This repository contains code for the paper:
Andrew Owens, Alexei A. Efros. Audio-Visual Scene Analysis with Self-Supervised Multisensory Features. arXiv, 2018
This release includes code and models for:
- On/off-screen source separation: separating the speech of an on-screen speaker from background sounds.
- Blind source separation: audio-only source separation using u-net and PIT.
- Sound source localization: visualizing the parts of a video that correspond to sound-making actions.
- Self-supervised audio-visual features: a pretrained 3D CNN that can be used for downstream tasks (e.g. action recognition, source separation).
- Install Python 2.7
- Install ffmpeg
- Install TensorFlow, e.g. through pip:
pip install tensorflow # for CPU evaluation only
pip install tensorflow-gpu # for GPU support- Install other python dependencies
pip install numpy matplotlib pillow scipy- Download the pretrained models and sample data
./download_models.sh
./download_sample_data.shWe have provided the features for our fused audio-visual network. These features were learned through self-supervised learning. Please see src/shift_example.py for a simple example that uses these pretrained features.
To try the on/off-screen source separation model, run:
python sep_video.py ../data/translator.mp4 --model full --duration_mult 4 --out ../results/This will separate a speaker's voice from that of an off-screen speaker. It will write the separated video files to ../results/, and will also display them in a local webpage, for easier viewing. This produces the following videos (click to watch):
| Input | On-screen | Off-screen |
