This is a sample implementation for the concepts described in the AWS blog post Analyze your Amazon CloudFront access logs at scale using AWS CloudFormation, Amazon Athena, AWS Glue, AWS Lambda, and Amazon Simple Storage Service (S3).
This application is available in the AWS Serverless Application Repository. You can deploy it to your account from there:

The application has two main parts:
-
An S3 bucket
<StackName>-cf-access-logsthat serves as a log bucket for Amazon CloudFront access logs. As soon as Amazon CloudFront delivers a new access logs file, an event triggers the AWS Lambda functionmoveAccessLogs. This moves the file to an Apache Hive style prefix.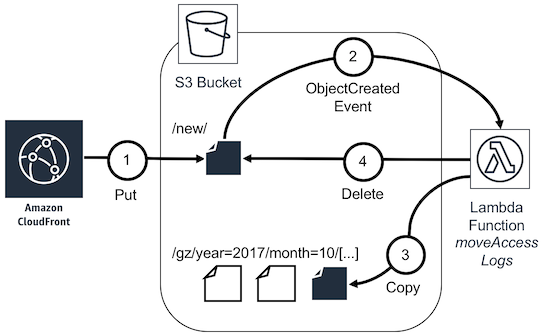
-
An hourly scheduled AWS Lambda function
transformPartitionthat runs a Create Table As Select (CTAS) query on a single partition per run, taking one hour of data into account. It writes the content of the partition to the Apache Parquet format into the<StackName>-cf-access-logsS3 bucket.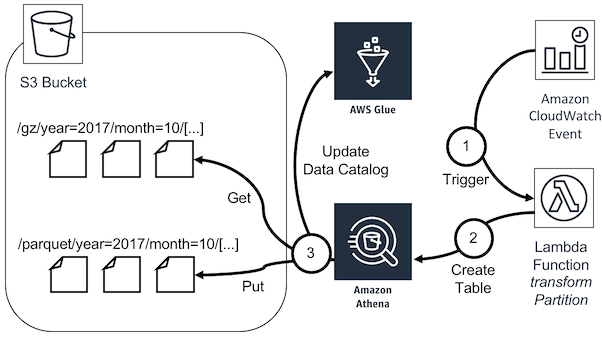


Use the Launch Stack button above to start the deployment of the application to your account. The AWS Management Console will guide you through the process. You can override the following parameters during deployment:
- The
NewKeyPrefix(default:new/) is the S3 prefix that is used in the configuration of your Amazon CloudFront distribution for log storage. The AWS Lambda function will move the files from here. - The
GzKeyPrefix(default:partitioned-gz/) andParquetKeyPrefix(default:partitioned-parquet/) are the S3 prefixes for partitions that contain gzip or Apache Parquet files. ResourcePrefix(default:myapp) is a prefix that is used for the S3 bucket and the AWS Glue database to prevent naming collisions.
The stack contains a single S3 bucket called <ResourcePrefix>-<AccountId>-cf-access-logs. After the deployment you can modify your existing Amazon CloudFront distribution configuration to deliver access logs to this bucket with the new/ log prefix.
As soon Amazon CloudFront delivers new access logs, files will be moved to GzKeyPrefix. After 1-2 hours, they will be transformed to files in ParquetKeyPrefix.
You can query your access logs at any time in the Amazon Athena Query editor using the AWS Glue view called combined in the database called <ResourcePrefix>_cf_access_logs_db:
SELECT * FROM cf_access_logs.combined limit 10;-
Fork this GitHub repository.
-
Clone the forked GitHub repository to your local machine.
-
Modify the templates.
-
Install the AWS CLI & AWS Serverless Application Model (SAM) CLI.
-
Validate your template:
$ sam validate -t template.yaml
-
Package the files for deployment with SAM (see SAM docs for details) to a bucket of your choice. The bucket's region must be in the region you want to deploy the sample application to:
$ sam package --template-file template.yaml --output-template-file packaged.yaml --s3-bucket <BUCKET> -
Deploy the packaged application to your account:
$ aws cloudformation deploy --template-file packaged.yaml --stack-name my-stack --capabilities CAPABILITY_IAM
Deploy another AWS CloudFormation stack from the same template to create a new bucket for different distributions or environments. The stack name is added to all resource names (e.g. AWS Lambda functions, S3 bucket etc.) so you can distinguish the different stacks in the AWS Management Console.
The Launch Stack button above opens the AWS Serverless Application Repository in the US East 1 (Northern Virginia) region. You may switch to other regions from there before deployment.
If you found yourself wishing this set of frequently asked questions had an answer for a particular problem, please submit a pull request. The chances are good that others will also benefit from having the answer listed here.
See the Contributing Guidelines for details.
This sample code is made available under a modified MIT license. See the LICENSE file.