A Knowledge Graph-based Semantic Database for Biomedical Sciences
BioGrakn is a graph-based semantic database that takes advantage of the power of knowledge graphs and machine reasoning to solve problems in the domain of biomedical science.
Biograkn has been built on top of GRAKN.AI, a distributed knowledge graph database which allows complex data modeling, verification, scaling, querying, and analysis.
For further information, you can refer to the paper "BioGrakn: A Knowledge Graph-based Semantic Database for Biomedical Sciences", presented at CISIS-2017, or to this article on DZone.
You can find a ready-to-use binary version of the software here.
Choose a work directory and be sure to download the .jar and the two .gql files containing the ontology and the inference rules.
BioGrakn is built by integrating data available from several databases, such as NCBI Entrez Gene, Gene Ontology, Uniprot Knowledge Base, Reactome, and others.
For your convenience, all the used datasources have been collected and they are available for download from the URL http://194.119.214.173/biograkn/.
Create a destination directory on your computer, e.g., ~/datasources, and then copy the downloaded files into it. Alternatively, use a preferred method of yours to download all the files together. For example, with wget:
$ wget -A .bz2 -r -nd -nv -P ~/datasources http://194.119.214.173/biograkn/
Now, uncompress the files:
$ bunzip2 ~/datasources/*
With GRAKN.AI up and running, load the ontology and the inference rules:
$ cd [YOUR-GRAKN-1.2.0-DIR]
$ ./graql console -k biograkn -f [WORKDIR]/ontology.gql
$ ./graql console -k biograkn -f [WORKDIR]/rules.gql
$ cd [WORKDIR]
Note that you can use an ad-hoc keyspace, such as biograkn used above.
The data import process is handled by the java program BuildBioGrakn contained in the previously downloaded .jar file.
Its usage is briefly explained by running it with -h command line option:
$ java -jar BuildBioGrakn.jar -h
usage: BuildBioGrakn
-d <arg> data source path
-h print this help
-k <arg> keyspace
With no options, the program will use the following default values
