- 01.整体介绍概述
- 1.1 项目背景介绍
- 1.2 遇到问题
- 1.3 基础概念介绍
- 1.4 设计目标
- 1.5 问题答疑和思考
- 02.技术调研说明
- 2.1 语音播放方案
- 2.2 TTS技术分析
- 2.3 语音合成技术
- 2.4 方案选择说明
- 2.5 方案设计思路
- 2.6 文本生成音频
- 03.系统TTS使用实践
- 3.1 如何播放文本
- 3.2 如何循环播放
- 3.3 如何添加播放监听
- 3.4 调整TTS音效
- 3.5 语音合成文件在哪
- 04.TTS功能库设计
- 4.1 设计语音播放通用接口
- 4.2 设计语音播放实体
- 4.3 设计语音播放顺序
- 4.4 设计语音播放分发器
- 4.5 设计语音播放实现类
- 4.6 设计语音播放服务
- 4.7 设计语音播放监听
- 4.7 TTS功能库API调用
- 05.TTS功能库实践
- 5.1 TTS播放功能实现
- 5.2 TTS如何顺序播放
- 5.3 TTS如何实现优先级
- 5.4 如何一键切换类型
- 5.5 多线程播放实践
- 5.6 如何调整语速和语音
- 5.7 如何播放长内容
- 5.8 使用TTS注意要点
- 06.TTS功能库稳定性
- 6.1 边界异常设计
- 6.2 播放异常设计
- 6.3 其他稳定性设计
- 07.系统TTS机制原理
- 7.1 TextToSpeech机制
- 7.2 Speech整体设计
- 7.3 TTS初始化流程
- 7.4 speak播报流程原理
- 7.5 TextToSpeechService
- 硬件设备需要通过tts语音向用户传递信息
- 使用 TTS 技术为用户提供语音反馈。以便用户可以听到内容或响应!
- 问题1:使用系统TTS语音声音听起来可能存在差异
- 不同的 TTS 引擎可能在发音和语调方面存在差异。这可能导致在不同设备上合成的语音听起来不一致,或者某些单词或短语的发音不准确。
- 问题2:TTS在某些机型上不支持
- 某些设备可能没有预装 TTS 引擎,或者用户可能选择禁用或卸载默认的 TTS 引擎。这可能导致应用程序无法使用 TextToSpeech 类进行语音合成。
- 问题3:低端设备引擎效果不佳
- 设备可能提供较低质量的引擎。这可能导致在不同设备上的语音合成质量和效果不一致。
- 问题4:无法支持语音定制功能
- 对于一些高级的定制需求,如更改语音合成的音色、速度、音量等,可能会受到限制。限制灵活性。
- TTS现状和发展
- 语音合成又称文语转换(Text to Speech,TTS)技术,是语音处理领域的一个重要的研究方向,旨在让机器生成自然动听的人类语音。
- 系统TTS(Text-to-Speech)介绍
- TTS 引擎(TTS Engine):TTS 引擎是实际执行文本到语音转换的组件。Android 提供了默认的 TTS 引擎,即 Google Text-to-Speech 引擎。
- TextToSpeech 类:TextToSpeech 类是 Android 提供的 API 类,用于与 TTS 引擎进行交互。它提供了一组方法,用于将文本转换为语音,并控制语音的播放速度、音量等参数。
- 初始化 TTS 引擎:在使用 TTS 功能之前,需要初始化 TTS 引擎。通过创建 TextToSpeech 对象,并传递初始化完成的监听器,可以初始化 TTS 引擎。一旦引擎初始化完成,就可以开始使用 TTS 功能。
- 语音合成:使用 TextToSpeech 类的 speak() 方法可以将文本转换为语音。TTS 引擎将根据指定的参数将文本转换为语音,并通过设备的扬声器播放出来。
- 语音监听器:TextToSpeech 类的 setOnUtteranceProgressListener() 方法可以设置语音合成的监听器。通过设置语音合成的监听器,可以获取语音合成的状态和进度。
- 支持的语言:TTS 引擎支持多种语言,可以通过 setLanguage() 方法设置要使用的语言。需要注意的是,不同的 TTS 引擎可能支持的语言范围有所不同。
- 设计TTS功能库的API目标
- 1.开发者调用tts播放api简单易用
- 2.开发者可以自由切换不同资源播放tts
- 3.可以设置优先级
- 4.可以添加tts播放监听,监听周期
- 代码设计目标准则
- 符合开闭原则:对外拓展是开放的,更改是封闭的。
- 符合接口分离原则:不同层通过抽象接口隔离,针对不同TTS方案抽取通用接口方法,磨平差异性
- 符合类指责分明:类的功能聚合,方便后期维护和迭代修改
- 关于TTS一些问题思考
- TTS技术的工作原理是什么?可以简要解释一下TTS的基本流程吗?
