Fortify를 이용하여 취약점을 분석하면 다수의 발견사항(오탐 포함)으로 인해 많은 시간이 소요된다. 수작업 분석 과정 중 일부라도 자동화할 수 있다면 해당 시간은 단축될 수 있다. Data Flow 유사성 판단을 자동화하여 기존 수작업 분석 시간을 단축 가능한 방법을 찾아보았다. (실제 1/3 이하로 단축 가능)
Fortify 분석 결과(약점)가 실제 공격이 가능한지(취약점) 수작업으로 구분/분석하는 업무는 전체 코드를 검토하면 많은 시간이 소요되어, 취약한 코드의 Data flow 유사성(아래 그림의 Analysis Trace 내용)을 참고하여 취약 여부를 판단하곤 한다. (servlet filter에 보안필터가 적용되어 있어 검토할 필요없이 양호하거나, 코드로직 내부/외부 뷰 페이지에 커스텀 보안필터가 있을 경우가 있어 전체 코드를 보아야 하는 경우가 예외적으로 존재한다.) 사람의 판단에 의해 Data Flow의 유사성을 구분하는 것이 아니라 통계기법(kmeans)를 이용하여 기계적으로 구분하는 방법을 적용해보았다.


Fortify SSC의 API를 이용하면 Fortify의 Data Flow 데이터를 추출할 수 있으며, 취약점 유형 중 XSS를 대상으로 테스트하였다. Fortify의 TraceNode Data 중에서 데이터 중 nodeType(IN_CALL 등), text(savePointJsonp 등)만 추출하여 아래와 같이 데이터를 구성한다. 2개의 프로젝트에서 XSS와 관련된 Data flow만 추출(파일 fortify_ml.xlsx, fortify_ml2.xlsx)하였고, 수작업으로 확인한 취약여부 데이터를 추가하였다. (file경로와 이름은 군집화하는 것에 도움이 안되는 것으로 경험 상 판단했다.)
EXTERNAL_ENTRY Spring Method Mapping URL
IN_CALL savePointJsonp(2)
IN_OUT_CALL getCallback(this : return)
RETURN Return
Fortify에 의해 발견된 약점 중 약 1/3의 수를 K값으로 하면 최근 3개의 프로젝트에서 수작업으로 구분한 타입과 가장 유사하게 구분가능한 k값이 되었다.
다른 프로젝트에서 모두 범용적으로 사용할 수 있는 K값 결정 로직이 필요했다. 사람의 구분이 잘못 되었던 데이터(앞과 뒤 내용은 동일하나 분석 내용이 길어...)와 사람의 의도와 다르게 기계가 같다고 구분한 데이터를 테스트 데이터로 만들었고, 분석하려는 프로젝트의 데이터에 검증용으로 추가하는 코드를 작성하였다.
- 분석 결과가 길어 수작업 분류가 잘못 됨
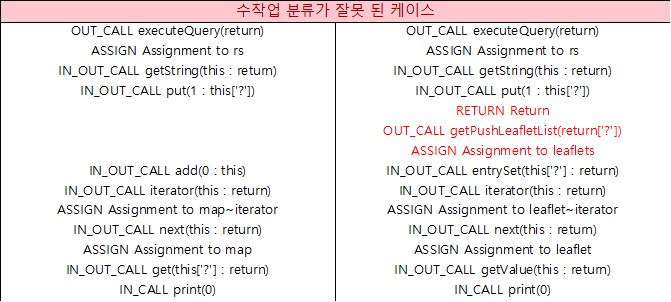
- 호출 흐름이 다르나 호출 유형이 다수가 같아 기계가 같은 유형으로 분류 함
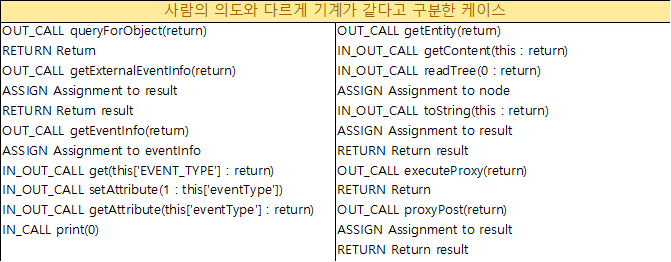


