![]()
![]()
- docker-postgis
- Tagged versions
- Getting the image
- Building the image * Self build using Repository checkout * Alternative base distributions builds * Locales
- Docker secrets
- Running the container
- Connect via psql
- Running SQL scripts on container startup.
- Storing data on the host rather than the container.
- Postgres SSL setup
- Postgres Replication Setup
- Docker image versions
- Support
- Credits
A simple docker container that runs PostGIS
Visit our page on the docker hub at: https://hub.docker.com/r/kartoza/postgis/
There are a number of other docker postgis containers out there. This one differentiates itself by:
- Provides SSL support out of the box and enforces SSL client connections
- Connections are restricted to the docker subnet
- A default database
gisis created for you so you can use this container 'out of the box' when it runs with e.g. QGIS - Streaming replication and logical replication support included (turned off by default)
- Ability to create multiple database when starting the container.
- Ability to create multiple schemas when starting the container.
- Enable multiple extensions in the database when setting it up.
- Gdal drivers automatically registered for pg raster.
- Support for out-of-db rasters.
We will work to add more security features to this container in the future with the aim of making a PostGIS image that is ready to be used in a production environment (though probably not for heavy load databases).
There is a nice 'from scratch' tutorial on using this docker image on Alex Urquhart's blog here - if you are just getting started with docker, PostGIS and QGIS, we recommend that you read it and try out the instructions specified on the blog.
The following convention is used for tagging the images we build:
kartoza/postgis:[POSTGRES_MAJOR_VERSION]-[POSTGIS_MAJOR_VERSION].[POSTGIS_MINOR_RELEASE]
So for example:
kartoza/postgis:14-3.1 Provides PostgreSQL 14.0, PostGIS 3.1
Note: We highly recommend that you use tagged versions because successive minor versions of PostgreSQL write their database clusters into different database directories - which will cause your database to appear to be empty if you are using persistent volumes for your database storage.
There are various ways to get the image onto your system:
The preferred way (but using most bandwidth for the initial image) is to get our docker trusted build like this:
docker pull kartoza/postgis:image_versionTo build the image yourself do:
docker build -t kartoza/postgis git://github.com/kartoza/docker-postgisAlternatively clone the repository and build against any preferred branch
git clone git://github.com/kartoza/docker-postgis
git checkout branch_nameThen do:
docker build -t kartoza/postgis .Or build against a specific PostgreSQL version
docker build --build-arg POSTGRES_MAJOR_VERSION=13 --build-arg POSTGIS_MAJOR=3 -t kartoza/postgis:POSTGRES_MAJOR_VERSION .There are build args for DISTRO (=debian), IMAGE_VERSION (=buster)
and IMAGE_VARIANT (=slim) which can be used to control the base image used
(but it still needs to be Debian based and have PostgreSQL official apt repo).
For example making Ubuntu 20.04 based build (for better arm64 support)
Edit the .env file to change the build arguments
DISTRO=ubuntu
IMAGE_VERSION=focal
IMAGE_VARIANT="" Then run the script
./build.shBy default, the image build will include all locales to cover any value for locale settings such as DEFAULT_COLLATION, DEFAULT_CTYPE or DEFAULT_ENCODING.
You can use the build argument: GENERATE_ALL_LOCALE=0
This will build with the default locate and speed up the build considerably.
With a minimum setup, our image will use an initial cluster located in the
DATADIR environment variable. If you want to use persistence, mount these
locations into your volume/host. By default, DATADIR will point to /var/lib/postgresql/{major-version}.
You can instead mount the parent location like this:
-v data-volume:/var/lib/postgresqlThis default cluster will be initialized with default locale settings C.UTF-8.
If, for instance, you want to create a new cluster with your own settings (not using the default cluster).
You need to specify different empty directory, like this
-v data-volume:/opt/postgres/data \
-e DATADIR:/opt/postgres/data \
-e DEFAULT_ENCODING="UTF8" \
-e DEFAULT_COLLATION="id_ID.utf8" \
-e DEFAULT_CTYPE="id_ID.utf8" \
-e PASSWORD_AUTHENTICATION="md5" \
-e INITDB_EXTRA_ARGS="<some more initdb command args>" \
-v pgwal-volume:/opt/postgres/pg_wal \
-e POSTGRES_INITDB_WALDIR=/opt/postgres/pg_walThe containers will use above parameters to initialize a new db cluster in the specified directory. If the directory is not empty, then the initialization parameter will be ignored.
These are some initialization parameters that will only be used to initialize a new cluster. If the container uses an existing cluster, it is ignored (for example, when the container restarts).
