다양한 구어체 말뭉치들을 모아서 직접 프리트레인, 파인튜닝한 감성 분석 특화 모델입니다.
이 모델은 2020 국어 정보 처리 시스템 경진 대회 출품작입니다.
저희의 모델은 Hugging Face 사의 transformers 라이브러리를 적극적으로 도입하였으며,
직접 프리트레인 / 파인튜닝을 완료한 모델들을 S3 에 업로드 하고 있습니다.
따라서 S3의 목록을 참고하셔서 설정을 바꾸신 후, 이를 통해 바로 파인튜닝을 진행하실 수 있습니다.
- Model 2
from transformers import ElectraTokenizer, ElectraModel
# Model 2 (Recommended)
tokenizer = ElectraTokenizer.from_pretrained("damien-ir/kosentelectra-discriminator-v2")
model = ElectraModel.from_pretrained("damien-ir/kosentelectra-discriminator-v2")- 다른 모델 번호를 사용하고 싶으시다면,
v2의 번호를 수정하여 사용해주세요. 아래는 예시입니다.
from transformers import ElectraTokenizer, ElectraModel
# Model 3 (Bigger Vocab, Best Score)
tokenizer = ElectraTokenizer.from_pretrained("damien-ir/kosentelectra-discriminator-v3")
model = ElectraModel.from_pretrained("damien-ir/kosentelectra-discriminator-v3")또한, Base 모델만으로는 다소 일반적인 사용이 힘들다고 판단하여 Small 모델을 지금도 학습 중입니다.
TFRC 측에 요청하여 한 달 가량 추가적으로 TPU를 사용할 수 있도록 인가받았고, 이를 통해 현재 학습시키고 있습니다.
현재 직접 사용하실 수 있는 Small 모델은 2번 모델을 1M Steps 학습시킨 모델 뿐이며, 다른 모델들의 학습 결과는 추후 알려 드리겠습니다.
from transformers import ElectraTokenizer, ElectraModel
# Small Model 2 (1M steps)
tokenizer = ElectraTokenizer.from_pretrained("damien-ir/kosentelectra-discriminator-v2-small")
model = ElectraModel.from_pretrained("damien-ir/kosentelectra-discriminator-v2-small")- 다른 모델들의 벤치마크 결과는 페이지 하단, 또는 wandb 페이지 를 참고하시기 바랍니다.
- 다음의 명령어를 쉘 창에서 입력하여 이 저장소의 파일을 복사합니다.
git clone https://github.com/damien-ir/KoSentELECTRA
cd KoSentELECTRA-
파인튜닝 되어있는 모델을 사용하시려면,
config.json파일 속model_name을 다음과 같이 수정해줍니다.파인튜닝 되어있는 모델은 NSMC와 네이버 음식점 리뷰를 섞어 학습시킨 모델이며, 사용하시려면 json 파일을 다음과 같이 수정해주세요.
{
"model_name": "damien-ir/kosentelectra-discriminator-v2-mixed"
}또는 2번 모델의 NSMC 데이터만으로 파인튜닝된 모델을 사용하실 수 있습니다.
각 번호의 모델마다 파인튜닝된 모델이 업로드 되어 있으므로, 필요에 따라 v2 를 수정해서 사용하실 수 있습니다.
{
"model_name": "damien-ir/kosentelectra-discriminator-v2-nsmc"
}-
docker의 --gpus all 명령어를 사용할 수 있다면, 다음 명령어를 실행해서 바로 이진 클래스 분류를 실행할 수 있습니다.
--rm 옵션을 사용 시 컨테이너가 종료될 때 자동으로 삭제됩니다.
gpu 없이 학습 자체는 가능하나, 속도가 매우 느립니다.
(Pytorch 1.6.0 - Cuda 10.1, Ubuntu 18.04 Cuda 10.1)
docker run --rm --gpus all -v $(pwd):/electra damienir/kosentelectra:base-
RTX 3천번대 모델을 사용 중이시라면, 다음의 명령어를 사용해주세요.
(Pytorch Nightly - Cuda 11.0, Ubuntu 18.04 Cuda 11.0)
docker run --rm --gpus all -v $(pwd):/electra damienir/kosentelectra:rtx3000- 이후 모델 학습 결과가 KoSentELECTRA 폴더 속에 자동적으로 저장됩니다.
-
docker를 이용한 학습이 싫으시다면, 직접
classification.py를 실행하여 fine-tuning / benchmark를 실행할 수 있습니다.이 경우엔 electra 폴더를 만드셔서
config.json파일과 학습 파일들을 옮기시거나, 또는 설정 파일과classification.py를 수정해주세요. -
Windows 10의 환경이라 GPU 문제로 인해 docker 설정이 어려운 경우,
nvidia의 cuda toolkit documentation, simpletransformers의 setup 을 참고하여 GPU 환경을 구축 후 실행해 주세요.
