This is an individual substantial work of a real academic research carried out with my supervisor at Queen Mary University of London. My project's scope: software and research.
Title: Classifying Web Complaints to Twitter
Scope: Data Science and Artificial Intelligence
Project description: Twitter is a popular microblogging platform, similar to Weibo. Users can post short messages that are then sent to their ’followers’. If somebody posts a message that contravenes Twitter’s policies, it is possible for third party organisations to send a complaint. We have been gathering these complaints, and have a large dataset containing over 1 million complained about tweets. The project will involve performing a detailed statistical analysis of this dataset to understand its properties, e.g. how gets complained about, what is contained within their tweets, who send complaints, and how are complaints distributed across accounts? Once the statistical analysis is complete, you will then be expected to build a binary classifier that can automatically identify tweets that may receive complaints. As such, this will allow Twitter to predict which tweets may go on to receive complaints.
Keywords: Social media, machine learning, natural language processing
Main tasks:
- Collate existing Twitter datasets which contains complaints
- Perform statistical analysis of complaints to Twitter
- Build classifier to identify tweets that may receive complaints
- Evaluate classifier to profile its precision and recall
Measurable outcomes:
- A collated dataset containing both tweets and complaints
- A classifier that can predict if a tweet might get complaints
- An detailed evaluation of the classifier to show precision and recall
On Twitter, people can post short messages to their followers, which are called tweets. For contents presented on the platform, Twitter has its rules and policy to manage tweets. And Twitter responds to copyright complaints with the guide of the Digital Millennium Copyright Act (DMCA). Web complaint is a common mechanism for reporting offensive content to Twitter.
In practice, the interactions between users, content moderators, and social media platforms are complex and highly strategic. The most frequently applied response strategy to complaints is asking complainants for further information. However, this does not appease the complainants. Significantly, complaints are bearing a great deal of weight, arbitrating both the relationship between users, the platform and the negotiation around contentious public issues. As such, it is necessary to build an intelligent classifier to ease the pressure of scrutiny.
To understand complaint behaviours, the Lumen database collects and analyses complaints on Twitter. It can also request for removal of online materials. (Lumen, 2020) Although one might think Twitter, where users are only allowed to send and read 140-character or fewer text messages, would confront the DMCA regularly, the records on Lumen dataset shows that there are more than 19,000 DMCA notices on Twitter.
| Dataset (csv) | # of Records | Content |
|---|---|---|
| reported_tweet | 737,689 | tweet_id, user_id, JSON format tweet |
| complaint_tweet | 1,863,979 | tweet_id, notice_id, user_id, tweet_url |
| notices | 157,868 | notice_id, notice_type, notice_date_sent, notice_sender_name, notice_action_taken, notice_principal_name, notice_recipient_name |
| Notice Type | Count |
|---|---|
| CourtOrder | 8 |
| DMCA | 157453 |
| Defamation | 4 |
| GovernmentRequest | 148 |
| LawEnforcementRequest | 3 |
| Other | 251 |
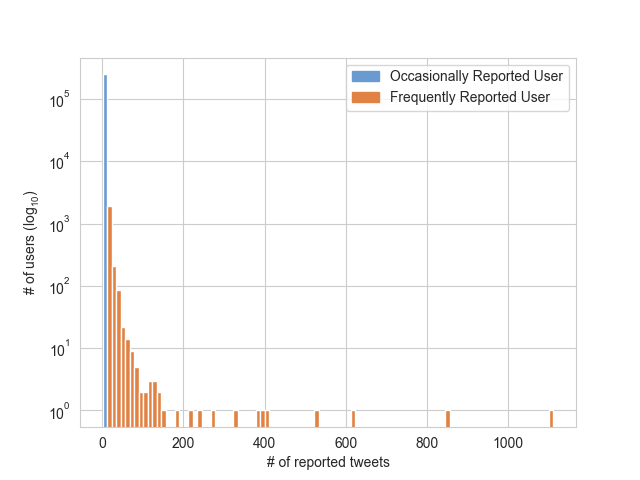


 The project starts by analysing the dataset (Step 1: Characterising datasets). After statistical analysis on the reported tweets, we were able to filter features (Step 2: Prepare data for the classifier) and to build the classifier (Step 3: Building the classifier).
The project starts by analysing the dataset (Step 1: Characterising datasets). After statistical analysis on the reported tweets, we were able to filter features (Step 2: Prepare data for the classifier) and to build the classifier (Step 3: Building the classifier).