DEFAULT_ENCODING: cluster encodingDEFAULT_COLLATION: cluster collationDEFAULT_CTYPE: cluster ctypeWAL_SEGSIZE: WAL segsize optionPASSWORD_AUTHENTICATION: PASSWORD AUTHENTICATIONINITDB_EXTRA_ARGS: extra parameter that will be passed down toinitdbcommandPOSTGRES_INITDB_WALDIR: parameter to tell Postgres about the initial waldir location. Note: You must always mount persistent volume to this location. Postgres will expect that the directory will always be available, even though it doesn't need the environment variable anymore. If you didn't persist this location, Postgres will not be able to find thepg_waldirectory and consider the instance to be broken.
In addition to that, we have another parameter: RECREATE_DATADIR that can be used to force database reinitializations.
If this parameter is specified as TRUE it will act as explicit consent to delete DATADIR and create
new db cluster.
RECREATE_DATADIR: Force database reinitialization in the locationDATADIR
If you used RECREATE_DATADIR and successfully created a new cluster. Remember
that you should remove this parameter afterwards. Because, if it was not omitted,
it will always recreate new db cluster after every container restarts.
The database cluster is initialised with the following encoding settings
-E "UTF8" --lc-collate="en_US.UTF-8" --lc-ctype="en_US.UTF-8"
or
-E "UTF8" --lc-collate="C.UTF-8" --lc-ctype="C.UTF-8"
If you use default DATADIR location.
If you need to set up a database cluster with other encoding parameters you need to pass the environment variables when you initialize the cluster.
-e DEFAULT_ENCODING="UTF8"-e DEFAULT_COLLATION="en_US.UTF-8"-e DEFAULT_CTYPE="en_US.UTF-8"
Initializing a new cluster can be done by using different DATADIR location and
mounting an empty volume. Or use parameter RECREATE_DATADIR to forcefully
delete the current cluster and create a new one. Make sure to remove parameter
RECREATE_DATADIR after creating the cluster.
See the postgres documentation about encoding for more information.
The container ships with some default extensions i.e. postgis,hstore,postgis_topology,postgis_raster,pgrouting
You can use the environment variable POSTGRES_MULTIPLE_EXTENSIONS to activate a subset
or multiple extensions i.e.
-e POSTGRES_MULTIPLE_EXTENSIONS=postgis,hstore,postgis_topology,postgis_raster,pgrouting`
Note: Some extensions require extra configurations to get them running properly otherwise they will cause the container to exit. Users should also consult documentation relating to that specific extension i.e. timescaledb, pg_cron, pgrouting
Some PostgreSQL extensions require shared_preload_libraries to be specified in the conf files.
Using the environment variable SHARED_PRELOAD_LIBRARIES you can pass comma separated values that correspond to the extensions defined
using the environment variable POSTGRES_MULTIPLE_EXTENSIONS.
The default libraries that are loaded are pg_cron,timescaledb if the image is bulilt
with timescale support otherwise only pg_cron is loaded.
You can pass the env variable
-e SHARED_PRELOAD_LIBRARIES='pg_cron,timescaledb'Note You cannot pass the environment variable SHARED_PRELOAD_LIBRARIES without
specifying the PostgreSQL extension that correspond to the SHARED_PRELOAD_LIBRARIES.
This will cause the container to exit immediately.
You can use the following environment variables to pass a username, password and/or default database name(or multiple databases comma separated).
-
-e POSTGRES_USER=<PGUSER> -
-e POSTGRES_PASS=<PGPASSWORD>Note: You should use a strong passwords. If you are using docker-compose make sure docker can interpolate the password. Example using a password with a$you will need to escape it ie$$ -
-e POSTGRES_DBNAME=<PGDBNAME> -
-e SSL_CERT_FILE=/your/own/ssl_cert_file.pem -
-e SSL_KEY_FILE=/your/own/ssl_key_file.key -
-e SSL_CA_FILE=/your/own/ssl_ca_file.pem -
-e DEFAULT_ENCODING="UTF8" -
-e DEFAULT_COLLATION="en_US.UTF-8" -
-e DEFAULT_CTYPE="en_US.UTF-8" -
-e POSTGRES_TEMPLATE_EXTENSIONS=true -
-e ACCEPT_TIMESCALE_TUNING=TRUEUseful to tune PostgreSQL conf based on timescaledb-tune. Defaults to FALSE. -
-e TIMESCALE_TUNING_PARAMSUseful to configure none default settings to use when runningACCEPT_TIMESCALE_TUNING=TRUE. This defaults to empty so that we can use the default settings provided by thetimescaledb-tune. Exampledocker run -it --name timescale -e ACCEPT_TIMESCALE_TUNING=TRUE -e POSTGRES_MULTIPLE_EXTENSIONS=postgis,hstore,postgis_topology,postgis_raster,pgrouting,timescaledb -e TIMESCALE_TUNING_PARAMS="-cpus=4" kartoza/postgis:14-3.1
Note: ACCEPT_TIMESCALE_TUNING environment variable will overwrite all configurations based
on the timescale configurations
Specifies whether extensions will also be installed in template1 database.