-
wandb를 사용하고자 하는 분은 config.json 파일에
"wandb_project": "wandb 프로젝트 이름"을 넣으시면 잘 작동합니다. -
config 설정은 simpletransformers의 Args Explained 를 참고해주세요.
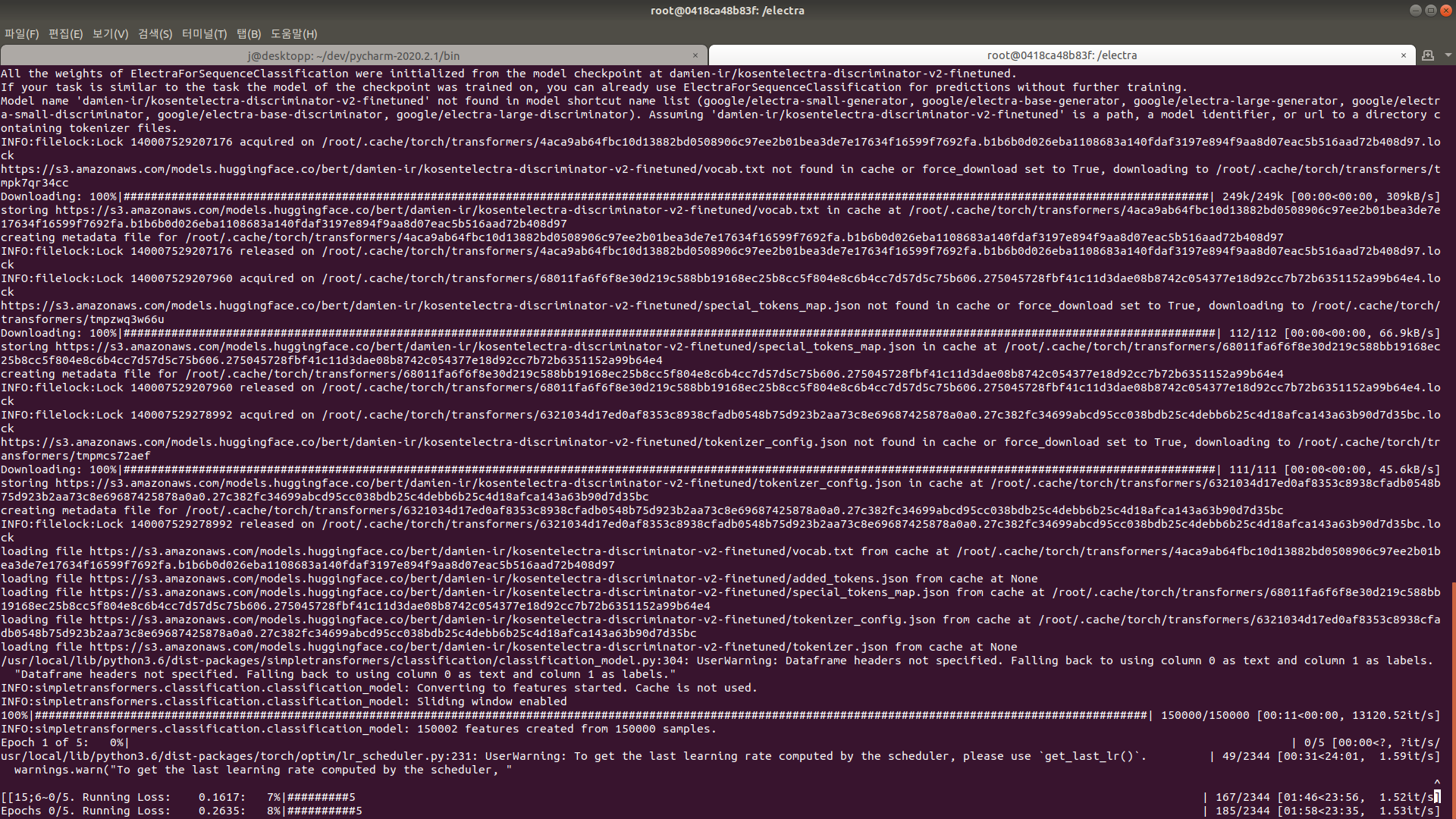
도커가 정상적으로 실행되었다면 다음과 같이 모델이 학습되는 모습을 볼 수 있습니다.
