在破解Amazon的验证码的时候,利用机器学习得到验证码破解精度超过70%,主要是训练样本不够,如果在足够的样本下达到90%是非常有可能的。 update后,样本数为2800多,破解精度达到90%以上,perfect!
-- iconset1
-- ...
-- jpg
-- img
-- jpg
-- ...
-- error.txt
-- py
-- crack.py
pip3 install pillow or easy_install Pillow
1.读取图片,打印图片的结构直方图
遍历出所有的jpg文件,
import os
# 找出文件夹下所有xml后缀的文件
def listfiles(rootdir, prefix='.xml'):
file = []
for parent, dirnames, filenames in os.walk(rootdir):
if parent == rootdir:
for filename in filenames:
if filename.endswith(prefix):
file.append(rootdir + filename)
return file
else:
pass
if __name__ == '__main__':
path = "../jpg/img/"
jpgname = listfiles(path, "jpg")
jpgname为一个数组,将文件夹中的jpg文件全部遍历出来
['../jpg/img/056567f5e15f8d5f46bc5e07905009fd.jpg', '../jpg/img/05796993cf0a3c779b6fe83db2a27ac3.jpg', '../jpg/img/073847b62252c63829850cb1bd49601e.jpg', '../jpg/img/07aafc4694264509135490b85630aaf5.jpg', '../jpg/img/07d126e49e42143e0d21a0dafd522ac8.jpg', '../jpg/img/07dbfd0bd41d11e9475a96bc724e9f56.jpg', '../jpg/img/07fb8e7163e2ebd36e90c209502051ed.jpg', '../jpg/img/08ff7dc78f348ad7e4309eda9588a5f5.jpg', '../jpg/img/09dc3340f3c4a77c61cd18da7b3eca82.jpg', '../jpg/img/0b354ba9e9a132075fcc3dff6f517106.jpg', '../jpg/img/0bdca69fec2089cfaa46b458f5e483c3.jpg', '../jpg/img/0d0b1d778e00a1c84001d5838b9f5ef1.jpg', '../jpg/img/0d14f8838c30f6b54f266d9eb02e1b93.jpg', '../jpg/img/0e8d3e12d36d39314acfcd3bb8c3970a.jpg',...]
读取图片,得到图片的结构直方图
from PIL import Image
for item in jpgname:
newjpgname = []
im = Image.open(item)
print(item)
# jpg不是最低像素,gif才是,所以要转换像素
im = im.convert("P")
# 打印像素直方图
his = im.histogram()
像素直方图打印结果为
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 2, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 1, 2, 0, 1, 0, 0, 1, 0, 2, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 3, 1, 3, 3, 0, 0, 0, 0, 0, 0, 1, 0, 3, 2, 132, 1, 1, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 15, 0, 1, 0, 1, 0, 0, 8, 1, 0, 0, 0, 0, 1, 6, 0, 2, 0, 0, 0, 0, 18, 1, 1, 1, 1, 1, 2, 365, 115, 0, 1, 0, 0, 0, 135, 186, 0, 0, 1, 0, 0, 0, 116, 3, 0, 0, 0, 0, 0, 21, 1, 1, 0, 0, 0, 2, 10, 2, 0, 0, 0, 0, 2, 10, 0, 0, 0, 0, 1, 0, 625]
该数组长度为255,每一个元素代表(0-255)颜色的多少,例如最后一个元素为625,即255(代表的是白色)最多,组合在一起
values = {}
for i in range(0, 256):
values[i] = his[i]
# 排序,x:x[1]是按照括号内第二个字段进行排序,x:x[0]是按照第一个字段
temp = sorted(values.items(), key=lambda x: x[1], reverse=True)
# print(temp)
打印结果为
