

适用于 Windows7 x64 及以上
这里是记录 Umi-OCR 全新重构版本v2.0的仓库。
- 全新升级:V2版本重构了绝大部分代码,提供焕然一新的界面和更强大的功能。
- 免费:本项目所有代码开源,完全免费。
- 方便:解压即用,离线运行,无需网络。
- 批量:支持批量导入处理图片。也可以即时截屏识别。
- 高效:采用 PaddleOCR / RapidOCR 识别引擎。只要电脑性能足够,可以比在线OCR服务更快。
- 灵活:支持定制界面,支持命令行、HTTP接口等多种调用方式。
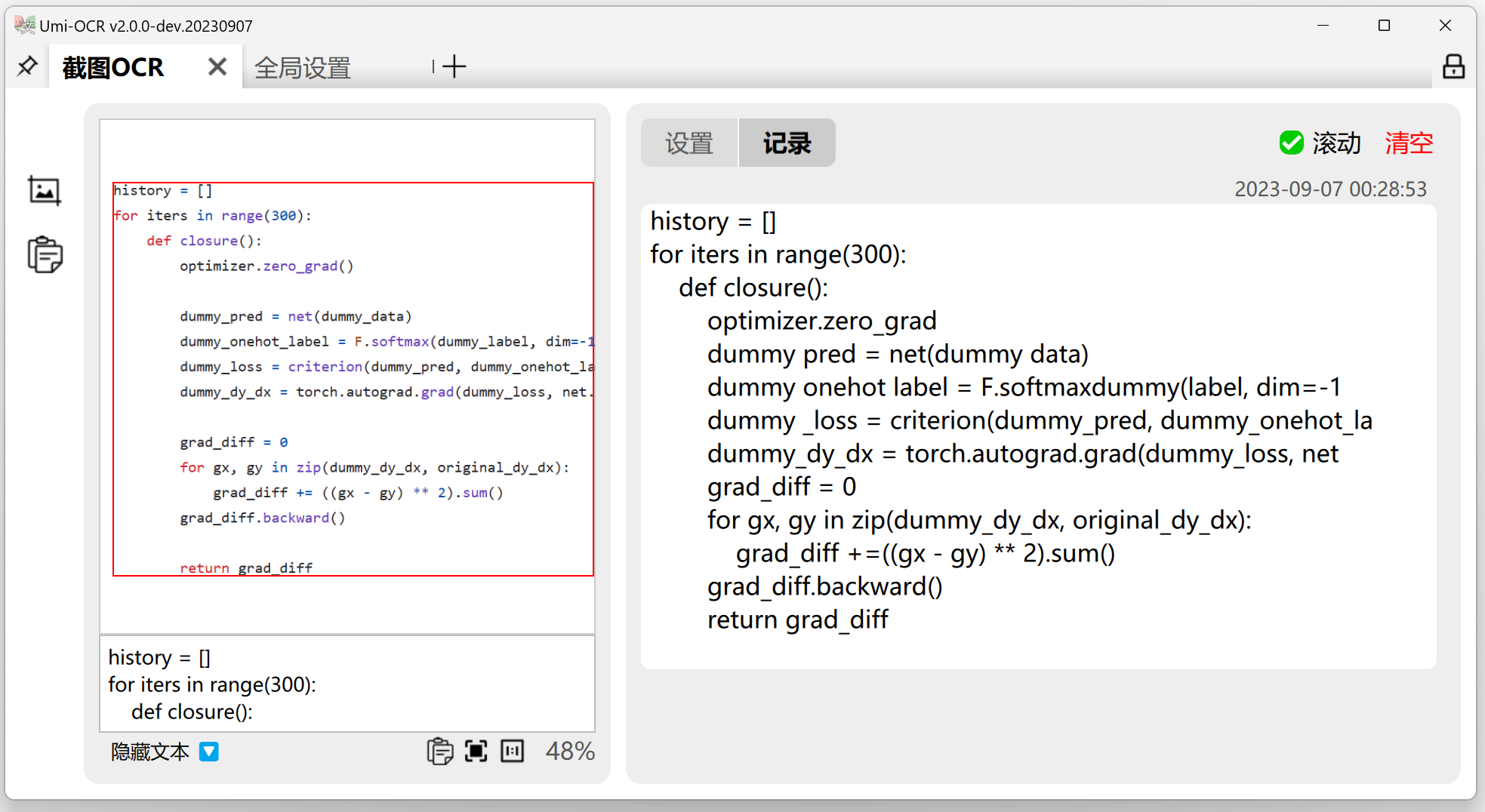
目前 Umi-OCR v2 具有两大主要功能:
- 截图OCR:用快捷键唤起截图,识别截图中的文字。也支持识别剪贴板中的图片。
- 批量OCR:支持批量导入本地图片,将识别的内容保存为 txt / jsonl / md 等多种格式的文件。
一张标签页负责一种主要功能。您可按习惯,打开或关闭不同功能页。
- 多国语言界面:软件界面支持多国语言。目前预览阶段为AI翻译生成,可能词义和排版不好,或者有错漏的情况。正式发布时会进行人工校对。
- 渲染器:软件界面默认支持显卡加速渲染。但是如果在你的机器上出现截屏闪烁、UI错位的情况,请调整
全局设置→界面和外观→渲染器。N卡用户切换为Opengl ES可以达到不错的效果。关闭硬件加速则可以解决大部分UI问题。 - 主题:目前支持切换浅色/深色主题。后期会推出更多主题,及开放自定义主题系统。
- 文本块后处理(段落合并) 可以整理OCR结果的排版和顺序,使文本更适合阅读和使用。预设方案如下:
- 单行:合并同一行的文字,适合绝大部分情景。
- 多行-自然段:智能识别、合并属于同一段落的文字,适合绝大部分情景。
- 多行-代码段:尽可能还原原始排版的缩进与空格。适合识别代码片段,或需要保留空格的场景。
- 竖排:适合竖排排版。需要与同样支持竖排识别的模型库配合使用。
Umi-OCR v2 具有一套强大的命令行控制模式,及开发中的HTTP接口 / Web服务器模式。
命令行调用入口就是主程序 Umi-OCR.exe 。
获取说明:Umi-OCR.exe --help
输入任意指令时,若系统中没有Umi-OCR服务进程在运行,则会自动启动Umi-OCR主进程。
弹出主窗口:Umi-OCR.exe --show
隐藏主窗口:Umi-OCR.exe --hide
关闭软件:Umi-OCR.exe --quit
截屏并获取OCR结果:Umi-OCR.exe --screenshot
粘贴图片,并获取OCR结果:Umi-OCR.exe --clipboard
Umi-OCR 允许通过命令行调用每一个标签页(模块)上的任意函数,但是使用门槛较高。
如果有需要使用高级指令,请阅读下列说明,仔细编写指令。
展开
查询当前已打开的页面,及可以创建的页面模板:Umi-OCR.exe --all_pages
根据页面模板序号,创建新标签页:Umi-OCR.exe --add_page [index]
根据标签页序号,删除已有标签页:Umi-OCR.exe --del_page [index]
每个标签页,通常会具有两个模块,一个是py,一个是qml。每个模块上有不同的函数。
查询当前已打开的模块:Umi-OCR.exe --all_modules
查询某个py模块上有什么可调用的函数:Umi-OCR.exe --call_py [name]