-e SCHEMA_NAME=<PGSCHEMA>You can pass a comma separated value of schema names which will be created when the database initialises. The default behaviour is to create the schema in the first database specified in the environment variablePOSTGRES_DBNAME. If you need to create matching schemas in all the databases that will be created you use the environment variableALL_DATABASES=TRUE
This image uses the initial PostgreSQL values which disables the archiving option by default.
When ARCHIVE_MODE is changed to on, the archiving command will copy WAL files to /opt/archivedir
More info: 19.5. Write Ahead Log
-e ARCHIVE_MODE=off-e ARCHIVE_COMMAND="test ! -f /opt/archivedir/%f && cp %p /opt/archivedir/%f"More info-e ARCHIVE_CLEANUP_COMMAND="pg_archivecleanup /opt/archivedir %r"-e RESTORE_COMMAND='cp /opt/archivedir/%f "%p"'
-e WAL_LEVEL=replicaMore info
Maximum size to let the WAL grow to between automatic WAL checkpoints.
-e WAL_SIZE=4GB-e MIN_WAL_SIZE=2048MB-e WAL_SEGSIZE=1024-e MAINTAINANCE_WORK_MEM=128MB
You can open up the PG port by using the following environment variable. By default, the container will allow connections only from the docker private subnet.
-e ALLOW_IP_RANGE=<0.0.0.0/0> By default
Postgres conf is set up to listen to all connections and if a user needs to restrict which IP address PostgreSQL listens to you can define it with the following environment variable. The default is set to listen to all connections.
-e IP_LIST=<*>
You can also define any other configuration to add to extra.conf, separated by '\n' e.g.:
-e EXTRA_CONF="log_destination = 'stderr'\nlogging_collector = on"
You can alternatively mount an extra config file into the setting's folder i.e
docker run --name "postgis" -v /data/extra.conf:/settings/extra.conf -p 25432:5432 -d -t kartoza/postgisThe /setting folder stores the extra configuration and is copied to the proper directory
on runtime. The environment variable EXTRA_CONF_DIR controls the location of the mounted
folder.
Then proceed to run the following:
docker run --name "postgis" -e EXTRA_CONF_DIR=/etc/conf_settings -v /data:/etc/conf_settings -p 25432:5432 -d -t kartoza/postgisIf you want to reinitialize the data directory from scratch, you need to do:
- Do backup, move data, etc. Any preparations before deleting your data directory.
- Set environment variables
RECREATE_DATADIR=TRUE. Restart the service - The service will delete your
DATADIRdirectory and start reinitializing your data directory from scratch.
During container startup, some lockfile are generated which prevent reinitialisation of some
settings. These lockfile are by default stored in the /settings folder, but a user can control
where to store these files using the environment variable CONF_LOCKFILE_DIR Example
-e CONF_LOCKFILE_DIR=/opt/conf_lockfiles \
-v /data/lock_files:/opt/conf_lockfiles
Note If you change the environment variable to point to another location when you restart the container the settings are reinitialized again.
To avoid passing sensitive information in environment variables, _FILE can be appended to
some of the variables to read from files present in the container. This is particularly useful
in conjunction with Docker secrets, as passwords can be loaded from /run/secrets/<secret_name> e.g.:
-e POSTGRES_PASS_FILE=/run/secrets/<pg_pass_secret>
For more information see https://docs.docker.com/engine/swarm/secrets/.
Currently, POSTGRES_PASS, POSTGRES_USER, POSTGRES_DB, SSL_CERT_FILE,
SSL_KEY_FILE, SSL_CA_FILE are supported.
To create a running container do:
docker run --name "postgis" -p 25432:5432 -d -t kartoza/postgisNote: If you do not pass the env variable POSTGRES_PASS a random password
will be generated and will be visible from the logs or within the container in
/tmp/PGPASSWORD.txt
For convenience, we provide a docker-compose.yml that will run a
copy of the database image and also our related database backup image (see
https://github.com/kartoza/docker-pg-backup).
The docker compose recipe will expose PostgreSQL on port 25432 (to prevent potential conflicts with any local database instance you may have).
Example usage:
docker-compose up -dNote: The docker-compose recipe above will not persist your data on your local disk, only in a docker volume.
Connect with psql (make sure you first install postgresql client tools on your host / client):
psql -h localhost -U docker -p 25432 -lNote: Default postgresql user is 'docker'. If you do not pass
the env variable POSTGRES_PASS a random strong password will be generated
and can be accessed within the startup logs.
You can then go on to use any normal postgresql commands against the container.
Under ubuntu LTS the postgresql client can be installed like this:
sudo apt-get install postgresql-client-${POSTGRES_MAJOR_VERSION}Where POSTGRES_MAJOR_VERSION corresponds to a specific
PostgreSQL version i.e 12
In some instances users want to run some SQL scripts to populate the
database. The environment variable POSTGRES_DB allows
us to specify multiple database that can be created on startup.
