![]()
LDBC SNB Datagen (Spark-based)

The LDBC SNB Data Generator (Datagen) is responsible for providing the datasets used by the LDBC Social Network Benchmark's workloads. The generator is designed to produce directed labelled graphs that mimic the characteristics of those graphs of real data. A detailed description of the schema produced by Datagen, as well as the format of the output files, can be found in the latest version of official LDBC SNB specification document.
📜 If you wish to cite the LDBC SNB, please refer to the documentation repository.
- The Hadoop-based Datagen generates the Interactive SF1-1000 data sets.
- For the BI workload, use the Spark-based Datagen (in this repository).
- For the Interactive workloads's larger data sets, there is no out-of-the-box solution (see this issue).
Generated small data sets are deployed by the CI.
Quick start
Build the JAR
You can build the JAR with both Maven and SBT.
-
To assemble the JAR file with Maven, run:
./tools/build.sh
-
For faster builds during development, consider using SBT. To assemble the JAR file with SBT, run:
sbt assembly
⚠️ When using SBT, change the path of the JAR file in the instructions provided in the README (target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar->./target/scala-2.12/ldbc_snb_datagen-assembly-${DATAGEN_VERSION}.jar).
Install Python tools
Some of the build utilities are written in Python. To use them, you have to create a Python virtual environment and install the dependencies.
E.g. with pyenv and pyenv-virtualenv:
pyenv install 3.7.7
pyenv virtualenv 3.7.7 ldbc_datagen_tools
pyenv local ldbc_datagen_tools
pip install -U pip
pip install ./toolsRunning locally
The ./tools/run.py script is intended for local runs. To use it, download and extract Spark as follows.
Spark 3.1.x
Spark 3.1.x is the recommended runtime to use. The rest of the instructions are provided assuming Spark 3.1.x.
To place Spark under /opt/:
curl https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz | sudo tar -xz -C /opt/
export SPARK_HOME=/opt/spark-3.1.2-bin-hadoop3.2
export PATH="$SPARK_HOME/bin":"$PATH"To place under ~/:
curl https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz | tar -xz -C ~/
export SPARK_HOME=~/spark-3.1.2-bin-hadoop3.2
export PATH="$SPARK_HOME/bin":"$PATH"Both Java 8 and Java 11 are supported.
Once you have Spark in place and built the JAR file, run the generator as follows:
export PLATFORM_VERSION=2.12_spark3.1
export DATAGEN_VERSION=0.5.0-SNAPSHOT
./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar <runtime configuration arguments> -- <generator configuration arguments>Runtime configuration arguments
The runtime configuration arguments determine the amount of memory, number of threads, degree of parallelism. For a list of arguments, see:
./tools/run.py --helpTo generate a single part-*.csv file, reduce the parallelism (number of Spark partitions) to 1.
./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar --parallelism 1 -- --format csv --scale-factor 0.003 --mode interactiveGenerator configuration arguments
The generator configuration arguments allow the configuration of the output directory, output format, layout, etc.
To get a complete list of the arguments, pass --help to the JAR file:
./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar -- --help-
Generating
CsvBasicfiles in Interactive mode:./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar -- --format csv --scale-factor 0.003 --explode-edges --explode-attrs --mode interactive
-
Generating
CsvCompositeMergeForeignfiles in BI mode resulting in compressed.csv.gzfiles:./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar -- --format csv --scale-factor 0.003 --mode bi --format-options compression=gzip
-
Generating CSVs in raw mode:
./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar -- --format csv --scale-factor 0.003 --mode raw --output-dir sf0.003-raw
-
For the
interactiveandbiformats, the--format-optionsargument allows passing formatting options such as timestamp/date formats, the presence/abscence of headers (see the Spark formatting options for details), and whether quoting the fields in the CSV required:./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar -- --format csv --scale-factor 0.003 --mode interactive --format-options timestampFormat=MM/dd/y\ HH:mm:ss,dateFormat=MM/dd/y,header=false,quoteAll=true
To change the Spark configuration directory, adjust the SPARK_CONF_DIR environment variable.
A complex example:
export SPARK_CONF_DIR=./conf
./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar --parallelism 4 --memory 8G -- --format csv --format-options timestampFormat=MM/dd/y\ HH:mm:ss,dateFormat=MM/dd/y --explode-edges --explode-attrs --mode interactive --scale-factor 0.003It is also possible to pass a parameter file:
./tools/run.py ./target/ldbc_snb_datagen_${PLATFORM_VERSION}-${DATAGEN_VERSION}.jar -- --format csv --param-file params.iniDocker image
The Docker image can be built with the provided Dockerfile. To build, execute the following command from the repository directory:
./tools/docker-build.shSee Build the JAR to build the library (e.g. by invoking ./tools/build.sh). Then, run the following:
./tools/docker-run.shElastic MapReduce
We provide scripts to run Datagen on AWS EMR. See the README in the ./tools/emr directory for details.