- TTS系统中的文本预处理阶段通常包括哪些步骤?声码器是什么?
- TTS系统中的语音合成是否支持多种语言和语音风格?如何实现多样性的语音输出?
- 高级难度大的问题
- 针对一个长文本内容,如何对长内容进行tts播放。如果让你设计,要注意什么问题?
- 陆续添加10个tts,如何保证按照顺序播放完成。如果中间某个播放异常,该如何处理?
- 系统自带TTS引擎,其核心原理是什么,是通过什么进行发出声音?合成语音质量如何评估?
- 调研后主要的语音播报方案有一下几种:
- 基于第三方的TTS SDK,如百度、思必驰、讯飞等;
- 自研Native的TTS引擎+模型;
- 基于云端的TTS方案;
- 使用手机自带的TTS引擎。
- 不管是市面上那种tts方案,他们实现一般是以下:
- 使用系统提供的 MediaPlayer 类:Android 提供了 MediaPlayer 类,可以用于播放音频文件,包括语音文件。
- 使用 Android TTS(Text-to-Speech)引擎:Android 提供了内置的 TTS 引擎,可以将文本转换为语音并进行播放。
- 使用第三方的 TTS 引擎,如Google的Text-to-Speech引擎(Google Text-to-Speech Engine)、MaryTTS、Flite 等。
- 使用音频流播放:如果您有原始的音频数据,而不是语音文件或文本,您可以使用 Android 的 AudioTrack 类来播放音频流。
- 使用第三方音频播放库:包括 ExoPlayer、VLC Media Player等。这些库提供了更多的功能和灵活性,可以满足更复杂的音频播放需求。
- TTS技术主要分为两种:
- 通用TTS:适用于导航、语音播报、智能客服和大多数语音交互场景;
- 个性化TTS:主要应用于对声音质量较高的教育、长音频、直播以及影视游戏配音等场景中。
- 语音合成模型经过长时间的发展
- 由最初的基于拼接合成,到参数合成,逐渐达到了现阶段感情充沛的基于端到端合成,最新一代端到端合成降低了对语言学知识的要求,可批量实现多语种的合成系统,语音自然程度高。
- 语音合成技术内部分为前端和后端。
- 前端主要负责文本的语音解析和处理,其处理内容主要包括语种、分词、词性预测、多音字处理、韵律预测、情感等。把文本上的发音的这些信息都预测出来之后,将信息送给TTS后端系统,后台声学系统融合这些信息后,将内容转换为语音。
- 后端声学系统从第一代的语音拼接合成,到第二代的语音参数合成,到第三代端到端合成,后端声学系统的智能化程度逐步增加,训练素材需要标记的详细程度和难度也在逐步减弱。
- 客户端实现有三种方案:
- 外采:出于成本考虑,淘汰;
- 自研引擎:语音团队基于参数的合成引擎已完成开发,但是没有人力支撑后续的调试,而播报的话术比较固定,并且对合成声音的音质要求不是特别高,所以选择了一种基于拼接的合成方案作为备选,语句的前部分和后部分使用完整的语音,中间变换部分通过逐字方式合成;
- 手机自带TTS引擎:Android系统已自带了TTS引擎,但是并不是所有的手机都带了中文引擎。
- 语音方面的交互,Android SDK 提供多种方案
- 语音交互的 VoiceInteraction 机制、语音识别的 Recognition 接口、语音播报的 TTS 接口。
- TextToSpeech 机制的优点
- 对于需要使用 TTS 的请求 App 而言: 无需关心 TTS 的具体实现,通过 TextToSpeech API 即用即有
- 对于需要对外提供 TTS 能力的实现 Engine 而言,无需维护复杂的 TTS 时序和逻辑,按照 TextToSpeechService 框架的定义对接即可,无需关心系统如何将实现和请求进行衔接
- 针对TTS功能库的设计
- 不管是通过系统TTS,还是音频Player,或者是外带方案,这里创建播放tts语音的统一api接口。磨平不同技术实现的差异性!