[(255, 625), (212, 365), (220, 186), (219, 135), (169, 132), (227, 116), (213, 115), (234, 21), (205, 18), (184, 15), (241, 10), (248, 10), (191, 8), (198, 6), (155, 3), (157, 3), (158, 3), (167, 3), (228, 3), (56, 2), (67, 2), (91, 2), (96, 2), (109, 2), (122, 2), (127, 2), (134, 2), (140, 2), (168, 2), (176, 2), (200, 2), (211, 2), (240, 2), (242, 2), (247, 2), (43, 1), (44, 1), (53, 1), (61, 1), (68, 1), (79, 1), (84, 1), (92, 1), (101, 1), (103, 1), (104, 1), (107, 1), (121, 1), (126, 1), (129, 1), (132, 1), (137, 1), (149, 1), (151, 1), (153, 1), (156, 1), (165, 1), (170, 1), (171, 1), (175, 1), (186, 1), (188, 1), (192, 1), (197, 1), (206, 1), (207, 1), (208, 1), (209, 1), (210, 1), (215, 1), (223, 1), (235, 1), (236, 1), (253, 1), (0, 0), (1, 0), (2, 0), (3, 0), (4, 0), (5, 0), (6, 0), (7, 0), (8, 0), (9, 0), (10, 0), (11, 0), (12, 0), (13, 0), (14, 0), (15, 0), (16, 0), (17, 0), (18, 0), (19, 0), (20, 0), (21, 0), (22, 0), (23, 0), (24, 0), (25, 0), (26, 0), (27, 0), (28, 0), (29, 0), (30, 0), (31, 0), (32, 0), (33, 0), (34, 0), (35, 0), (36, 0), (37, 0), (38, 0), (39, 0), (40, 0), (41, 0), (42, 0), (45, 0), (46, 0), (47, 0), (48, 0), (49, 0), (50, 0), (51, 0), (52, 0), (54, 0), (55, 0), (57, 0), (58, 0), (59, 0), (60, 0), (62, 0), (63, 0), (64, 0), (65, 0), (66, 0), (69, 0), (70, 0), (71, 0), (72, 0), (73, 0), (74, 0), (75, 0), (76, 0), (77, 0), (78, 0), (80, 0), (81, 0), (82, 0), (83, 0), (85, 0), (86, 0), (87, 0), (88, 0), (89, 0), (90, 0), (93, 0), (94, 0), (95, 0), (97, 0), (98, 0), (99, 0), (100, 0), (102, 0), (105, 0), (106, 0), (108, 0), (110, 0), (111, 0), (112, 0), (113, 0), (114, 0), (115, 0), (116, 0), (117, 0), (118, 0), (119, 0), (120, 0), (123, 0), (124, 0), (125, 0), (128, 0), (130, 0), (131, 0), (133, 0), (135, 0), (136, 0), (138, 0), (139, 0), (141, 0), (142, 0), (143, 0), (144, 0), (145, 0), (146, 0), (147, 0), (148, 0), (150, 0), (152, 0), (154, 0), (159, 0), (160, 0), (161, 0), (162, 0), (163, 0), (164, 0), (166, 0), (172, 0), (173, 0), (174, 0), (177, 0), (178, 0), (179, 0), (180, 0), (181, 0), (182, 0), (183, 0), (185, 0), (187, 0), (189, 0), (190, 0), (193, 0), (194, 0), (195, 0), (196, 0), (199, 0), (201, 0), (202, 0), (203, 0), (204, 0), (214, 0), (216, 0), (217, 0), (218, 0), (221, 0), (222, 0), (224, 0), (225, 0), (226, 0), (229, 0), (230, 0), (231, 0), (232, 0), (233, 0), (237, 0), (238, 0), (239, 0), (243, 0), (244, 0), (245, 0), (246, 0), (249, 0), (250, 0), (251, 0), (252, 0), (254, 0)]
将占比最多的10个颜色筛选出来
# 占比最多的10种颜色
for j, k in temp[:10]:
print(j, k)
# 255 12177
# 0 772
# 254 94
# 1 40
# 245 10
# 12 9
# 236 9
# 243 9
# 2 8
# 6 8
# 255是白底,0是黑色,可以打印来看看0和254
2.构造新的无杂质图片
生成一张白底啥都没有的图片
# 获取图片大小,生成一张白底255的图片
im2 = Image.new("P", im.size, 255)
利用上一步占比最多的颜色可以看出,255是白底,0是黑色,可以打印来看看0和254

最后证明0是黑色字母,254是斑点,可以舍弃!
