探索使用网络安全知识训练大模型,能达到怎样的能力边界。
模型下载
- 基于Baichuan-13B (无道德限制,较好中文支持,显存资源占用小)
- 运行环境:
- webdemo推理: 2*4090(24G)
- lora训练: 3*4090(24G)
- 基于Lora做预训练和SFT训练,优化后的训练代码展示了训练的底层知识,同时大幅减少训练的显存占用,在3*4090上训练。
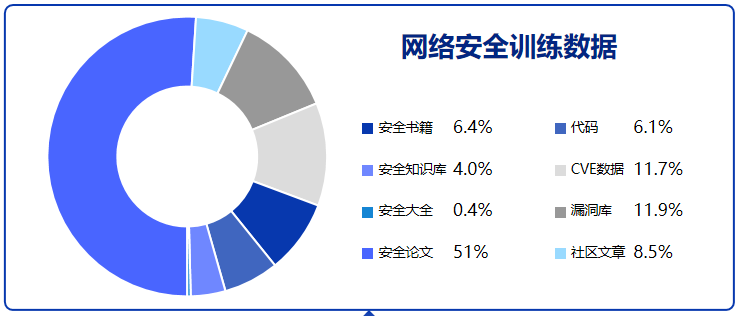
- 预训练数据
- 收集了安全书籍,安全知识库,安全论文,安全社区文章,漏洞库等等安全内容
- 数据集开源地址:https://huggingface.co/datasets/w8ay/security-paper-datasets
- 有监督数据
- chatgpt+人工构造各类有监督安全能力数据集,让模型能了解各类安全指令。

- 思维链:基于思维链方式构造有监督数据集让模型能够根据问题逐步推理到最终答案,展现推理过程。
- 知乎回答:加入了部分高质量知乎数据集,在一些开放性问题上模型能通过讲故事举例子等方式回答答案和观点,更易读懂。
- 为防止灾难性遗忘,有监督数据喂通用能力数据+安全能力数据,数据占比5:1
- chatgpt+人工构造各类有监督安全能力数据集,让模型能了解各类安全指令。


- 修改train.py中超参数信息
# 最大token长度
max_position_embeddings = 2048
# batch size大小
batch_size = 4
# 梯度累积
accumulation_steps = 8
# 训练多少个epoch
num_train_epochs = 10
# 每隔多少步保存一次模型
save_steps = 400
# 每隔多少步打印一次日志
logging_steps = 50
# 学习率
lr = 1e-4
# 预训练模型地址
pre_train_path = "models/Baichuan-13B-Base"
# 训练数据json地址
dataset_paper = "data.json"
train_option = "pretrain"
# lora
use_lora = True
pre_lora_train_path = "" # 如果要继续上一个lora训练,这里填上上一个lora训练的地址
lora_rank = 8
lora_alpha = 32修改
# 预训练模型地址
pre_train_path = "models/Baichuan-13B-Base"
# 训练数据json地址
dataset_paper = "w8ay/secgpt"
train_option = "pretrain"执行
python train.py
修改
# 预训练模型地址
pre_train_path = "models/Baichuan-13B-Base"
# 训练数据json地址
dataset_paper = "sft.jsonl"
train_option = "sft"
pre_lora_train_path = "output/secgpt-epoch-1" # 预训练lora保存目录执行
python train.py
模型结果的输出有着随机性,模型可能知道答案,但是随机后改变输出,这时候可以增加提示词让模型注意力集中,也可以做RLHF强化学习:让模型输出多个结果,选择正确的那个,提升模型效果。
pytho webdemo.py --base_model w8ay/secgpt
自带RLHF选择器,模型会输出三个结果,选择最好的一个记录下来,可对后面RLHF微调模型提供数据参考。