查询某个qml模块上有什么可调用的函数:Umi-OCR.exe --call_qml [name]
--call指令允许只写模块名的首字母。假设一个qml模块叫
ScreenshotOCR_1,那么--call_qml Scre也可以正确调用。
调用py模块上的函数:Umi-OCR.exe --call_py [name] --func [function] [..paras]
调用qml模块上的函数:Umi-OCR.exe --call_qml [name] --func [function] [..paras]
允许在指令最后传入任意个参数,但目前只支持识别为字符串类型。
通过上述的指令调用函数,不会得到函数返回值。因为上述会自动跳转到UI线程运行,避免跨线程调用导致程序崩溃的风险。
如果要取得函数返回值,可以加上 --thread 。如:
Umi-OCR.exe --call_qml [name] --func [function] --thread [..paras]
这样会在子线程同步执行函数,并将返回值输出给命令行。但是子线程执行部分函数可能报错或崩溃。
建议阅读本项目源代码(或发行包中的代码文件)来辅助编写指令。
端口号可以在全局设置中查看及修改。请开启全局设置顶部的高级开关。
目前仅开放一个接口,用于传输命令行指令。
POST /argv- 参数:一个列表,元素均为字符串,格式与命令行指令一致。
- 如:命令行
Umi-OCR.exe --call_qml ScreenshotOCR - 等价于:
POST /argv ["--call_qml", "ScreenshotOCR"]
支持的离线OCR引擎:
- PaddleOCR-json 仅支持Win10 x64以上,性能更好,速度快。
- RapidOCR-json 兼容Win7 x64 ,内存占用低,适合低配机器。
运行环境框架:
- PyStand 的定制版。
已全部完成。
- 标签页框架。
- OCR API控制器。
- OCR 任务控制器。
- 主题管理器,支持切换浅色/深色主题主题。
- 实现 批量OCR。
- 实现 截图OCR。
- 快捷键机制。
- 系统托盘菜单。
- 文本块后处理(排版优化)。
- 引擎内存清理。
- 软件界面多国语言。
- 命令行模式。
- Win7兼容。
近期准备进行的工作,将会在 v2 头几个版本内逐步上线。
- 制订软件界面翻译的开源协作机制。
- Excel输出格式。
- 快捷键权限优化。
- 允许隐藏托盘图标。
- 截图联动/截图翻译。
- 忽略区域。
- PDF识别。
- 批量识别页面的图片预览窗口。
- 高级截图(仿Snipaste,支持贴图)。
- 完善Web服务器功能。
展开
这些是预想中的功能,在开发初期已预留好接口,将在远期慢慢实现。
但开发途中受限于实际情况,可能更改功能设计、新增及取消功能。
- 基于GPU的离线OCR。
- 离线翻译。
- 插件系统。
- 固定区域识别。
- 识别表格图片,输出为Excel。
- 根据系统的深/浅模式,自动切换主题。
- 历史记录系统。
- 兼容 MacOS / Ubuntu 等平台。
- 兼容32位系统。
强烈建议只 clone 主分支,因为某些分支含有体积很大的二进制库,会让你花费很长时间下载。
git clone --branch main --single-branch git@github.com:hiroi-sora/Umi-OCR_v2.git
- Windows
- 跨平台的支持筹备中