When running scripts they will only be executed against the
first database ie POSTGRES_DB=gis,data,sample
The SQL script will be executed against the gis database. Additionally, a lock file is generated in
/docker-entrypoint-initdb.d, which will prevent the scripts from getting executed after the first
container startup. Provide IGNORE_INIT_HOOK_LOCKFILE=true to execute the scripts on every container start.
By default, the lockfile is generated in /docker-entrypoint-initdb.d but it can be overwritten by
passing the environment variable SCRIPTS_LOCKFILE_DIR which can point to another location i.e
-e SCRIPTS_LOCKFILE_DIR=/data/ \
-v /data:/dataCurrently, you can pass .sql, .sql.gz and .sh files as mounted volumes.
docker run -d -v `pwd`/setup-db.sql:/docker-entrypoint-initdb.d/setup-db.sql kartoza/postgisDocker volumes can be used to persist your data.
mkdir -p ~/postgres_data
docker run -d -v $HOME/postgres_data:/var/lib/postgresql kartoza/postgisYou need to ensure the postgres_data directory has sufficient permissions
for the docker process to read / write it.
There are three modalities in which you can work with SSL:
- Optional: using the shipped snakeoil certificates
- Forced SSL: forced using the shipped snakeoil certificates
- Forced SSL with Certificate Exchange: using SSL certificates signed by a certificate authority
By default, the image is delivered with an unsigned SSL certificate. This helps to have an encrypted connection to clients and avoid eavesdropping but does not help to mitigate man in the middle (MITM) attacks.
You need to provide your own, signed private key to avoid this kind of attacks (and make sure clients connect with verify-ca or verify-full sslmode).
Although SSL is enabled by default, connection to PostgreSQL with other clients i.e (PSQL or QGIS) still doesn't enforce SSL encryption. To force SSL connection between clients you need to use the environment variable
FORCE_SSL=TRUEThe following example sets up a container with custom ssl private key and certificate:
docker run -p 25432:5432 -e FORCE_SSL=TRUE -e SSL_DIR="/etc/ssl_certificates" -e SSL_CERT_FILE='/etc/ssl_certificates/fullchain.pem' -e SSL_KEY_FILE='/etc/ssl_certificates/privkey.pem' -e SSL_CA_FILE='/etc/ssl_certificates/root.crt' -v /tmp/postgres/letsencrypt:/etc/ssl_certificates --name ssl -d kartoza/postgis:13-3.1The environment variable SSL_DIR allows a user to specify the location
where custom SSL certificates will be located. The environment variable currently
defaults to SSL_DIR=/ssl_certificates
See the postgres documentation about SSL for more information.
If you are using the default certificates provided by the image when connecting
to the database you will need to set SSL Mode to any value besides
verify-full or verify-ca
The pg_hba.con will have entries like:
hostssl all all 0.0.0.0/0 scram-sha-256 clientcert=0where PASSWORD_AUTHENTICATION=scram-sha-256 and ALLOW_IP_RANGE=0.0.0.0/0
When setting up the database you need to define the following environment variables.
SSL_CERT_FILE:
SSL_KEY_FILE:
SSL_CA_FILE:
Example:
docker run -p 5432:5432 -e FORCE_SSL=TRUE -e SSL_CERT_FILE='/ssl_certificates/fullchain.pem' -e SSL_KEY_FILE='/ssl_certificates/privkey.pem' -e SSL_CA_FILE='/ssl_certificates/root.crt' --name ssl -d kartoza/postgis:13-3.1On the host machine where you need to connect to the database you also
need to copy the SSL_CA_FILE file to the location /home/$user/.postgresql/root.crt
or define an environment variable pointing to location of the SSL_CA_FILE
example: PGSSLROOTCERT=/etc/letsencrypt/root.crt
The pg_hba.conf will have entries like:
hostssl all all 0.0.0.0/0 cert
where ALLOW_IP_RANGE=0.0.0.0/0
Generate the certificates inside the container
CERT_DIR=/ssl_certificates
mkdir $CERT_DIR
openssl req -x509 -newkey rsa:4096 -keyout ${CERT_DIR}/privkey.pem -out \
${CERT_DIR}/fullchain.pem -days 3650 -nodes -sha256 -subj '/CN=localhost'
cp $CERT_DIR/fullchain.pem $CERT_DIR/root.crt
chmod -R 0700 ${CERT_DIR}
chown -R postgres ${CERT_DIR}Set up your ssl config to point to the new location
ssl = true
ssl_cert_file = '/ssl_certificates/fullchain.pem'
ssl_key_file = '/ssl_certificates/privkey.pem'
ssl_ca_file = '/ssl_certificates/root.crt'
Then connect to the database using the psql command:
psql "dbname=gis port=5432 user=docker host=localhost sslmode=verify-full sslcert=/etc/letsencrypt/fullchain.pem sslkey=/etc/letsencrypt/privkey.pem sslrootcert=/etc/letsencrypt/root.crt"The image supports replication out of the box. By default, replication is turned off. The two main replication methods allowed are
- Streaming replication
- Logical replication
Replication uses a dedicated user REPLICATION_USER. The role ${REPLICATION_USER}
uses the default group role pg_read_all_data. You can read more about this
from the PostgreSQL documentation
Note: When setting up replication you need to specify the password using the
environment variable REPLICATION_PASS. If you do not specify it a random strong
password will be generated. This is visible in the startup logs as well
as a text file within the container in /tmp/REPLPASSWORD.txt.
