRLib_env env:
conda create -n DRLib_env python=3.6.9 source activate DRLib_env -
Install pip_requirement.txt:
pip install -r pip_requirement.txt
If installation of mpi4py fails, try the following command(Only this one can be installed successfully!):
conda install mpi4py
或者直接看下面的链接: ubuntu-windows-install-mpi4py-亲测好使!
conda install seaborn==0.8.1 scipy -y
-
Install tensorflow-gpu=1.14.0
conda install tensorflow-gpu==1.14.0 # if you have a CUDA-compatible gpu and proper drivers -
Install torch torchvision
# CUDA 9.2 conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=9.2 -c pytorch # CUDA 10.1 conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch # CUDA 10.2 conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.2 -c pytorch # CPU Only conda install pytorch==1.6.0 torchvision==0.7.0 cpuonly -c pytorch # or pip install pip --default-timeout=100 install torch -i http://pypi.douban.com/simple --trusted-host pypi.douban.com [pip install torch 在线安装!非离线!](https://blog.csdn.net/hehedadaq/article/details/111480313)
-
Install mujoco and mujoco-py
refer to: https://blog.csdn.net/hehedadaq/article/details/109012048
-
Install gym[all]
refer to https://blog.csdn.net/hehedadaq/article/details/110423154
- Example 1. SAC-tf1-HER-PER with FetchPush-v1:
-
modify params in arguments.py, choose env, RL-algorithm, use PER and HER or not, gpu-id, and so on.
-
run with train_tf.py or train_torch.py
python train_tf.py
-
exp results to local:https://blog.csdn.net/hehedadaq/article/details/114045615
-
plot results:https://blog.csdn.net/hehedadaq/article/details/114044217
超强版强化学习画图脚本!
相比于原始的plot.py文件,增加了如下的功能
1.可以直接在pycharm或者vscode执行,也可以用命令行传参;
2.按exp_name排序,而不是按时间排序;
3.固定好每个exp_name的颜色;
4.可以调节曲线的线宽,便于观察;
5.保存图片到本地,便于远程ssh画图~
6.自动显示全屏
7.图片自适应
8.针对颜色不敏感的人群,可以在每条legend上注明性能值,和性能序号
9.对图例legend根据性能从高到低排序,便于分析比较
10.提供clip_xaxis值,对训练程度进行统一截断,图看起来更整洁。 seaborn版本0.8.1
.
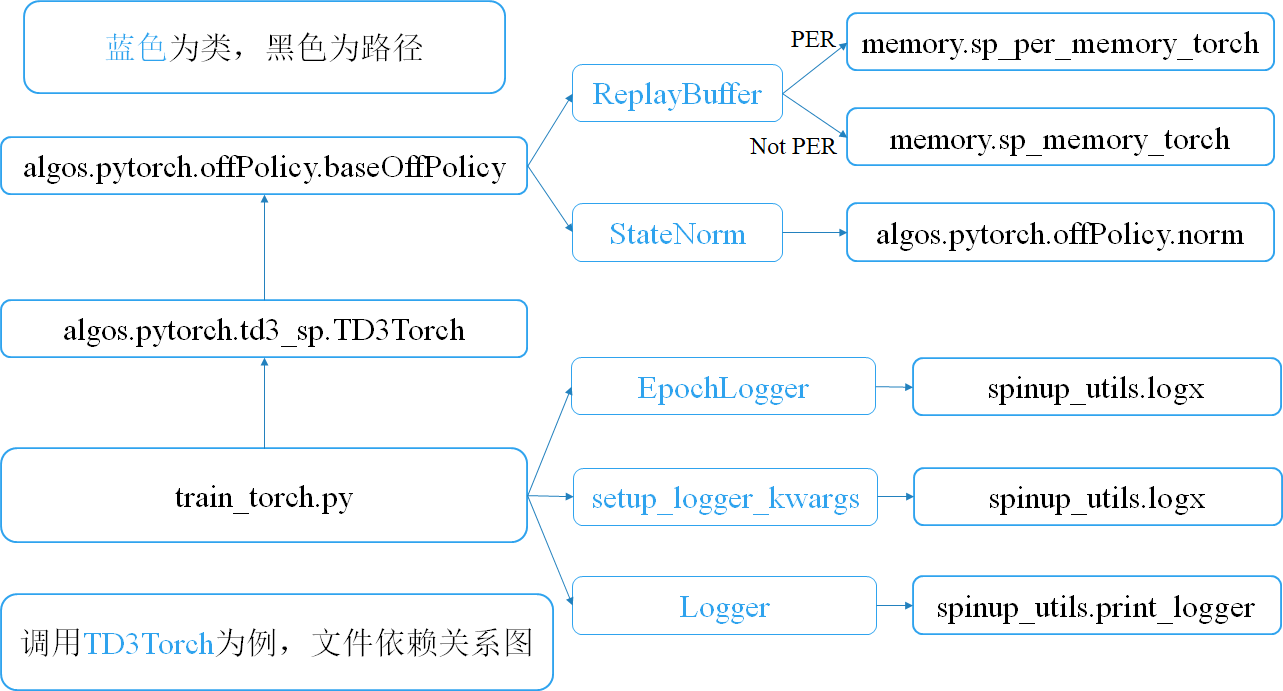
├── algos
│ ├── pytorch
│ │ ├── ddpg_sp
│ │ │ ├── core.py-------------It's copied directly from spinup, and modified some details.
