Zdrojové kódy a poznámky ke cvičení z Úvodu do programování.
Stránky přednášky.
Věci probírané na jednotlivých cvičeních najdete na samostatné stránce. Cvičení probíhá rámcově podle kurzu Nauč se Python!. Dokumentace k Pythonu 3.
Cvičení probíhá v jazyku Python 3. Možná jste se setkali, například na Programování pro GIS, s Pythonem 2, pak pozor, jazyky jsou podobné, ale ne stejné, například print v Pythonu 3 se vždy volá se závorkami.
Celkem budou zadány 4 domácí úkoly po 5, 5, 10 a 10 bodech, na zápočet je třeba získat alespoň 23 bodů. Každý domácí úkol bude mít i bonusové části, za které je možné získat body navíc.
Účast na cvičení je dobrovolná, ale v případě přetlaku na konzultace budou mít přednost ti, kteří se cvičení účastní.
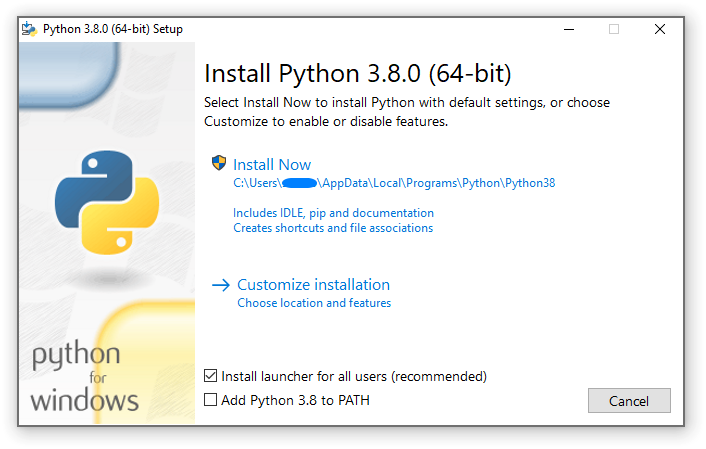
Ať už budeme používat jakékoli vývojové prostředí, je potřeba si nanistalovat interpret Pythonu 3 - program, který vezme váš zdrojový kód, přeloží ho do instrukcí srozumitelných vašemu počítači a postupně ho provádí. Interpret stáhnete například ze stránek Pythonu(zde Latest Python 3 Release a tam dole Windows x86-64 executable installer). Pokud používáte Linux nebo Mac OS a nevíte si rady, napište mi prosím. Při instalaci pak na úplně první obrazovce dole zaškrtněte Add Python 3.10 to PATH, což vám následně umožní Python snadno spouštět.
Vývojové prostředí je program, který nám umožní jednoduše editovat a spouštět zdrojové kódy a dívat se, co naše programy dělají. Jedno vývojové prostředí může být určeno pro více jazyků (Visual Studio Code), nebo jen pro jeden (PyCharm).
Na cvičení budeme programovat v Pythonu 3 v prostředí Visual Studio Code(dále VSCode), stáhněte si ho a následně si ho nastavte pro Python dle návodu. Pro nastavení je potřeba již mít nainstalovaný Python 3. Pro konzultace a rady bude používán Visual Studio Code Live Share, doporučuji si tedy nainstalovat Live Share Extension Pack, lze to přímo z VSCode kliknutím na kostičky v levém sloupci.
Další vhodné prostředí pro Python je PyCharm, můžete si stáhnout zdarma dostupnou Community Edition. Můžete samozřejmě použít i jiná prostředí, pokud jsou vám bližší.
Pokud si potřebujete jen něco menšího vyzkoušet, tak není potřeba instalovat Python a vývojové prostředí, ale můžete si to vyzkoušet online na Programiz online compileru.
Cvičení jsou (zatím) prezenční, konzultace jsou možné po cvičení nebo online, v takovém případě mi prosím napište email.
Viz samostatný soubor.