- 实现综合性TTS播放功能库
- 支持系统TTS播放:使用系统自带TextToSpeech来实现,主要是针对文本内容tts。
- 支持系统音频TTS播放:使用MediaPlayer来实现,主要是针对本地音频文件,比如mp3等资源tts。
- 支持网络音频TTS播放:使用谷歌ExoPlayer来实现,主要是针对网络资源文件tts。
- 通过文本生成音频文件的平台有哪些
- 讯飞音频制作【收费,音效多】:https://www.xfzhizuo.cn/make
- 配音鹅【收费,音效多】:https://home.peiyine.com/pye/ai
- 马克配音【免费,使用简单】:https://ttsmaker.cn/
- 如何进行播放?直接调用speak即可播放
textToSpeech.speak(tts, TextToSpeech.QUEUE_FLUSH, null);
- 循环播放语音
- 想让他报个2-3遍或者循环播报的时候,我们来试一下
for (int i=0 ; i<5 ; i++){ textToSpeech.speak("简单播放tts,"+i, TextToSpeech.QUEUE_FLUSH, null); }- 简单的不行,但是问题来了,一段长的文字他只播报前面几个字,然后又重新开始播报。
- 这是因为textToSpeech.speak(tts, TextToSpeech.QUEUE_FLUSH, null);这个方法会自动关闭掉上面一个播报的内容,从而进行新一轮的播报。
- 播放完成后再播放
- 要等上一条播报完整了再进行播报,该如何操作呢?那么可以TTS有 isSpeaking() 这个方法
for (int i=0 ; i<5 ; i++){ if (!textToSpeech.isSpeaking()){ textToSpeech.speak("简单播放tts,"+i, TextToSpeech.QUEUE_FLUSH, null); } }- 这样就可以播全了嘛? 非也,for循环飞快的跑只要发现在speaking那么直接跳过开始走下一个i
- 如何正确循环播放。这样就相当于在一个消息队列然后进行循环的播报。
for (int i=0 ; i<5 ; i++){ textToSpeech.speak("简单播放,"+i, TextToSpeech.QUEUE_ADD, null); }
- 关于监听tts状态如下所示:
private final class OnCompleteListener extends UtteranceProgressListener { /** * 播放完成。这个是播报完毕的时候 每一次播报完毕都会走 */ @Override public void onDone(final String utteranceId) { } /** * 播放异常 */ @Override public void onError(final String utteranceId) { } /** * 播放开始。这个是开始的时候。是先发声之后才会走这里 */ @Override public void onStart(final String utteranceId) { } }
- 任意 App 都可以方便地采用系统内置或第三方提供的 TTS Engine 进行播放铃声提示、语音提示的请求
- Engine 可以由系统选择默认的 provider 来执行操作,也可由 App 具体指定偏好的目标 Engine 来完成。
- 可以在设置中选择发音音色。在系统设置---辅助功能---无障碍---文本转语音路径
- 可以调整语速,这个时候使用textToSpeech播放语速就会发生变化;
- 可以调整音调,这个时候使用textToSpeech播放音调就会发生变化;
- 先说结果,语音合成文件可以指定,如下代码所示
//指定文件地址 wavPath = Environment.getExternalStorageDirectory() + "/temp.wav"; //添加文本内容 map.put(TextToSpeech.Engine.KEY_PARAM_UTTERANCE_ID, content); //使用指定的参数将给定的文本合成为文件。该方法是异步的,即该方法只是将请求添加到TTS请求队列中,然后返回。 //当此方法返回时,合成可能还没有完成(甚至还没有开始!)。 int r = mSpeech.synthesizeToFile(content, map, wavPath); - 如果是没有指定,那么合成的tts文件究竟在哪里呢?