+) 다음의 명령어를 사용하여 간단한 감성 분석 서버를 만들 수 있습니다. localhost:8000으로 접속해보세요.
docker run --rm --gpus all -p 8000:8000 --name nsmc-web damienir/hkd-electra:nsmc-web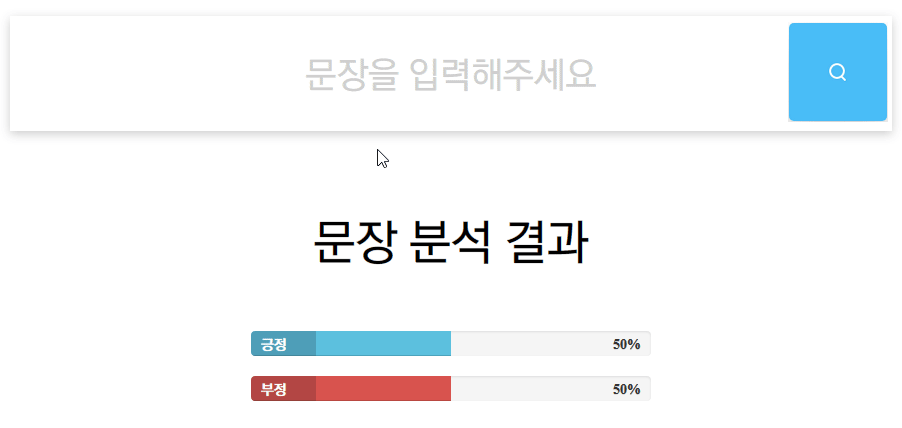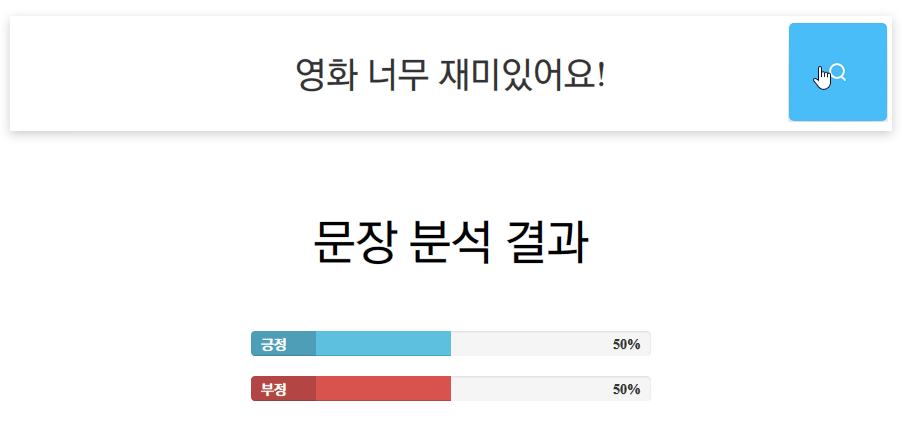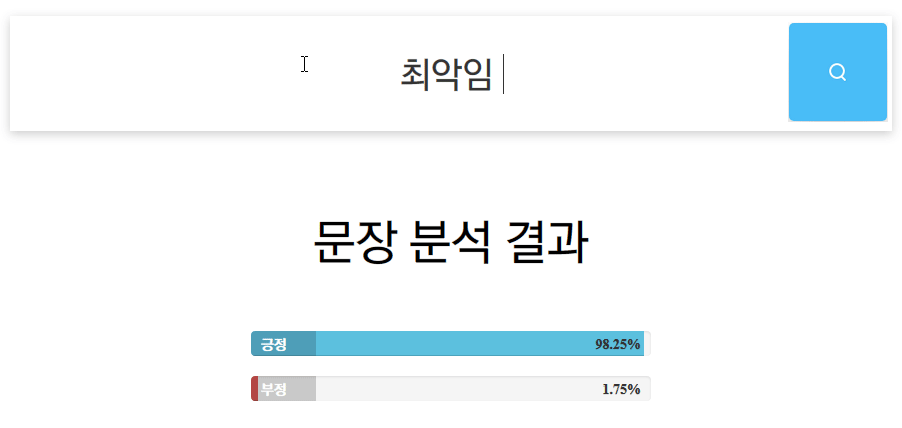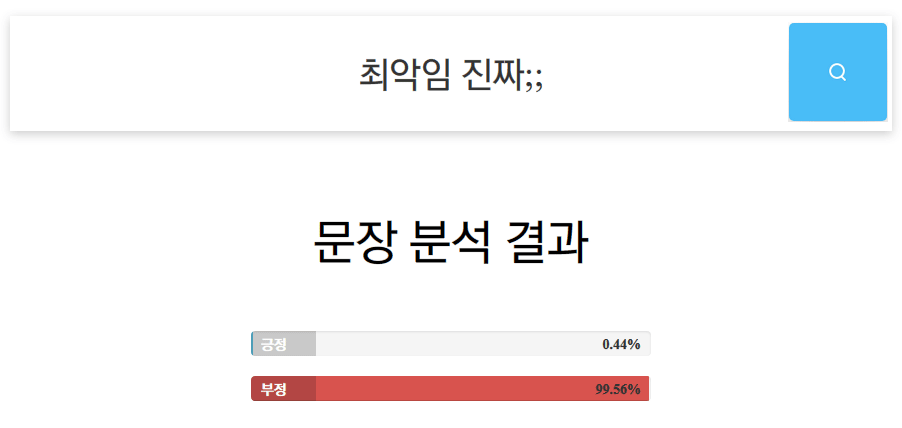
개인으로서 수집할 수 있는 대용량 말뭉치는 다 사용하였으며, 각 모델마다 차이가 있습니다.