| name | value |
|---|---|
| data directory | ~/datasources |
| keyspace | biograkn |
The output should be as follow (except for the execution time, obviously!):
$ java -jar BuildBioGrakn.jar
Building BioGrakn ...
Importing NCBI Gene ........................ done
Importing Gene Ontology ....................... done
Importing Gene2GO ......................... done
Importing miRBase .............................. done
Importing Reactome ..................... done
Importing Reactome2GO ............ done
Importing Reactome2miRNA ............ done
Importing miRCancer .............. done
Importing Uniprot ......................... done
Importing Uniprot2Reactome ......... done
Importing HGNC ........................ done
Importing miRNASNP ............ done
Importing miRTarBase .................... done
BioGrakn built in 0 hours 31 minutes 21 seconds
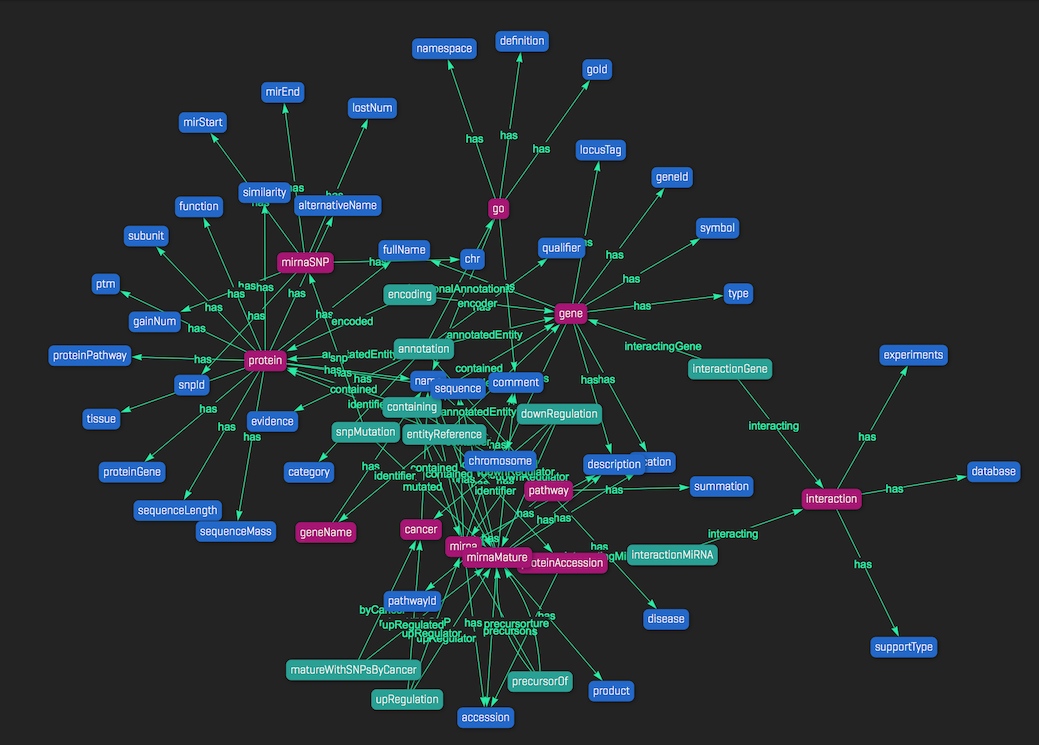
Now, if you open the web visualizer, querying for "all types" will show something like this:
This section shows how to start playing with BioGrakn. Two sample queries are reported:
- Search for genes linked to a particular Gene Ontology annotation
- Search for pathways linked to a particular gene
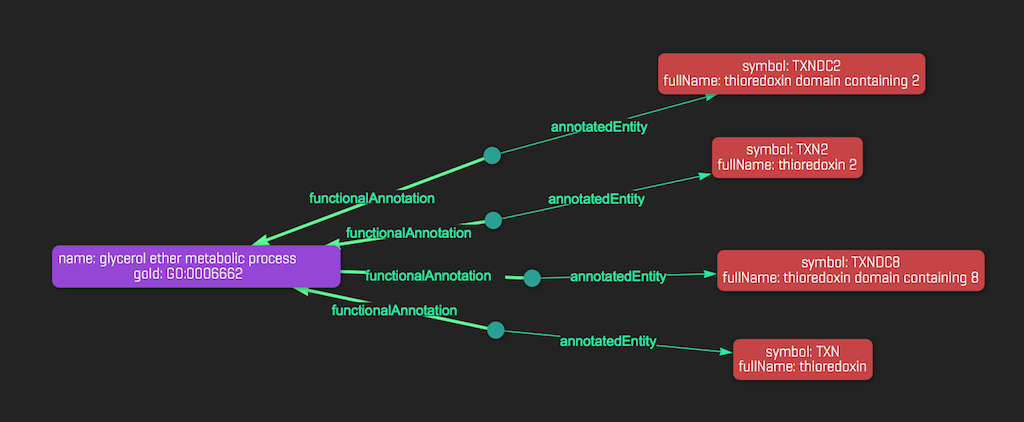
Let's consider the Gene Ontology annotation ”glicocerol ether metabolic process”, that has GO:0006662 as identifier.
In order to find annotated genes, the annotation relation, with the functional annotation member equal to our starting identifier, points out all the related annotated entities, from which we extract the genes, printing their symbols and names.
The following Graql query returns the desired results:
match $go has goId "GO:0006662";
(functionalAnnotation: $go, annotatedEntity: $gene);
$gene isa gene; get;
At a first sight, this seems like the previous problem.
However, genes cannot be directly linked to pathways, because Reactome just provides pathway-to-proteins associations.
Therefore, we have to go through two relations: encoding, that links genes to proteins, and containing, that links pathways to proteins.
The Graql query is then formed as follow:
(to be completed)