Replication allows you to maintain two or more synchronised copies of a database, with a single master copy and one or more replicant copies. The animation below illustrates this - the layer with the red boundary is accessed from the master database and the layer with the green fill is accessed from the replicant database. When edits to the master layer are saved, they are automatically propagated to the replicant. Note also that the replicant is read-only.
docker run --name "streaming-replication" -e REPLICATION=true -e WAL_LEVEL='replica' -d -p 25432:5432 kartoza/postgis:14.3.2Note If you do not pass the env variable REPLICATION_PASS a random password
will be generated and will be visible from the logs or within the container in
/tmp/REPLPASSWORD.txt
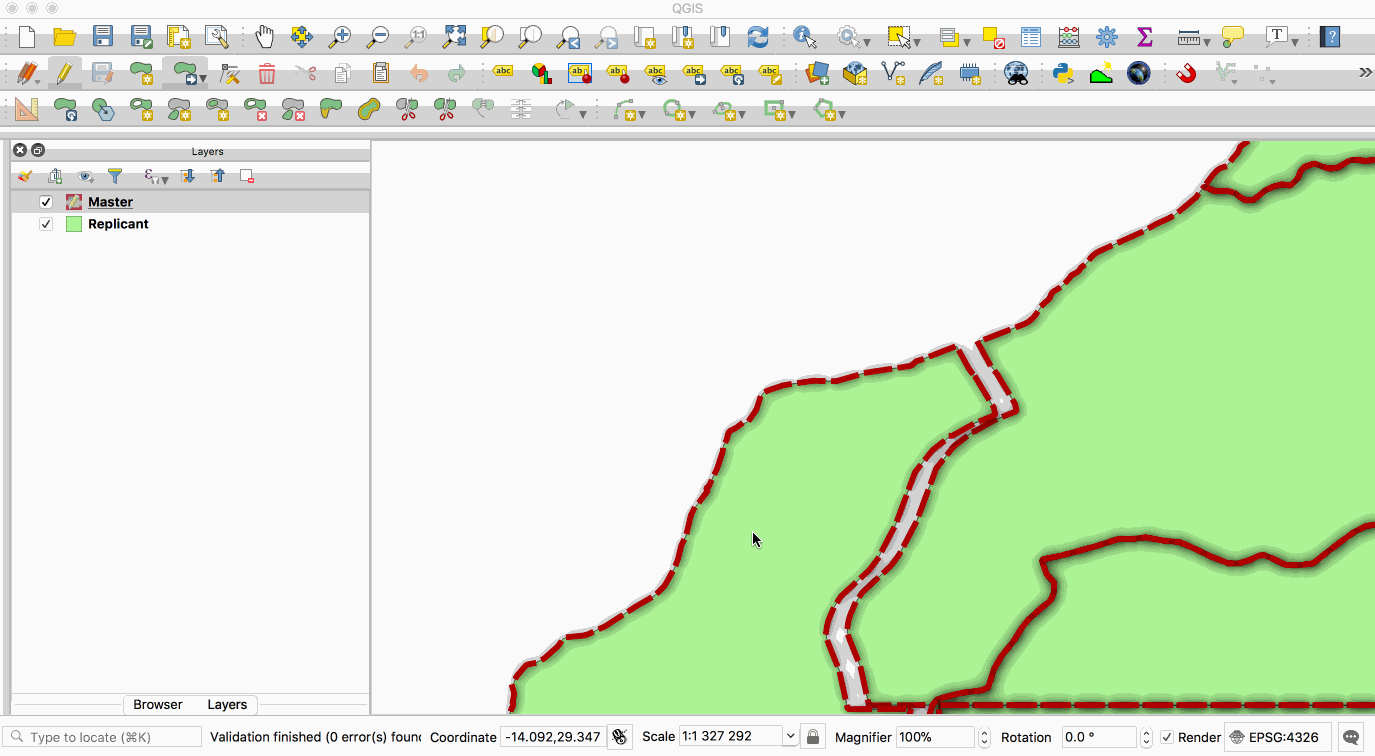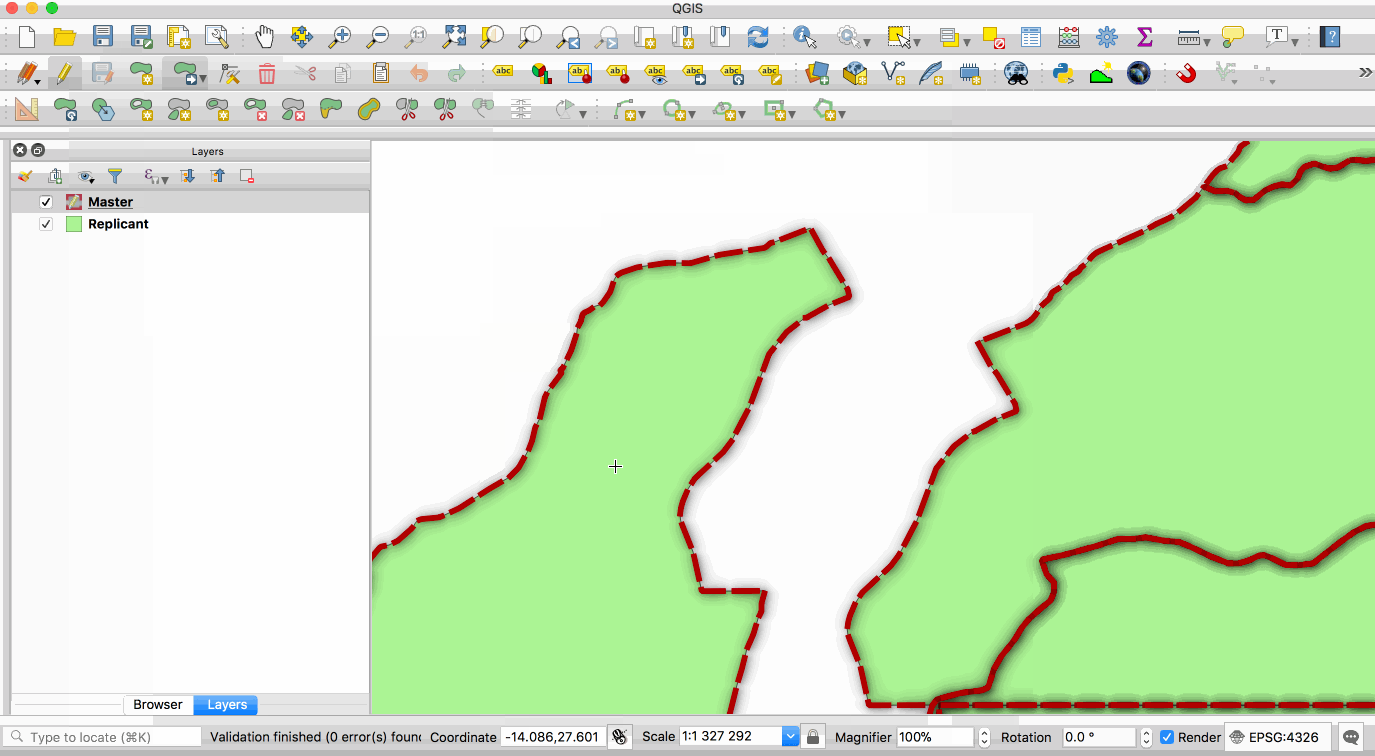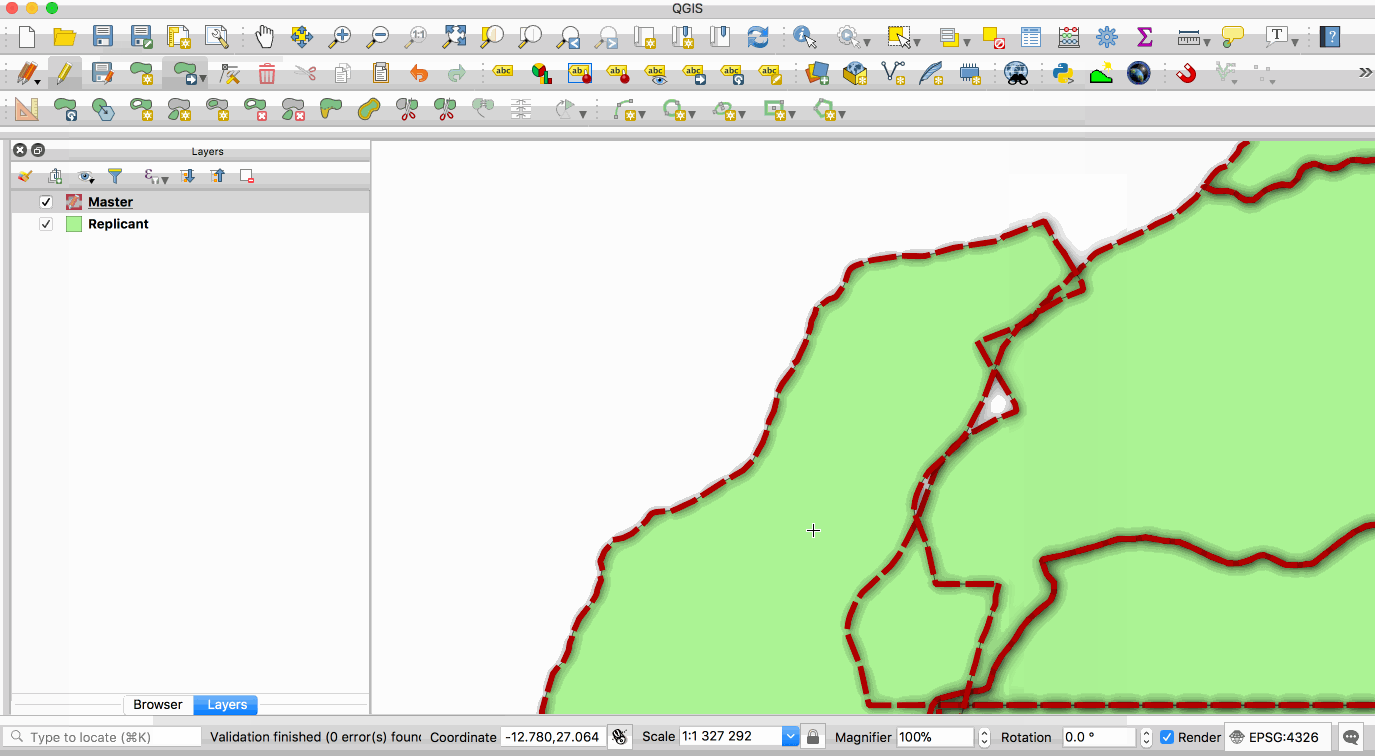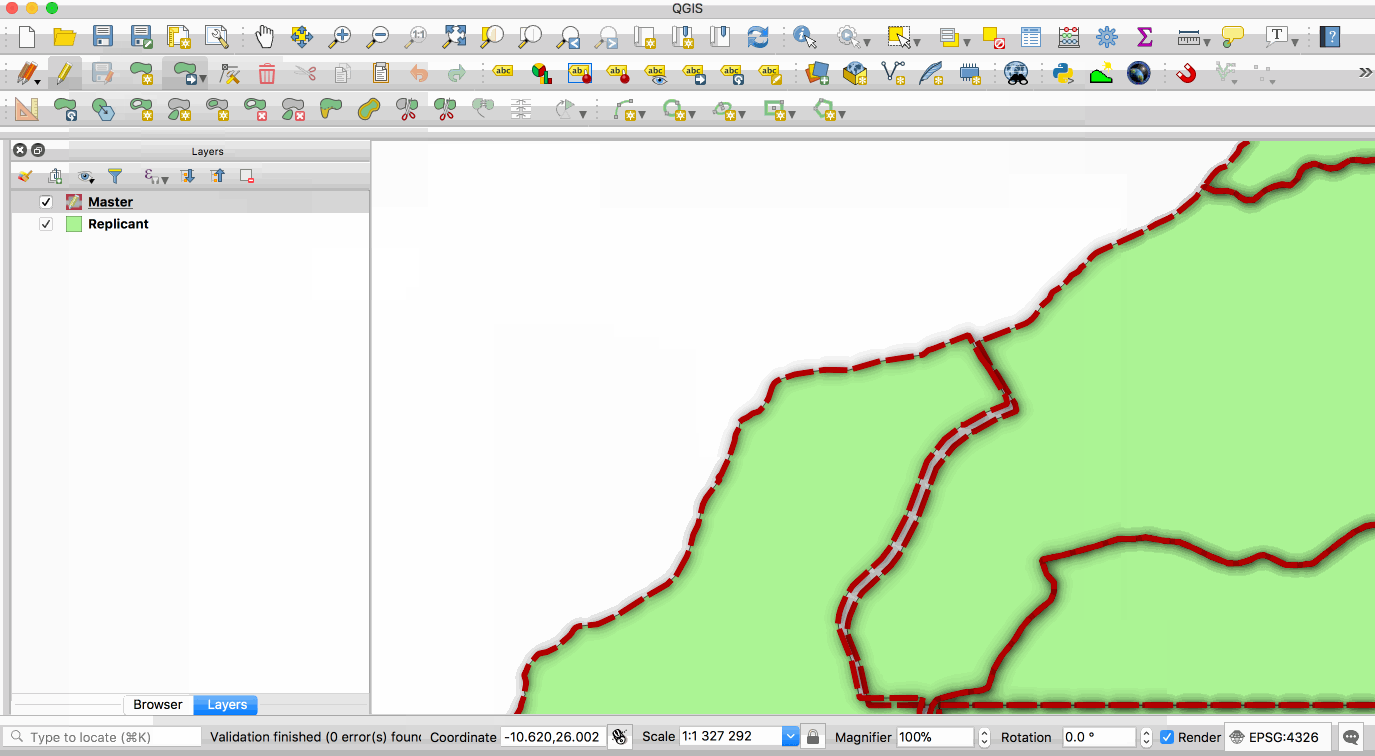
This image is provided with replication abilities. We can
categorize an instance of the container as master or replicant. A master
instance means that a particular container has a role as a single point of
database write. A replicant instance means that a particular container will
mirror database content from a designated master. This replication scheme allows
us to sync databases. However, a replicant is only for read-only transaction, thus
we can't write new data to it. The whole database cluster will be replicated.