사용한 코퍼스 목록들은 다음과 같습니다.
- KcBERT Corpus
- Wikipedia
- NSMC
- KCC
- 국어국립원 모두의 말뭉치 구어 / 문어 / 신문 / 메신저 / 웹 말뭉치
- 직접 크롤링한 음식점 리뷰 (주로 구어체, 21GB)
모든 vocab는 tokeniers의 BertWordPieceTokenizer를 사용하여 만들었으며,
limit_alphabet을 1만 이상으로 설정하여 생성하였습니다.
각 모델 별 Vocab와 말뭉치의 차이는 다음과 같습니다.
- Model 1
- Vocab size 32000, KcBERT + 음식점 리뷰 + NSMC + 위키피디아 + KCC 사용, 2M steps 학습
- Model 2
- Vocab size 32000, KcBERT + 음식점 리뷰 (소량) + NSMC 사용, 1M steps 학습
- Model 3
- Vocab size 64000, KcBERT + 음식점 리뷰 + NSMC + 위키피디아 + KCC + 국립국어원 모두의 말뭉치, 1.6M steps 학습
- Model 4
- Vocab size 128000, KcBERT + 음식점 리뷰 + NSMC + 위키피디아 + KCC + 국립국어원 모두의 말뭉치, 1.3M steps 학습
- Model 5 (for KorQuad testing)
- Vocab size 32000, 인라이플의 Large 모델 vocab 사용, 말뭉치는 위와 같음, 1.75M steps 학습
구어체 기반의 모델을 학습시에는 다소 Base 모델의 기본 학습률인 2e-4가 높다고 판단하였고,
이를 1.5e-4 로 수정하여 학습시켰습니다.
모델 번호에 따라 vocab size의 차이가 있을 수 있습니다.
{
"use_tpu": true,
"num_tpu_cores": 8,
"tpu_name": "your-tpu",
"tpu_zone": "europe-west4-a",
"model_size": "base",
"vocab_size": 32000,
"do_lower_case": false,
"learning_rate": 1.5e-4,
"keep_checkpoint_max": 10,
"train_batch_size": 256,
"save_checkpoints_steps": 20000,
"num_train_steps": 1300000
}학습에 사용된 설정 파일들은 pretrain_config 를 참고하시기 바랍니다.
또한 학습에 사용된 말뭉치들이 저작권 및 개인정보가 많이 포함되어 있는 만큼, 직접적인 공유가 어렵습니다.
워낙 양이 많아 익명 처리가 불가능해서, 이 점은 굉장히 아쉽게 생각하고 있습니다.
simpletransformers 를 이용한 파인 튜닝 코드를 작성하였으며,
내용은 이 리포지토리에 첨부 되어있는 classification.py 파일과 별반 차이 없으며, 경우에 따라 학습률이나 세부 파라미터를 조정하는 정도입니다.
최종 업로드 모델은 크게 파라미터를 손 볼 필요가 없어 쉽게 재현이 가능한 5e-5의 lr을 설정한 모델을 업로드 하였습니다.
기존 파인튜닝 코드들의 경우 성능을 비교하거나, 한 눈에 보기 위해서는 다소 시간을 소요해야 했으나,
simpletransformers와 그에 내장되어 있는 wandb 를 사용하여 빠르고, 한 눈에 성능을 비교할 수 있습니다.