Pokud ve svém kódu používáte nějaké konstanty, ať už matematické (např. pi), fyzikální nebo jste si jen pevně zvolili délku seznamu či např. rozestup rovnoběžek, je vhodné tyto konstanty na začátku programu pojmenovat a pak používat toto pojmenování místo jejich číselné hodnoty. Je pak jasné, co je v daném místě sémanticky myšleno a pokud se nějakou z konstant později rozhodntete změnit, lze to udělat snadno na jednom dobře definovaném místě.
Konstanty se obvykle pojmenovávají velkými písmeny, víceslovné se oddělují
podtržítkem. Např. LIST_LEN pro délku seznamu (pokud v programu je více
seznamů různých délek, je vhodné přidat do jména jednoznačný identifikátor, ke
kterému seznamu se konstanta vztahuje), F_G = 9.81 pro gravitační zrychlení na
Zemi, REC_DEPTH pro hloubku rekurze. Pokud konstantu importujete z nějakého
modulu, nechte ji takové jméno, jaké má v daném modulu (např. from math import pi).
Funkce by měly používat pouze lokální proměnné, tedy takové proměnné, jaké buď dostaly jako argumenty, nebo byly v dané funkci vytvořeny. V opačném případě, pokud použijete funkci jinde, než bylo původně zamýšleno, může dojít k pádu aplikace nebo neočekávanému chování, protože některé proměnné nemusí existovat.
Funkce je vhodné psát na začátek souboru za importy a definice konstant. Hlavní kód by pak měl být na konci souboru pod všemi funkcemi, aby se s nimi nemíchal a tím pádem nebyla některá jeho část snadno přehlédnutelná. Pokud je v programu více funkcí vztahujících se k podobnému tématu, je vhodné je oddělit do samostatného modulu. Usnadní to pak jejich znovupoužitelnost v dalších programech.
Pokud program bere nějaká data od uživatele, ať už přímo přes input, pomocí
parametrů příkazové řádky nebo načítá ze souboru, je vhodné (pro některé
aplikace, například webové i nutné) takováto data kontrolovat, zda mají správný
formát a obsah. Tyto kontroly je vhodné provést co nejdříve a až po kontrole
všech vstupních dat s nimi zahájit výpočet.
Tento postup má několik výhod:
- Uživatel se dozví hned při spuštění, že data nejsou validní a má možnost data opravit a program spustit znovu. Pokud se po problému dozví po několika hodinách výpočtu, bude jeho práce výrazně méně efektivní
- Výpočetní funkce již nemusí znovu ověřovat validitu dat, mohou se soustředit na samotný výpočet a vstup předpokládat validní. Pokud dojde v rámci úprav kódu k přehození pořadí výpočtů, nehrozí při tom práce s nezkontrolovanými daty.
Na časté kontroly je vhodné si napsat samostatné funkce, například funkci
input_int(quest), která vypíše quest - otázku, kterou se ptáme uživatele,
načte, co uživatel napsal a zkusí to převést na int a podle výsledku buď vrátí
číslo, nebo se zeptá znovu. Obdobně lze vytvořit další pomocné funkce, které
povedou k výraznému zjednodušení získávání dat od uživatele.
Každý program by měl obsahovat alespoň základní uživatelskou dokumentaci, rozsáhlejší programy pak i dokumentaci programátorskou.
Představte si, že kamarádovi vysvětlujete, jak se ten program používá. Kamarád se rámcově orientuje v tématu programu (tedy např. ví, co jsou to válcová zobrazení), ale programovat neumí a chce jen program používat, tedy je vhodné mu říct, jak má co kam zadat, co se případně stane, když něco zadá špatně a co se vypíše a jak to má použít.
Pokud je program rozsáhlejší, píše se i programátorská dokumentace, tedy máte jiného kamaráda, který se opět rámcově orientuje v tématu programu, ale navíc umí programovat. Zdroják vašeho programu ale nikdy neviděl. Tato část dokumentace by tedy měla obsahovat stručný popis běhu programu a stručný popis složitějších funkcí. Také by měla popisovat použité algoritmy. Doplňkem této dokumentace jsou docstringy u jednotlivých funkcí, které říkají vstupní a výstupní parametry každé funkce.
