#SpiderKeeper
SpiderKeeper这个项目从最初发布以来,本人也一直在生产环境使用,总的来说对于管理scrapy爬虫的确增强了不少便利,使用中也发现了不少不足的地方,打算近期(有空的话)进行重构,应该会先出个文档或prd。 如果你也想参与或者是有好的意见建议,或者热爱爬虫的小伙伴加交流qq群: 389688974 ,也可以通过issue方式进行告知,我很希望可以和大家一同完善本项目。
SpiderKeeper 是一款基于scrapyd服务的scrapy爬虫管理程序,实现了对scrapy爬虫的可视化管理,包括爬虫的启动与取消,定时抓取任务的设置和周期执行,并可对在运行爬虫的日志,运行状态进行查看。
##截图
spider管理
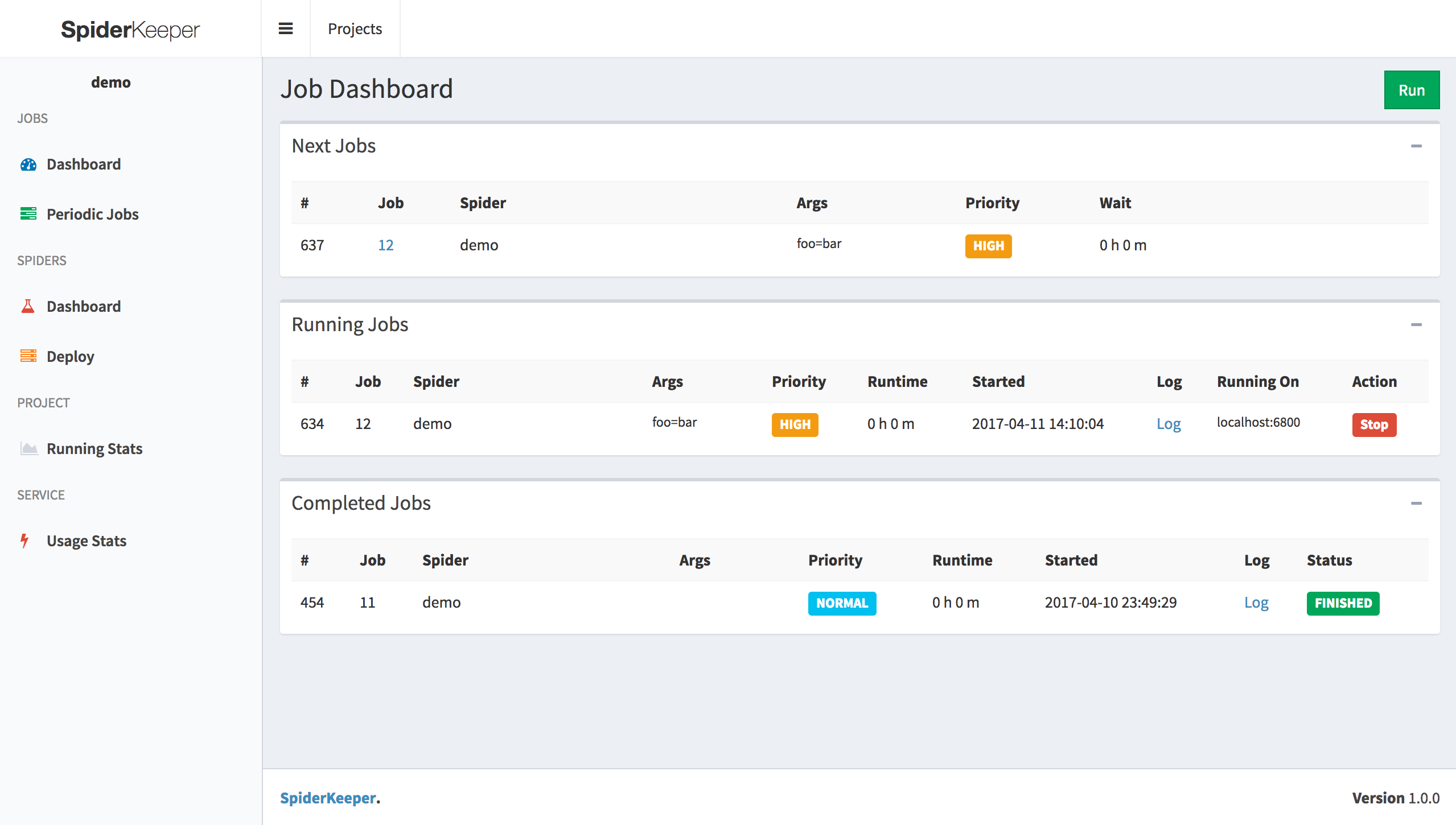 实例选择
实例选择
 运行任务
运行任务
 添加定时任务
添加定时任务
 抓取状态
抓取状态

 查看/取消定时任务
查看/取消定时任务
 服务器状态监控
服务器状态监控

##运行
- 修改 dist/config/config.json , 配置 DaemonService 服务部署地址 , 配置 scrapyd 服务地址
- ~ bash start.sh
##构建
1.安装 [node和npm](http://nodejs.org/)
2.安装 bower `npm install -g bower`
3.安装 grunt `npm install -g grunt`
4.$ `bower install`
5.$ `npm install`
6.Run `grunt build` for build and `grunt serve` for preview.