Scrapy爬取腾讯社招信息
目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间。
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛,可用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted 异步网络库来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
网站:
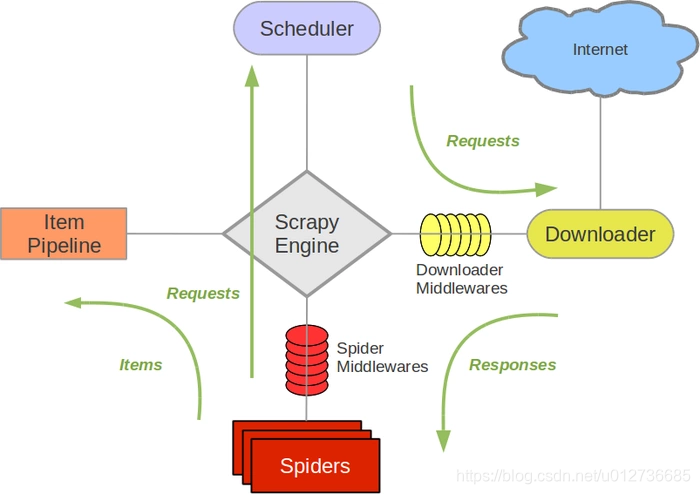
Scrapy主要包括了以下组件:
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心);
- 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址;
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的);
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面;
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
- 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取;
- 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response);
- 然后,爬虫解析Response
- 若是解析出实体(Item),则交给实体管道进行进一步的处理。
- 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
pip install Scrapy
新建一个Scrapy项目,名称为 Test:
scrapy startproject Test则项目目录结构如下:
Test
├── scrapy.cfg
└── Test
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
scrapy.cfg:项目的配置文件Test/:项目的Python模块,将会从这里引用代码Test/items.py:项目的目标文件Test/pipelines.py:项目的管道文件Test/settings.py:项目的设置文件Test/spiders/:存储爬虫代码目录
一般的爬虫步骤:
- 新建项目 (
scrapy startproject xxx):新建一个新的爬虫项目 - 明确目标(编写
items.py):定义提取的结构化数据 - 制作爬虫(
spiders/xxspider.py):制作爬虫开始爬取网页,提取出结构化数据 - 存储内容(
pipelines.py):设计管道存储爬取内容
scrapy startproject Tencent
cd Tencent根据需要爬取的内容定义爬取字段,因为需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间。
# -*- coding: utf-8 -*-
import scrapy
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
class TencentItem(scrapy.Item):
# define the fields for your item here like:
# 职位名
positionname = scrapy.Field()
# 详情连接
positionlink = scrapy.Field()
# 职位类别
positionType = scrapy.Field()
# 招聘人数
peopleNum = scrapy.Field()
# 工作地点
workLocation = scrapy.Field()
# 发布时间
publishTime = scrapy.Field()使用命令创建一个基础爬虫类:
scrapy genspider tencentPostion "tencent.com"其中,tencentPostion为爬虫名,tencent.com为爬虫作用范围。
执行命令后会在 Tencent\spiders 文件夹中创建一个tencentPostion.py的文件,现在开始对其编写:
# -*- coding: utf-8 -*-
import scrapy
from Tencent.items import TencentItem
class TencentpostionSpider(scrapy.Spider):
"""
功能:爬取腾讯社招信息
"""
# 爬虫名
name = 'tencentPostion'
# 爬虫作用范围
allowed_domains = ['tencent.com']
url = 'https://hr.tencent.com/position.php?&start='
offset = 0
# 起始url
start_urls = [url + str(offset)]
def parse(self, response):
for each in response.xpath("//tr[@class='even'] | //tr[@class='odd']"):
# 初始化模型对象
item = TencentItem()
item['positionname'] = each.xpath("./td[1]/a/text()").extract()[0]
item['positionlink'] = each.xpath("./td[1]/a/@href").extract()[0]
if len(each.xpath("./td[2]/text()").extract()) > 0:
item['positionType'] = each.xpath('./td[2]/text()').extract()[0]
else:
item['positionType'] = "None"
item['peopleNum'] = each.xpath("./td[3]/text()").extract()[0]
item['workLocation'] = each.xpath("./td[4]/text()").extract()[0]