Since we are using a role ${REPLICATION_USER}, we need to ensure that it has access to all
the tables in a particular schema. So if a user adds another schema called data
to the database gis he also has to update the permission for the user
with the following SQL assuming the ${REPLICATION_USER} is called replicator
ALTER DEFAULT PRIVILEGES IN SCHEMA data GRANT SELECT ON TABLES TO replicator;Note You need to set up a strong password for replication otherwise the
default password for ${REPLICATION_USER} will default to random generated string
To experiment with the streaming replication abilities, you can see a docker-compose.yml. There are several environment variables that you can set, such as:
Master settings:
- ALLOW_IP_RANGE: A
pg_hba.confdomain format which will allow specified host(s) to connect into the container. This is needed to allow theslaveto connect intomaster, so specifically these settings should allowslaveaddress. It is also needed to allow clients on other hosts to connect to either the slave or the master. - REPLICATION_USER User to initiate streaming replication
- REPLICATION_PASS Password for a user with streaming replication role
Slave settings:
- REPLICATE_FROM: This should be the domain name or IP address of the
masterinstance. It can be anything from the docker resolved name like that written in the sample, or the IP address of the actual machine where you exposemaster. This is useful to create cross machine replication, or cross stack/server. - REPLICATE_PORT: This should be the port number of
masterpostgres instance. Will default to 5432 (default postgres port), if not specified. - DESTROY_DATABASE_ON_RESTART: Default is
True. Set to 'False' to prevent this behaviour. A replicant will always destroy its current database on restart, because it will try to sync again frommasterand avoid inconsistencies. - PROMOTE_MASTER: Default none. If set to any value then the current replicant
will be promoted to master.
In some cases when the
mastercontainer has failed, we might want to use ourreplicantasmasterfor a while. However, the promoted replicant will break consistencies and is not able to revert to replicant anymore, unless it is destroyed and resynced with the new master. - REPLICATION_USER User to initiate streaming replication
- REPLICATION_PASS Password for a user with streaming replication role
To run the example streaming_replication, follow these instructions:
Do a manual image build by executing the build.sh script
./build.shGo into the replication_examples/streaming_replication directory and experiment with the following Make
command to run both master and slave services.
make upTo shut down services, execute:
make downTo view logs for master and slave respectively, use the following command:
make master-log
make node-logYou can try experiment with several scenarios to see how replication works
You can use any postgres database tools to create new tables in master, by
connecting using POSTGRES_USER and POSTGRES_PASS credentials using exposed port.
In the streaming_replication example, the master database was exposed on port 7777.
Or you can do it via command line, by entering the shell:
make master-shellThen make any database changes using psql.
After that, you can see that the replicant follows the changes by inspecting the slave database. You can, again, use database management tools using connection credentials, hostname, and ports for replicant. Or you can do it via command line, by entering the shell:
make node-shellThen view your changes using psql.
You will notice that you cannot make changes in replicant, because it is read-only.
If somehow you want to promote it to master, you can specify PROMOTE_MASTER: 'True'
into slave environment and set DESTROY_DATABASE_ON_RESTART: 'False'.
After this, you can make changes to your replicant, but master and replicant will not be in sync anymore. This is useful if the replicant needs to take over a failover master. However, it is recommended to take additional action, such as creating a backup from the slave so a dedicated master can be created again.
You can optionally set DESTROY_DATABASE_ON_RESTART: 'False' after successful sync
to prevent the database from being destroyed on restart. With this setting you can
shut down your replicant and restart it later, and it will continue to sync using the existing
database (as long as there are no consistencies conflicts).
However, you should note that this option doesn't mean anything if you didn't persist your database volume. Because if it is not persisted, then it will be lost on restart because docker will recreate the container.
To activate the following you need to use the environment variable
WAL_LEVEL=logical to get a running instance like
docker run --name "logical-replication" -e WAL_LEVEL=logical -d kartoza/postgis:13.0For a detailed example see the docker-compose in the folder replication_examples/logical_replication.
All instructions mentioned in the README are valid for the latest running image. Other docker images might have a few missing features than the ones in the latest image. We mainly do not back port changes to current stable images that are being used in production. However, if you feel that some changes included in the latest tagged version of the image are essential for the previous image you can cherry-pick the changes against that specific branch and we will test and merge.
If you require more substantial assistance from kartoza (because our work and interaction on docker-postgis is pro bono), please consider taking out a Support Level Agreeement
- Tim Sutton (tim@kartoza.com)
- Gavin Fleming (gavin@kartoza.com)
- Rizky Maulana (rizky@kartoza.com)
- Admire Nyakudya (admire@kartoza.com)
April 2022