│ │ │ ├── ddpg_per_her.py-----inherits from offPolicy.baseOffPolicy, where one can choose whether or not HER and PER
│ │ │ ├── ddpg.py-------------It's copied directly from spinup
│ │ │ ├── __init__.py
│ │ ├── __init__.py
│ │ ├── offPolicy
│ │ │ ├── baseOffPolicy.py----baseOffPolicy, DDPG/TD3/SAC and so on.
│ │ │ ├── norm.py-------------state normalizer, update mean/std with training process.
│ │ ├── sac_auto
│ │ ├── sac_sp
│ │ │ ├── core.py-------------likely as before.
│ │ │ ├── __init__.py
│ │ │ ├── sac_per_her.py
│ │ │ └── sac.py
│ │ └── td3_sp
│ │ ├── core.py
│ │ ├── __init__.py
│ │ ├── td3_gpu_class.py----td3_class modified from spinup
│ │ └── td3_per_her.py
│ └── tf1
│ ├── ddpg_sp
│ │ ├── core.py
│ │ ├── DDPG_class.py------------It's copied directly from spinup, and wrap algorithm from function to class.
│ │ ├── DDPG_per_class.py--------Add PER.
│ │ ├── DDPG_per_her_class.py----DDPG with HER and PER without inheriting from offPolicy.
│ │ ├── DDPG_per_her.py----------Add HER and PER.
│ │ ├── DDPG_sp.py---------------It's copied directly from spinup, and modified some details.
│ │ ├── __init__.py
│ ├── __init__.py
│ ├── offPolicy
│ │ ├── baseOffPolicy.py
│ │ ├── core.py
│ │ ├── norm.py
│ ├── sac_auto--------------------SAC with auto adjust alpha parameter version.
│ │ ├── core.py
│ │ ├── __init__.py
│ │ ├── sac_auto_class.py
│ │ ├── sac_auto_per_class.py
│ │ └── sac_auto_per_her.py
│ ├── sac_sp--------------------SAC with alpha=0.2 version.
│ │ ├── core.py
│ │ ├── __init__.py
│ │ ├── SAC_class.py
│ │ ├── SAC_per_class.py
│ │ ├── SAC_per_her.py
│ │ ├── SAC_sp.py
│ └── td3_sp
│ ├── core.py
│ ├── __init__.py
│ ├── TD3_class.py
│ ├── TD3_per_class.py
│ ├── TD3_per_her_class.py
│ ├── TD3_per_her.py
│ ├── TD3_sp.py
├── arguments.py-----------------------hyperparams scripts
├── drlib_tree.txt
├── HER_DRLib_exps---------------------demo exp logs
│ ├── 2021-02-21_HER_TD3_FetchPush-v1
│ │ ├── 2021-02-21_18-26-08-HER_TD3_FetchPush-v1_s123
│ │ │ ├── checkpoint
│ │ │ ├── config.json
│ │ │ ├── params.data-00000-of-00001
│ │ │ ├── params.index
│ │ │ ├── progress.txt
│ │ │ └── Script_backup.py
├── memory
│ ├── __init__.py
│ ├── per_memory.py--------------mofan version
│ ├── simple_memory.py-----------mofan version
│ ├── sp_memory.py---------------spinningup tf1 version, simple uniform buffer memory class.
│ ├── sp_memory_torch.py---------spinningup torch-gpu version, simple uniform buffer memory class.
│ ├── sp_per_memory.py-----------spinningup tf1 version, PER buffer memory class.
│ └── sp_per_memory_torch.py
├── pip_requirement.txt------------pip install requirement, exclude mujoco-py,gym,tf,torch.