In the dataset, we have got 737,689 reported tweets, 1,863,979 complains and 157,868 notices. Each dataset had the relevant attributes well enclosed as :
- Reported tweets: (tweet ID, user ID, Tweet JSON);
- Complaints: (tweet ID, notice ID, user ID, tweet URL);
- Notices: (notice ID, notice type, notice sent date, notice sender name, notice action taken, notice principal name, notice recipient name)
In the dataset of complaints and notices, each complaint has a reported tweets’ ID, as well as a relevant notice ID. The ‘tweet_id’ points to the reported tweet and the ‘notice_id’ points to the notice. Among the attributes of notices. We considered the types of notices would reveal the reason why tweets have received complaints. From the result of counting notice types, we know most tweets were reported because of the Digital Millennium Copyright Act (DMCA), a United States copyright law, and counts 99.7377%.
This led us to think what features in tweets are related to copyrights. In this case, URLs and attached media are a part of copyright products. Additionally, we argue that hashtags and context of tweets would be valuable to discover the topics of tweets and should be chosen as part of the parameters for the classifier.
Among the tremendous long list of features, 10 attributes were chosen:
- ‘friend_count’: The number of users this account is following (i.e. their “followings”).
- ‘follower_count‘: The number of followers this account currently has.
- ‘status_count’: The number of Tweets (including retweets) issued by the user.
- ‘listed_count’: The number of public lists that this user is a member of.
- ‘user_favorites_count’: The number of Tweets this user has liked in the account’s lifetime. British spelling used in the field name for historical reasons.
- ‘retweet_count’: The number of times this Tweet has been retweeted.
- ‘favorite_count’: It indicates approximately how many times this Tweet has been liked by Twitter users.
- ‘urls_num’: The number of URLs included in the text of a Tweet.
- ‘media_num’: The number of photos and video/mp4 in a Tweet.
- ‘mention_users_num’: The number of other Twitter users mentioned in the text of the Tweet.
- Especially, we pick the hashtags from the ‘entities’ object, and ‘hashtags{}’ is a list of hashtag words.
| Name | Type | Note |
|---|---|---|
| friend_count | int | directly from tweet JSON |
| followers_count | int | directly from tweet JSON |
| status_count | int | directly from tweet JSON |
| list_count | int | directly from tweet JSON |
| user_favorites_count | int | directly from tweet JSON |
| retweet_count | int | directly from tweet JSON |
| favorite_count | int | directly from tweet JSON |
| urls_num | int | len(parse_tweet['entities']['urls']) |
| media_num | int | len(parse_tweet['entities']['media']) |
| mention_users_num | int | len(parse_tweet['entities'] |
| hashtags list | unicode | presented as vectors by Word2Vec |
(The first 5 was droped after experiments)
We are having a dataset of all-positive samples regarding complaints. The problem can be defined as a One-Class Classification(OCC) case. One-Class Classification (OCC) is a special case of supervised classification, where the negative examples are absent during training. However, the negative samples may appear during the testing.
In this case, having all the data objects with the same label in the target class is equivalent to having no label. This means the labels are not providing any additional information. Therefore, it can be considered as unsupervised learning. Even though the learning process is unsupervised, the main goal of OCC is classification. OCC can build a discriminative model, such as One-Class SVM or a generative model, such as Autoencoder.
In another aspect, due to the characteristics of datasets, we have the complains which are over 99% copyright cases. What we need to do is to predict the complained ones, especially those might receive complaints because of copyright issue (DMCA). This is a novelty detection learning process. The point is to predict whether the tweets belong to the group of complained tweets (i.e., whether they are within the probability distribution of the original data). Thus, the One-Class SVM was chosen as our classification algorithm, which aims to discriminate between the complained ones and non-complained ones.