- 系统TextToSpeech合成的TTS文件实际上是存储在设备的内部存储中的。通常存储在以下路径中:/data/data/com.google.android.tts/files/voices/
- 其中,"/data/data/"是设备的内部存储路径,"com.google.android.tts"是Google Text-to-Speech引擎的包名。
- 在这个目录下,你可以找到已安装的TTS语音包的文件,每个语音包通常由多个文件组成,包括声音文件、配置文件等。
- 关于tts音频播放,不管采用那种方式。这里可以设计通用接口
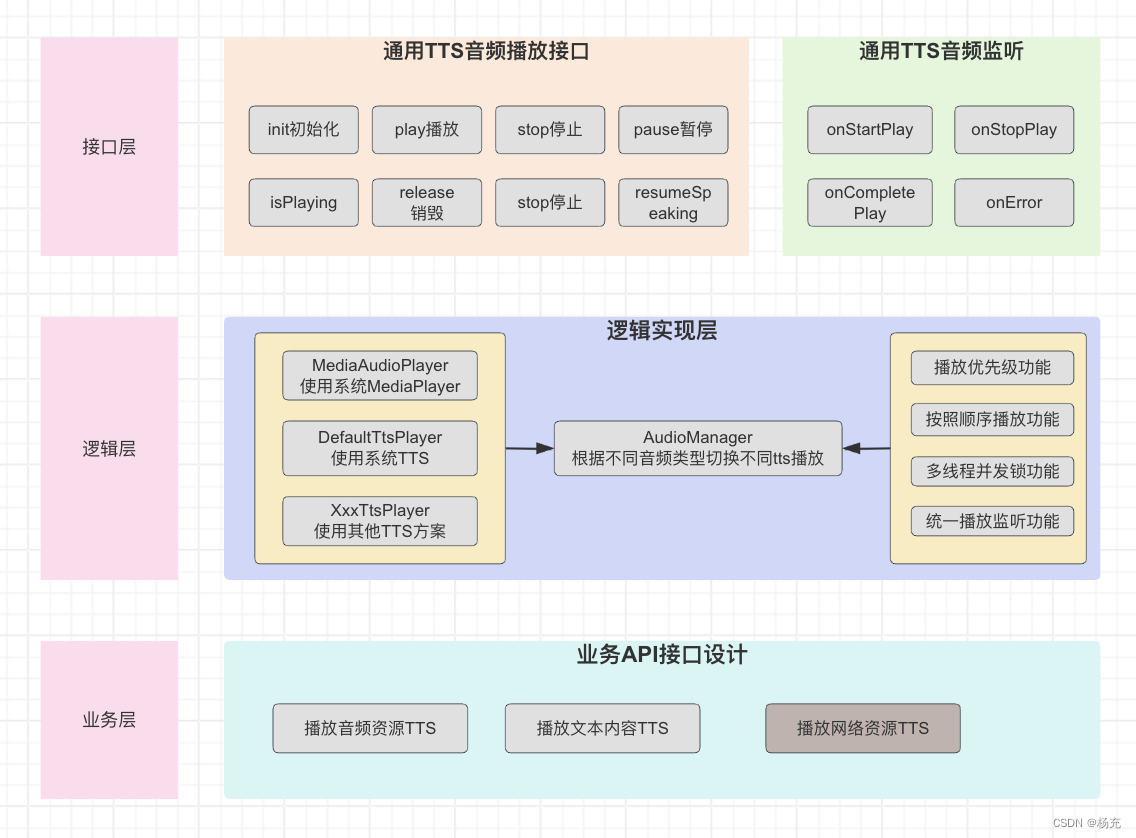
- 由于播放的音频,可以为文本,可以是音频,可以是连接。因此设置一个实体bean
- 播放文本,是字符串tts内容;这个使用系统自带TextToSpeech来实现。
- 播放音频,是本地资源文件rawId内容;这个使用MediaPlayer来实现。
- 播放连接,是网络资源url内容;这个使用谷歌ExoPlayer来实现。
- 添加了多条语音内容,如何让语音按照顺序播放,要做到这几点
- 如何添加多个音频并且是有序的?这个可以设计一个链表,用来存储音频实体。链表很好保证遍历有序,且高效!