|---|---|---|
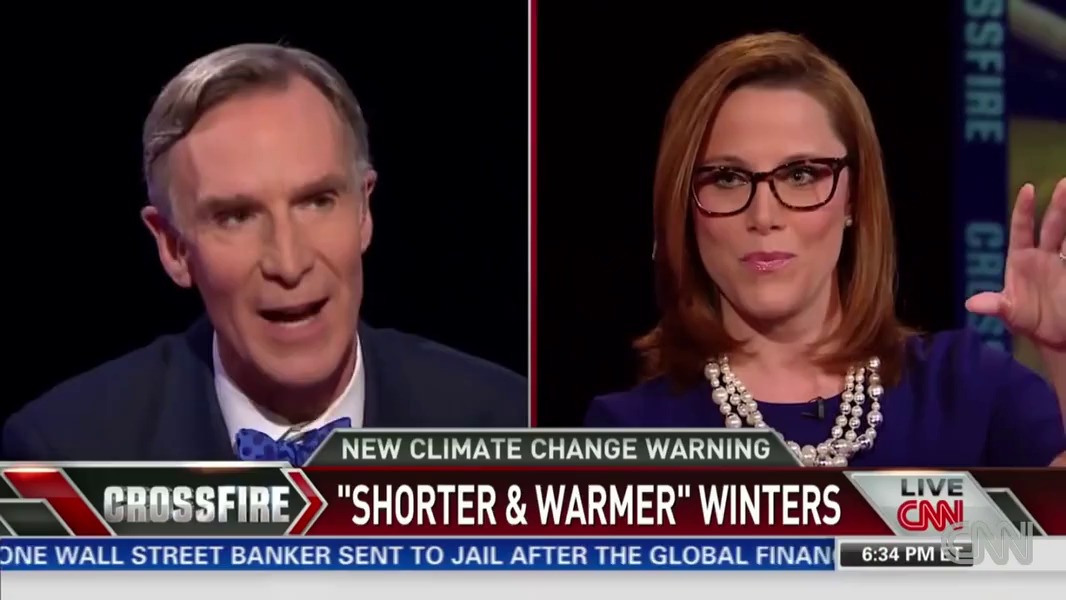
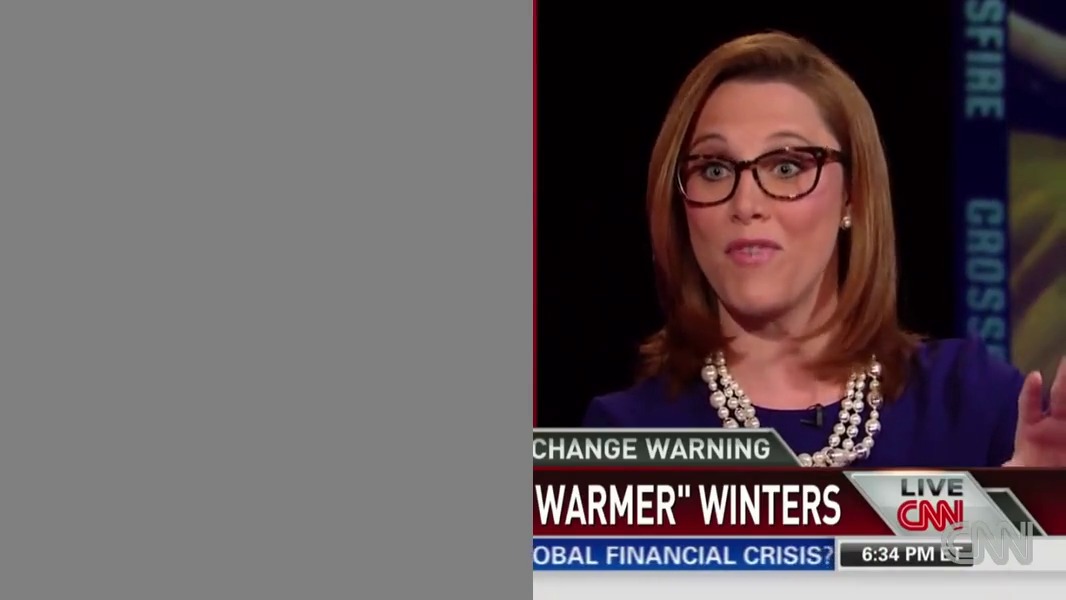
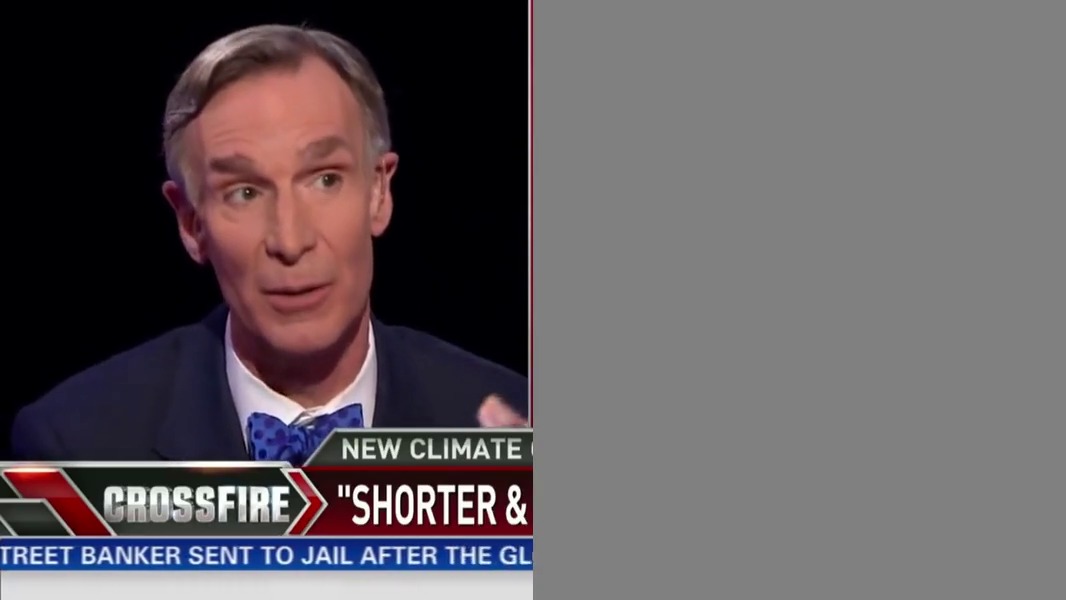
We can visually mask out one of the two on-screen speakers, thereby removing their voice:
python sep_video.py ../data/crossfire.mp4 --model full --mask l --out ../results/
python sep_video.py ../data/crossfire.mp4 --model full --mask r --out ../results/This produces the following videos (click to watch):
| Source | Left | Right |
|---|---|---|
 |
 |
 |
This baseline trains a u-net model to minimize a permutation invariant loss.
python sep_video.py ../data/translator.mp4 --model unet_pit --duration_mult 4 --out ../results/The model will write the two separated streams in an arbitrary order.
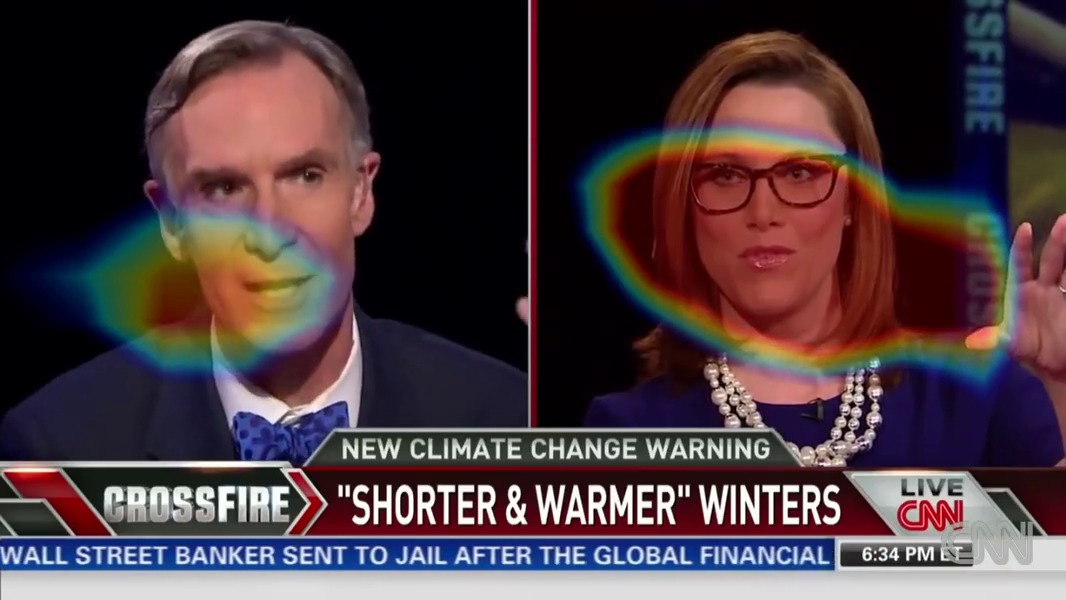
To view the self-supervised network's class activation map (CAM), use the --cam flag:
python sep_video.py ../data/translator.mp4 --model full --cam --out ../results/This produces a video in which the CAM is overlaid as a heat map:
We have provided example code for training an action recognition model (e.g. on the UCF-101 dataset) in videocls.py). This involves fine-tuning our pretrained, audio-visual network. It is also possible to train this network with only visual data (no audio).
If you use this code in your research, please consider citing our paper:
@article{multisensory2018,
title={Audio-Visual Scene Analysis with Self-Supervised Multisensory Features},
author={Owens, Andrew and Efros, Alexei A},
journal={arXiv preprint arXiv:1804.03641},
year={2018}
}
Our u-net code draws from this implementation of pix2pix.