item['publishTime'] = each.xpath("./td[5]/text()").extract()[0]
yield item
if self.offset < 2000:
self.offset += 10
# 每次处理完一页的数据之后,重新发送下一页页面请求
# self.offset自增10,同时拼接为新的url,并调用回调函数self.parse处理Response
yield scrapy.Request(self.url + str(self.offset), callback=self.parse, dont_filter=True)遇到的问题:
1、[scrapy] DEBUG:Filtered duplicate request:<GET:xxxx>-no more duplicates will be shown——不会显示更多重复项([参考](https://blog.csdn.net/sinat_41701878/article/details/80302357))
其实这个的问题是,CrawlSpider结合LinkExtractor\Rule,在提取链接与发链接的时候,出现了重复的连接,重复的请求,出现这个DEBUG
或者是yield scrapy.Request(xxxurl,callback=self.xxxx)中有重复的请求
其实scrapy自身是默认有过滤重复请求的,让这个DEBUG不出现,可以有 dont_filter=True,在Request中添加可以解决:
yield scrapy.Request(xxxurl,callback=self.xxxx,dont_filter=True)# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class TencentPipeline(object):
"""
功能:保存item数据
"""
def __init__(self):
self.filename = open("tencent.json", "wb+")
def process_item(self, item, spider):
text = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.filename.write(text.encode("utf-8"))
return item
def close_spider(self, spider):
self.filename.close()Q、TypeError: write() argument must be str, not bytes
情况:使用open打开文件的时候出现了下面的错误。
因为存储方式默认是二进制方式,所以使用二进制方式打开文件。
self.filename = open("tencent.json", "wb+")# 设置请求头部,添加url
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# 设置item——pipelines
ITEM_PIPELINES = {
'tencent.pipelines.TencentPipeline': 300,
}scrapy crawl tencentPosition其中,tencentPosition为爬虫名
运行结果如下:
# 创建项目
scrapy startproject TencentSpider
cd TencentSpider
# 进入项目目录下,创建爬虫文件
scrapy genspider -t crawl tencent tencent.comitem.py等文件不变,主要是爬虫文件(TencentSpider\spider\tencent.py)的编写
# -*- coding: utf-8 -*-
import scrapy
# 导入链接规则匹配类,用来提取符合规则的连接
from scrapy.linkextractors import LinkExtractor
# 导入CrawlSpider类和Rule
from scrapy.spiders import CrawlSpider, Rule
from TencentSpider.items import TencentItem
class TencentSpider(CrawlSpider):
name = 'tencent'
allowed_domains = ['hr.tencent.com']
start_urls = ['https://hr.tencent.com/position.php?&start=0#a']
# Response里链接的提取规则,返回的符合匹配规则的链接匹配对象的列表
pagelink = LinkExtractor(allow=("start=\d+"))
rules = (
# 获取这个列表里的链接,依次发送请求,并且继续跟进,调用指定回调函数处理
Rule(pagelink, callback='parseTencent', follow=True),
)
# 指定的回调函数
def parseTencent(self, response):
for each in response.xpath("//tr[@class='even'] | //tr[@class='odd']"):
item = TencentItem()
item['positionname'] = each.xpath("./td[1]/a/text()").extract()[0]
item['positionlink'] = each.xpath("./td[1]/a/@href").extract()[0]
if len(each.xpath("./td[2]/text()").extract()) > 0:
item['positionType'] = each.xpath('./td[2]/text()').extract()[0]
else:
item['positionType'] = "None"
item['peopleNum'] = each.xpath("./td[3]/text()").extract()[0]
item['workLocation'] = each.xpath("./td[4]/text()").extract()[0]
item['publishTime'] = each.xpath("./td[5]/text()").extract()[0]
yield item