- 如何让一个视频播完后接着播放下一个?监听语音播放完成的状态,然后获取链表下个数据,接着就开始play播放
- 添加多条语音内容,如何播放最新的语音,要做到这一点
- 如何做到播放内容永远都是最新数据?保证播放器只有一条数据,每次都是先stop掉前面的内容,然后再play播放当前内容。
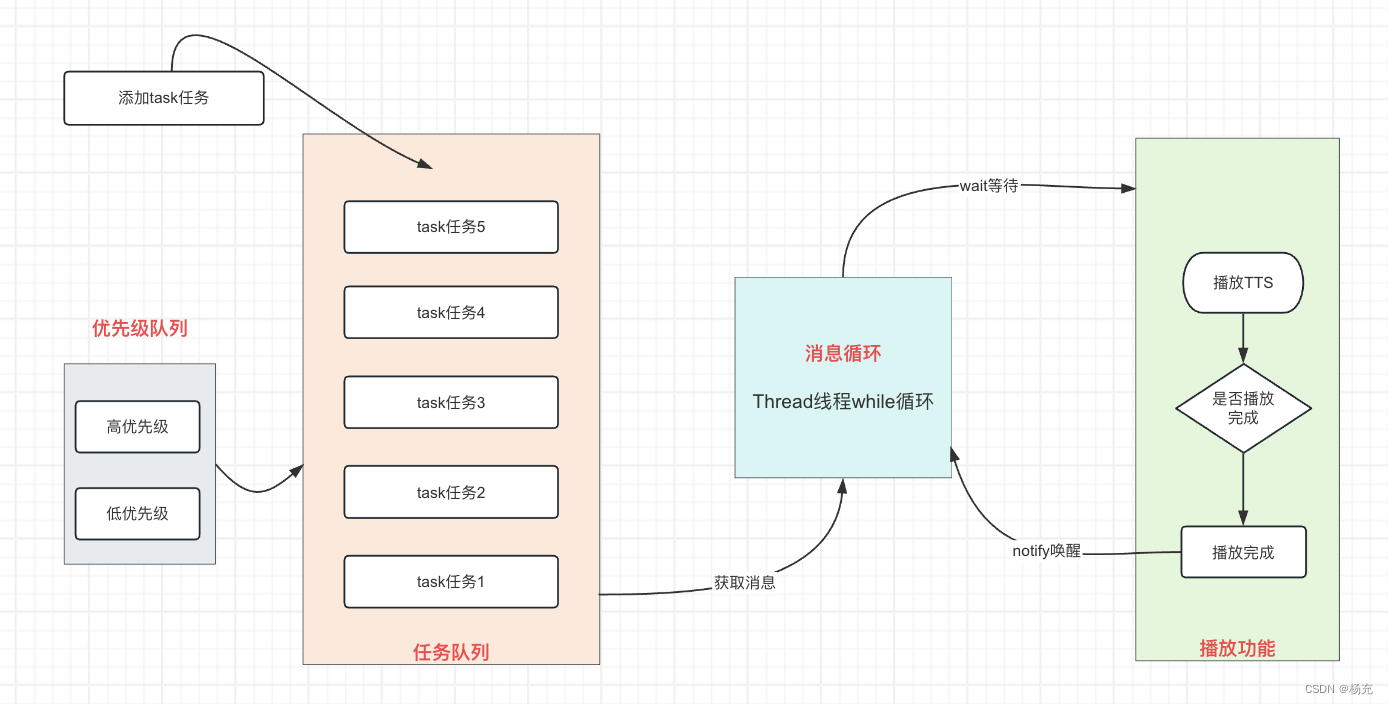
- 为什么要设计分发器?