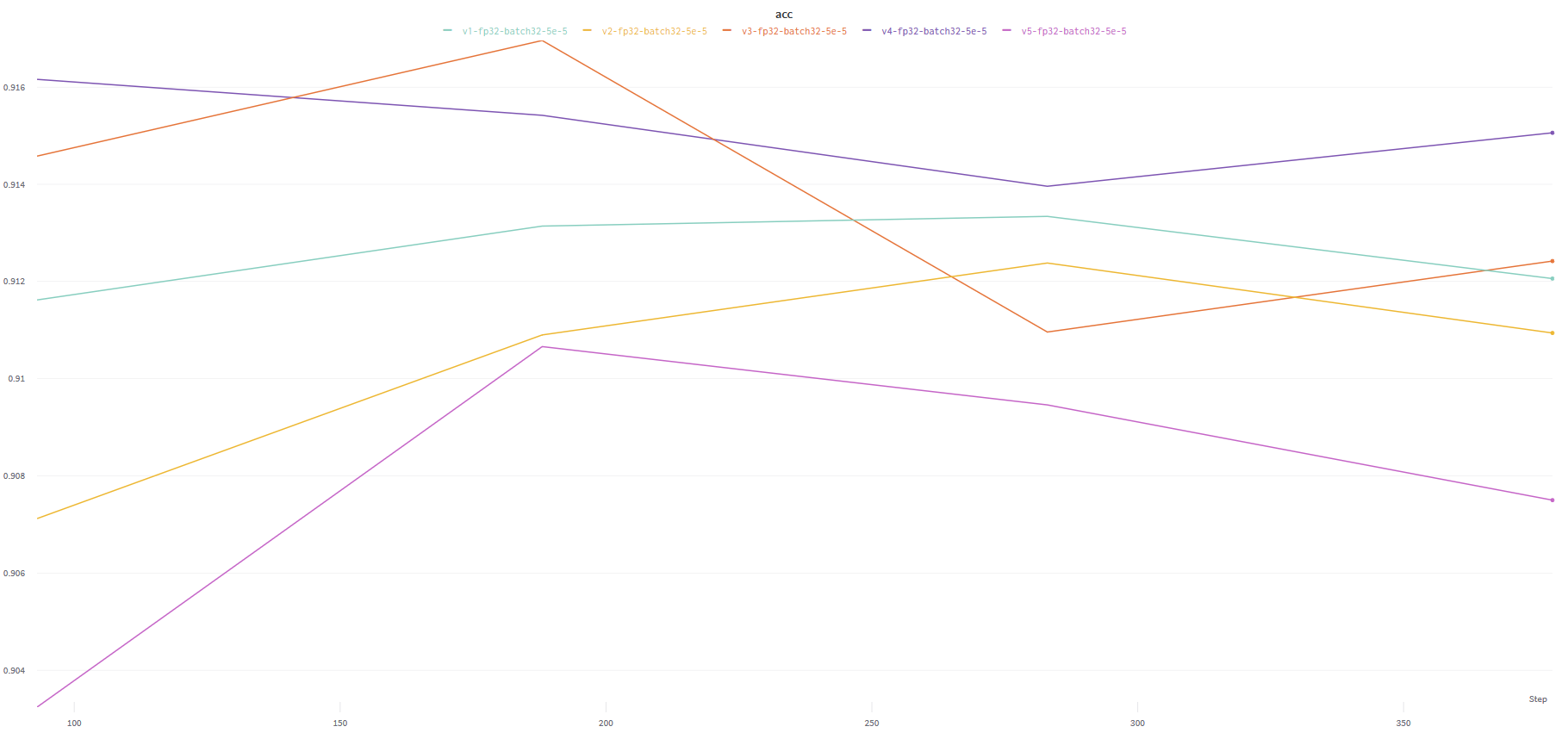
배치 사이즈, 학습률 등의 설정을 조정하여 NSMC 태스크에서 최고 정확도를 91.69%까지 달성하였습니다.
해당 모델은 S3에 업로드 되어 있는 모델 이며, lr은 5e-5 으로 학습하였습니다.
해당 성능 측정은 Simpletransformers 와 wandb 를 사용하여 측정하였습니다.
각 모델들의 상세한 파인튜닝 결과를 제 wandb 페이지 에서 확인하실 수 있습니다.
TensorFlow Research Cloud(TFRC) 의 지원을 받아 Cloud TPU로 모델을 학습하였습니다.
@misc{clark2020electra,
title={ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators},
author={Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
year={2020},
eprint={2003.10555},
archivePrefix={arXiv},
primaryClass={cs.CL}
}@misc{park2020koelectra,
author = {Park, Jangwon},
title = {KoELECTRA: Pretrained ELECTRA Model for Korean},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/monologg/KoELECTRA}}
}