├── spinup_utils-------------------some utils from spinningup, about ploting results, logging, and so on.
│ ├── delete_no_checkpoint.py----delete the folder where the experiment did not complete.
│ ├── __init__.py
│ ├── logx.py
│ ├── mpi_tf.py
│ ├── mpi_tools.py
│ ├── plot.py
│ ├── print_logger.py------------save the information printed by the terminal to the local log file。
│ ├── run_utils.py---------------now I haven't used it. I have to learn how to multi-process.
│ ├── serialization_utils.py
│ └── user_config.py
├── train_tf1.py--------------main.py for tf1
└── train_torch.py------------main.py for torch
the achievement of HER is based on the following code :
-
It can be converged, but this code is too difficult. https://github.com/openai/baselines
-
It can also converged, but only for DDPG-torch-cpu. https://github.com/sush1996/DDPG_Fetch
-
It can not be converged, but this code is simpler. https://github.com/Stable-Baselines-Team/stable-baselines
种瓜得豆来解释her: 第一步在春天(state),种瓜(origin-goal)得豆,通过HER,把目标换成种豆,按照之前的操作,可以学会在春天种豆得豆; 第二步种米得瓜,学会种瓜得瓜; 即只要是智能体中间经历过的状态,都可以当做它的目标,进行学会。 即如果智能体能遍历所有的状态空间,那么它就可以学会达到整个状态空间。
论文分析视频:https://www.bilibili.com/video/BV1BA411x7Wm
代码分析文档:https://github.com/kaixindelele/DRLib/blob/main/algos/pytorch/offPolicy/HER_introduction.md
- state-normalize: success rate from 0 to 1 for FetchPush-v1 task.
- Q-clip: success rate from 0.5 to 0.7 for FetchPickAndPlace-v1 task.
- action_l2: little effect for Push task.
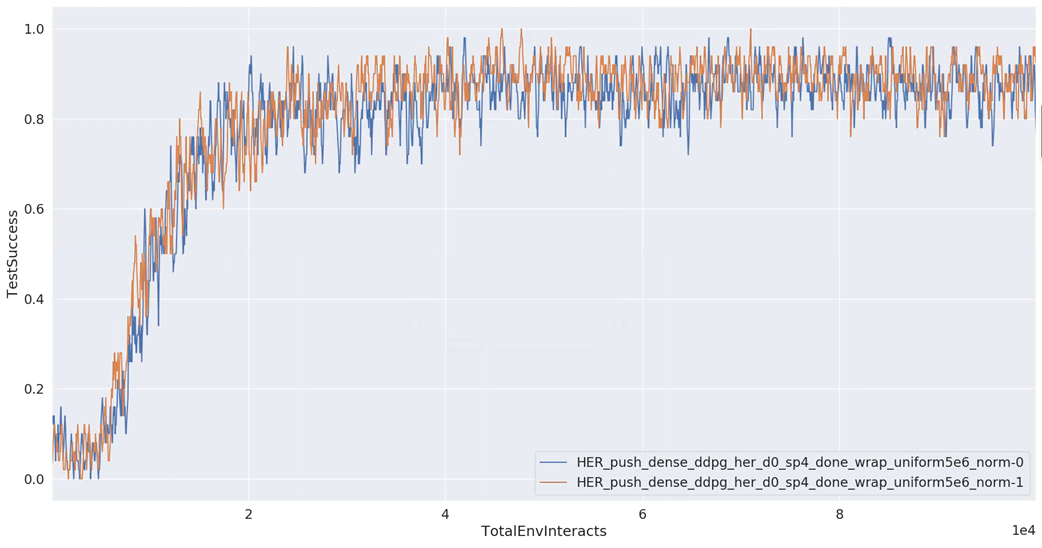
refer to:off-policy全系列(DDPG-TD3-SAC-SAC-auto)+优先经验回放PER-代码-实验结果分析
这个库我封装了好久,整个代码库简洁、方便、功能比较齐全,在环境配置这块几乎是手把手教程,希望能给大家节省一些时间~
从零开始配置,不到两小时,从下载代码库,到配置环境,到在自己的环境中跑通,全流程非常流畅。
-
PPO的封装;---PPO不封装了!机械臂操作不用PPO~
-
DQN的封装;---这个好像用的人也不多,放弃了~
-
多进程的封装;
-
ExperimentGrid的封装;
深度强化学习-DRL:799378128
欢迎关注知乎帐号:未入门的炼丹学徒
CSDN帐号:https://blog.csdn.net/hehedadaq