Pokud v programu vytvoříme nějakou proměnnou, uloží se odkaz na ni (u čísel a dalších jednoduchých typů sama proměnná) na zásobník, samotný objekt (bude vysvětleno později, berte to nyní jako její obsah) se uloží do haldy někde v paměti. Pokud zanikne odkaz na tento objekt, tzn. neexistuje v programu proměnná, pomocí které se můžeme k danému objektu dostat, stává se objekt nedosažitelný a časem je z haldy odstraněn. O tuto činnost se stará garbage collector, který běží nezávisle na programu (ale stále je to součást Pythonu) a zde jej dále nebudeme rozebírat. Halda je v principu neomezeně velká (respektive omezená jen dostupnou pamětí), zásobník má omezenou velikost. Pro vytváření proměnných nás to nemusí trápit, ale při rekurzi je potřeba na to myslet.
Pokud z nějakého místa v kódu voláme funkci, musíme provést některé přípravy. Protože je funkce samostatným celkem, který neví, odkud a kdy bude zavolán, je potřeba ji předem někam nachystat argumenty a říct, kde se má pokračovat, když funkce skončí. Také funkce potřebuje dalšímu kódu nějak předat to, co vrací. Pro tyto účely se využívá zásobník:
- na zásobník se uloží, kde pokračovat po skončení funkce (návratová adresa)
- na zásobník se uloží odkazy na argumenty funkce
Následně se začne vykonávat kód funkce, který nejprve vytvoří lokální proměnné
dle názvů argumentů funkce a přiřadí do nich hodnoty ze zásobníku. Poté se
pokračuje příkazy ve funkci. Pokud už není ve funkci další příkaz k vykonání
nebo byl zavolán return, vymaže se celý obsah zásobníku nad návratovou
adresou, pokud funkce něco vrací, tak je odkaz na vracený objekt přidán na
zásobník a skočí se tam, odkud byla funkce volána (což se zjistí z
návratové adresy). Pokud měl být výsledek funkce přiřazen do proměnné, uloží se
do proměnné odkaz ze zásobníku. Nakonec se smaže zásobník po návratovou adresu
včetně a vykonávají se příkazy dále tam, odkud byla funkce volána.
Z výše zmíněného popisu volání funkce vyplývá, že nic nebrání tomu, aby funkce volala sebe samu. Tomuto se říká rekurze. U rekurze je důležité, aby tento řetěz volání sebe sama někdy skončil, jinak dojde k přeplnění zásobníku (stack overflow) a program bude ukončen operačním systémem. K přeplnění dojde proto, že každé volání funkce musí na zásobník uložit alespoň návratovou adresu, tedy zásobník stále roste. Více na webu KSP, v části Programátorské techniky.
Pokud chcete rozšířit funkcionalitu Pythonu nějakým modulem třetí strany,
obvykle se tyto moduly instalují pomocí příkazu pip install <jmeno_modulu>.
Tento příkaz se zadává do terminálového okna dole ve Visual Studio Code,
případně do příkazového řádku emulátoru terminálu (cmd.exe ve Windows). Pokud
jste při instalaci Pythonu zaškrtli Add Python 3.8 to PATH (viz výše), tak by
vše mělo fungovat jednoduše, pokud jste tuto možnost nezaškrtli, musíte zadat
celou cestu k programu pip.exe. Tuto cestu zjistíte například tak, že spustíte
program v Pythonu a podíváte se, co se vám objevilo v terminálu za příkaz.
Zkopírujete cestu začínající obvykle C:\ a končící \python.exe. python.exe
smažete a místo něj napíšete pip.exe install <jmeno_modulu>. Pak by již měla
instalace modulu proběhnout bez problému.