위와 같은 방식으로 업무를 진행하면 아래와 같은 경우에서 오탐 케이스가 발생할 수 있다.
- Data Flow 분석만으로는 취약하나,악성코드가 실행 불가한 response type(json 등)이라 xss에 안전하다고 판단할 경우 (fortify 분석 기능으로 제거 불가능하다.)
- Fortify가 인지하지 못하는 커스텀 보안필터를 사용 (fortify option에 해당 보안필터를 추가하면 된다.)
- 실제 업무를 효율화하기 위해서는 kmeans 외에 다양한 취약점 종류에 적용 가능한 방법이 필요하다.
- Fortify 는 오탐율을 줄이기 위해 보수적인 탐지 룰(XSS Persistent의 경우 DB저장만으로도 리포팅하지 않고, 사용자 단으로의 Response 출력이 없을 경우 리포팅하지 않는 등)을 개발하기 때문에 Dataflow 분석에 의한 발견량은 적어 업무 경감의 의미가 퇴색될 수 있다.
- kmeans는 군집 번호가 계속 변경되기 때문에 별도의 Labeling 방법이 필요하다.
- 이번 경우와 같이 사전지식(경험)을 통한 k값을 정해 편의성을 정하는 경우가 많으나, 최적의 k 값을 찾기 위한 elbow curve 등 통계적인 검증도 필요하다.
- elbow method에서 J 변화가 대체로 부드러워 이 방식으로 K를 정하는 데에는 무리가 있었다.
- 문서를 백터화할 때 NLP 혹은 tokenizer 수준으로 구분하지는 않는다.
- Survey of Approaches for Handling Static Analysis Alarms 논문과 같이 군집화 외에 발견사항을 효율적으로 다룰 수 있는 다양한 방법의 적용도 필요 함
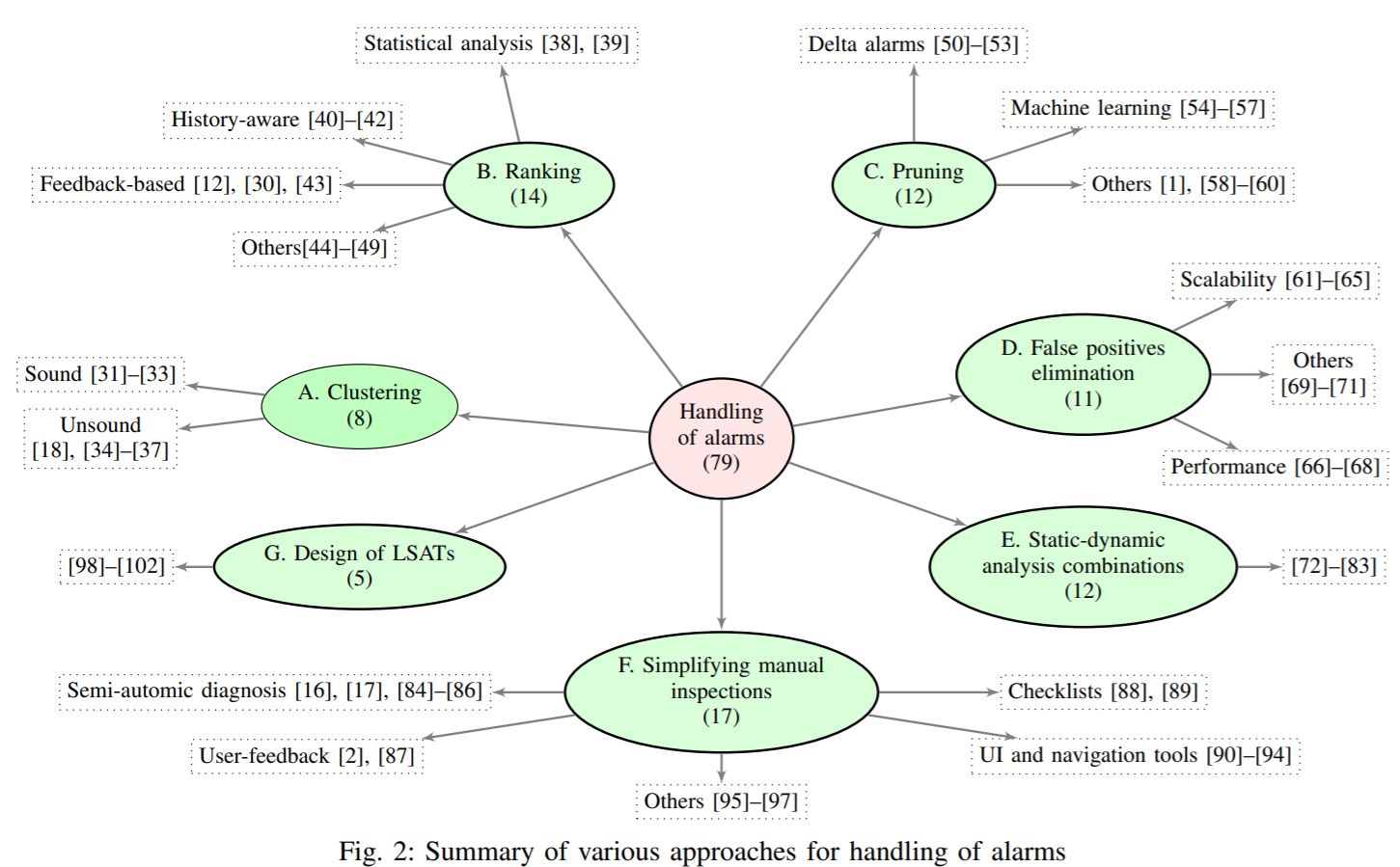

Approaches for improving handling of static analysis findings : klocwork 제품에서 프로토타입으로 k-mean 알고리즘으로 약점 군집화 적용, 적절한 K 값을 찾기위한 적절한 방법이 기술되진 않음 Survey of Approaches for Handling Static Analysis Alarms : 정적분석 발견사항을 효율적으로 다룰 수 있는 법을 광범위하게 연구한 논문 joern doc, joern code, joern video : 각 함수에서 사용한 API Symbol(Topic)의 사용 패턴을 분석하고, 확인된 취약점과 근거리의 함수를 취약점 후보로 분석함 (knn 알고리즘 사용)
knn 알고리즘 설명 : https://kkokkilkon.tistory.com/14, https://tariat.tistory.com/37
kmeans 알고리즘 설명 : https://lovit.github.io/nlp/machine%20learning/2018/03/21/kmeans_cluster_labeling/ 약점과 취약점 설명 : 소스코드에 존재하는 잠재적 위험은 약점, 약점 중 침해 사고로 연결 되는 위험은 취약점