将这些颜色根据宽和高的坐标以此写入新生成的白底照片中
# 获取图片大小,生成一张白底255的图片
im2 = Image.new("P", im.size, 255)
for y in range(im.size[1]):
# 获得y坐标
for x in range(im.size[0]):
# 获得坐标(x,y)的RGB值
pix = im.getpixel((x, y))
# 这些是要得到的数字
# 事实证明只要0就行,254是斑点
if pix == 0:
# 将黑色0填充到im2中
im2.putpixel((x, y), 0)
# 生成了一张黑白二值照片
# im2.show()
黑白二值照片

3.切割图片
x代表图片的宽,y代表图片的高 对图片进行纵向切割
# 纵向切割
# 找到切割的起始和结束的横坐标
inletter = False
foundletter = False
start = 0
end = 0
letters = []
for x in range(im2.size[0]):
for y in range(im2.size[1]):
pix = im2.getpixel((x, y))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = x
if foundletter == True and inletter == False:
foundletter = False
end = x
letters.append((start, end))
inletter = False
打印结果为
# [(27, 47), (48, 71), (73, 101), (102, 120), (122, 147), (148, 166)]
(27, 47)代表从x=27到x=47纵向切割成一条状
保存字段到本地,这里就是training_samples.py文件里面的内容,为的就是生成训练样本,这里生成的样本有2800多!
# 保存切割下来的字段
count = 0
for letter in letters:
# (切割的起始横坐标,起始纵坐标,切割的宽度,切割的高度)
im3 = im2.crop((letter[0], 0, letter[1], im2.size[1]))
# 随机生成0-10000的数字
a = random.randint(0, 10000)
# 更改成用时间命名
im3.save("../jpg/letter/%s.gif" % (time.strftime('%Y%m%d%H%M%S', time.localtime()) + str(a)))
count += 1
字段样式
4.训练识别
使用的是 AI与向量空间图像识别
将标准图片转换成向量坐标a,需要识别的图片字段为向量坐标b,cos(a,b)值越大说明夹角越小,越接近重合
空间两向量计算公式
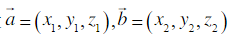
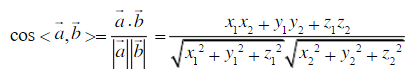
编写的夹角公式为
# 夹角公式
import math
class VectorCompare:
# 计算矢量大小
# 计算平方和
def magnitude(self, concordance):
total = 0
# concordance.iteritems:报错'dict' object has no attribute 'iteritems'
# concordance.items()
for word, count in concordance.items():
total += count ** 2
return math.sqrt(total)
# 计算矢量之间的 cos 值
def relation(self, concordance1, concordance2):
topvalue = 0
# concordance1.iteritems:报错'dict' object has no attribute 'iteritems'
# concordance1.items()
for word, count in concordance1.items():
# if concordance2.has_key(word):报错'dict' object has no attribute 'has_key'
# 改成word in concordance2
if word in concordance2:
# 计算相乘的和
topvalue += count * concordance2[word]
return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2))
转换验证码图片为向量:
# 将图片转换为矢量
def buildvector(im):
d1 = {}
count = 0
for i in im.getdata():
d1[count] = i
count += 1
return d1
打印结果