One-class SVM uses a kernel method, to map the original space to the feature space, and then draw a ‘circle’ (hyperplane) in the feature space. In the circle, we have the tweets that will be complained. Here, we applied a Gaussian kernel – the Radial Basis Function (RBF) kernel. The choice of the kernel can be automated by optimising a cross-validation based model selection. But, automated choice of kernels and kernel/regularization parameters is a tricky issue, as it is very easy to overfit the model selection criterion (typically cross-validation based). Chances are that we may end up with a worse model than the baseline. Thus, we chose the RBF, since the Radial Basis Function kernel makes a good default kernel.
| Dataset | Time used (seconds) | TP | TN | FP | FN | P | R | F1 |
|---|---|---|---|---|---|---|---|---|
| Training | 3,400.44 | – | – | – | – | – | – | – |
| Testing | 224.52 | 70,197 | 0 | 0 | 8,278 | 1 | 0.89 | 0.94 |
Where:
- TP (Ture Positive): Predict the complained tweets as ‘will be complained’
- TN (True Negative): Predict the non-complained tweets as ‘will not be complained’
- FP (False Positive): Predict the non-complained tweets as ‘will be complained'
- FN (False Negative): Predict the complained tweets as ‘will not be complained’
- P (Precise): The fraction of truly complained tweets among the tweets that were predicted to receive complaints. P=TP/(TP+FP)
- R (Recall): The fraction of tweets that were predicted to receive complaints among all complained tweets. R=TP/(TP+FN)
- F1 Score: The harmonic mean of P and R. F1=(2P×R)/(P+R)
As presented in experiment results, the F1 score of our One-Class SVM was improved by adjusting attributes. With a high score of precise – 1, it can predict whether tweets will receive complaints. And the prediction is reliable because it has a high recall score – 0.89. Overall, the model got an F1 score of 0.94, which proved the classifier’s effectiveness.
To profile the prediction results, we reviewed word clouds of both positive group and negative group (positive – predicted as will be complained; negative – predicted as will not receive complaints).


The positive one is similar to what we plotted for the entire dataset. Hashtags like #PS4share and #WorldCup remains conspicuous in the positive group. On the contrary, #PS4share became invisible in the negative group.
The top10 hashtags in the positive group are ‘ps4share’, ‘music’, ‘fortnite’, ‘worldcup’, ‘cover’, ‘cwc19’, ‘twitch’, ‘dance’, ‘bts’ and ‘dhoni’. Ranks of video game hashtags (‘ps4share’, ‘fortnite’, ‘twitch’ and ‘dhoni’) rose. It indicates that game videos are in the worst-hit region of copyright crisis. Also, hashtags of entertainment copyright is another concern: ‘music’, ‘cover’, ‘bts’, ‘dance’ are related to the use of music. K-pop fandom culture is helping to protect the copyright of those idol groups’ music.
The negative group has more hashtags dispersed in the figure, even though both word clouds were generated with the same parameter settings (max_words=500, max_font_size=200). Comparing to the frequently occurred hashtags in the positive group, like ‘music’, ‘cover’, ‘blackpink’, ‘BTS’ and ‘CWC19’, other words in this word cloud are much smaller. Typical video game vocabularies are not in the negative group. This is a hint that there were more noises in the complaints to music copyrights. Video game copyright issues should be a critical point of web complaints to Twitter.
Additionally, we counted the prediction results by their notice type. Only 9 samples in the testing set receive complaints with reasons other than DMCA. And 6 of them were predicted as negative (will not be complained). Thus, we can say our classifier meets the goal to detect tweets that are more likely to receive complaints because of DMCA problems.
In conclusion, our classifier was successful in predicting DCMA complaints to Twitter. And it can better detect video game copyright crisis than the music/video copyright cases of celebrities.
Environment: Python 2.7
- CSV format reported tweets (10 attributes, no hashtags)
- Hashtags (all hashtag text)
- Plain tweet text (just tweet text, no @ # or links)
- Users (user_id, user_name, user_description)
(notice_id, notice_type)
- Notice type (notice_id, notice_type)
- Notice count (notice_type,count)
- Word cloud
- Word frequency
Extract reported_tweet.csv to reported_tweet_10num.txt Tweet JSON -> JSON of ('tweet_id', 'friend_count', 'followers_count','status_count', 'list_count', 'user_favorites_count', 'retweet_count', 'favorite_count', 'urls_num', 'media_num', 'mention_users_num', 'hashtags')
- Selected features for SVM
- Vectorise data
- Split training set and testing set
- One-Class SVM, record results (predict,tweet_id,)
Same logic as Engineering/one_class_svm_precise_recall_55.py
- Collate results to notice type predict,tweet_id,notice_type
- Collate results to hashtags (predict,tweet_id,notice_type,retweet_count,favorite_count,urls_num,media_num,mention_users_num,hashtags)
- Precise and Recall, F1 Score
- Word Clouds of both positive and negative hashtag groups
- Word Frequency of both positive and negative hashtag groups
Random Forest/ Isolation Forest (Didn't work)