Larger scale factors
The scale factors SF3k+ are currently being fine-tuned, both regarding optimizing the generator and also for tuning the distributions.
Graph schema
The graph schema is as follows:
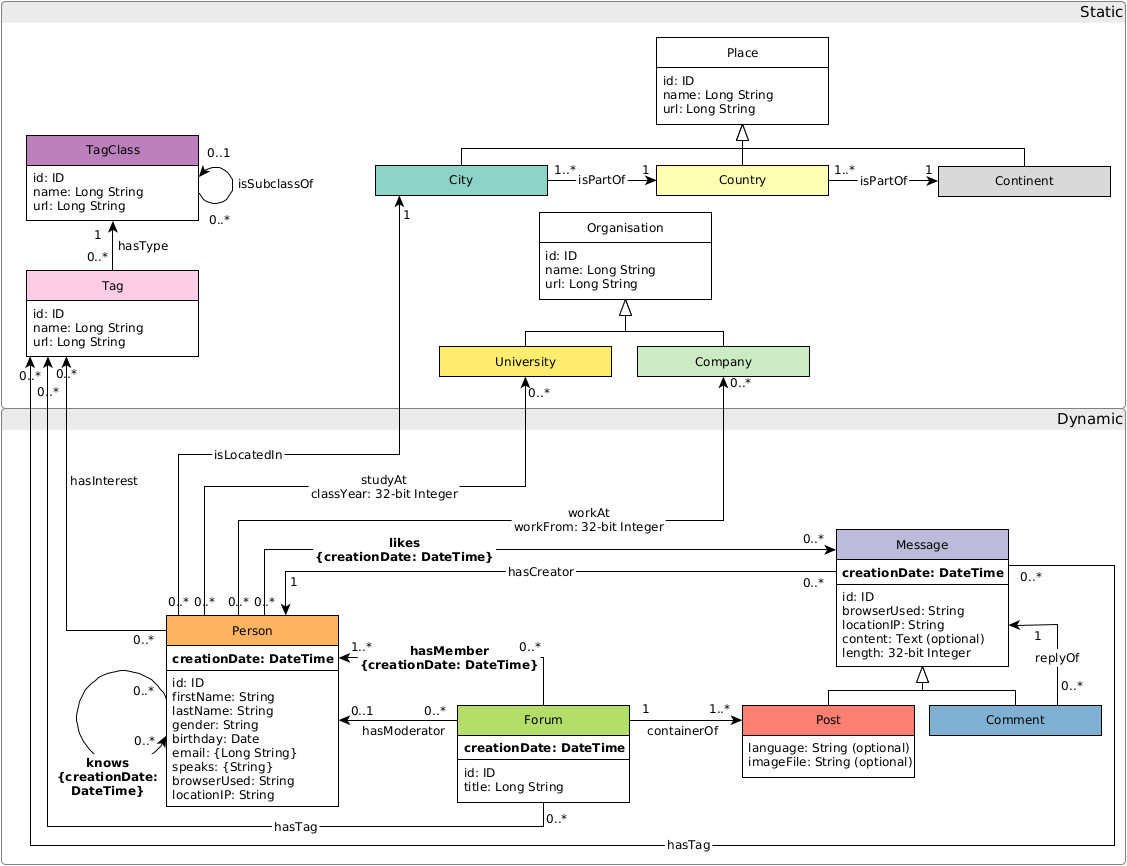
Troubleshooting
- When running the tests, they might throw a
java.net.UnknownHostException: your_hostname: your_hostname: Name or service not knowncoming fromorg.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal. The solution is to add an entry of your machine's hostname to the/etc/hostsfile:127.0.1.1 your_hostname. - If you are using Docker and Spark runs out of space, make sure that Docker has enough space to store its containers. To move the location of the Docker containers to a larger disk, stop Docker, edit (or create) the
/etc/docker/daemon.jsonfile and add{ "data-root": "/path/to/new/docker/data/dir" }, then sync the old folder if needed, and restart Docker. (See more detailed instructions). - If you are using a local Spark installation and run out of space in
/tmp(java.io.IOException: No space left on device), set theSPARK_LOCAL_DIRSto point to a directory with enough free space.