{0: 255, 1: 255, 2: 255, 3: 255, 4: 255, 5: 255, 6: 255, 7: 255, 8: 255, 9: 255, 10: 255, 11: 255, 12: 255, 13: 255, 14: 255, 15: 255, 16: 255, 17: 255, 18: 255, 19: 255, 20: 255, 21: 255, 22: 255, 23: 255, 24: 255, 25: 255, 26: 255, 27: 255, 28: 255, 29: 255, 30: 255, 31: 255, 32: 255, 33: 255, 34: 255, 35: 255, 36: 255, 37: 255, 38: 255, 39: 255, 40: 255, 41: 255, 42: 255, 43: 255, 44: 255, 45: 255, 46: 255, 47: 255, 48: 255, 49: 255, 50: 255, 51: 255, 52: 255, 53: 255, 54: 255, 55: 255, 56: 255, 57: 255, 58: 255, 59: 255, 60: 255, 61: 255, 62: 255, 63: 255, 64: 255, 65: 255, 66: 255, 67: 0, 68: 0, 69: 0, 70: 255, 71: 255, 72: 255, 73: 255, 74: 0, 75: 0, 76: 0, 77: 255, 78: 0, 79: 255, 80: 255, 81: 0, 82: 0, 83: 0, 84: 0, 85: 0, 86: 0, 87: 255, 88: 255, 89: 0, 90: 255, 91: 255, 92: 255, 93: 0, 94: 0, 95: 255, 96: 0, 97: 255, 98: 0, 99: 255, 100: 255, 101: 0, 102: 0, 103: 0, 104: 0, 105: 0, 106: 0, 107: 255, 108: 255, 109: 0, 110: 0, 111: 0, 112: 0, 113: 0, 114: 255, 115: 255, 116: 255, 117: 0, 118: 0, 119: 0, 120: 255, 121: 0, 122: 255, 123: 255, 124: 255, 125: 0, 126: 0, 127: 0, 128: 255, 129: 0, 130: 0, 131: 255, 132: 255, 133: 0, 134: 0, 135: 0, 136: 255, 137: 0, 138: 0, 139: 0, 140: 0, 141: 0, 142: 0, 143: 255, 144: 255, 145: 0, 146: 0, 147: 0, 148: 0, 149: 0, 150: 0, 151: 255, 152: 255, 153: 255, 154: 255, 155: 0, 156: 0, 157: 0, 158: 255, 159: 255, 160: 255, 161: 255, 162: 255, 163: 255, 164: 255, 165: 255, 166: 255, 167: 255, 168: 255, 169: 255, 170: 255, 171: 255, 172: 255, 173: 255, 174: 255, 175: 255}
加载训练集,且把训练集也变成向量
v = VectorCompare()
iconset = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k',
'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
import os
imageset = []
for letter in iconset:
for img in os.listdir('../iconset1/%s/' % (letter)):
temp = []
if img != "Thumbs.db" and img != ".DS_Store":
temp.append(buildvector(Image.open("../iconset1/%s/%s" % (letter, img))))
imageset.append({letter: temp})
开始识别验证码
# 开始破解训练
count = 0
for letter in letters:
# (切割的起始横坐标,起始纵坐标,切割的宽度,切割的高度)
im3 = im2.crop((letter[0], 0, letter[1], im2.size[1]))
guess = []
# 将切割得到的验证码小片段与每个训练片段进行比较
for image in imageset:
for x, y in image.items():
if len(y) != 0:
guess.append((v.relation(y[0], buildvector(im3)), x))
# 排序选出夹角最小的(即cos值最大)的向量,夹角越小则越接近重合,匹配越接近
guess.sort(reverse=True)
print("", guess[0])
排序选出夹角最小的(即cos值最大)的向量,夹角越小则越接近重合,匹配越接近
guess.sort(reverse=True)
print("", guess[0])
count += 1
运行结果
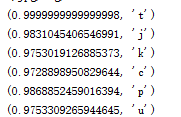
结果显示前面是匹配度,后面是匹配的字母
将图片的名字改成识别后的名字
# 得到拼接后的验证码识别图像
newname = str("".join(newjpgname))
os.rename(item, path + newname + ".jpg")
效果为

更多学习请看python3验证码机器学习