- 主要是解决添加多条语音,让它们按照先后顺序播放。相当于一个任务分发器,每次添加数据,都是调用addTask添加一个任务。
- 关于分发器,进行顺序播放的流程图如下所示:
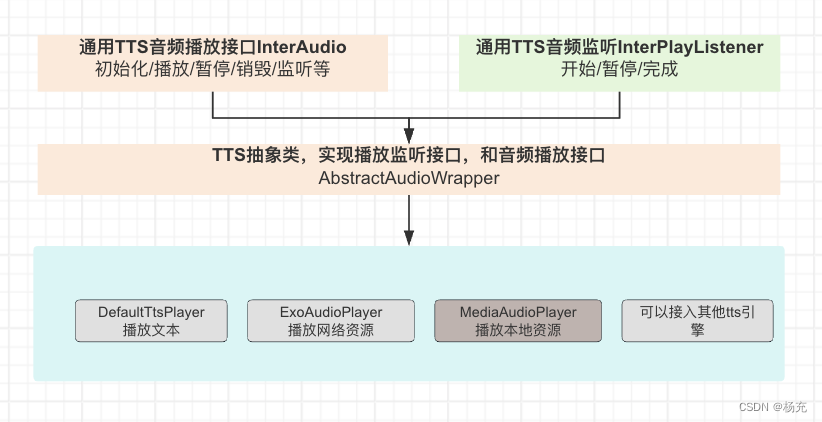
- 不管是那种方案实现tts语音播放功能,都去继承统一定义的接口
- 系统TextToSpeech实现统一播放接口,具体可以看:DefaultTtsPlayer
- 系统MediaPlayer来实现统一播放接口,具体可以看:MediaAudioPlayer
- 谷歌ExoPlayer来实现统一播放接口,具体可以看:ExoAudioPlayer
- 关于语音播放实现服务,其层次图如下所示:
- 播放服务是指,开发者调用语音播放api,对外方便简单调用,对内屏蔽具体实现细节。
- 设计AudioServiceProvider接口,里面包含:init初始化语音服务,stop停止播放,pause暂停播放,play播放数据,setPlayStateListener监听播放状态等api
- 设计AudioService代理类,相当于一个中间层,以隔离访问者和被访问者的实现细节。起到一个解耦合的作用。
- 设计AudioServiceImpl1实现类1做支持tts按照顺序和优先级播放,AudioServiceImpl2实现类2做支持每次播放最新的tts(会覆盖之前的),这两个做具体实现逻辑。
- 不管是哪一种语音播放,我都想知道什么时候播放完成,或者异常。这个时候就需要设计播放监听
- 第一步:设计通用播放监听的接口,其中包含播放开始,完成,异常等api;
- 第二步:在各种不同语音播放实现类中,在播放逻辑中,添加监听接口调用方法;
- 第三步:外部开发者添加监听后,能否通过接口回调做业务逻辑处理。比如播放完成,做某某业务。
- 系统TextToSpeech实现统一播放接口,具体可以看DefaultTtsPlayer
- 初始化:在初始化的时候,创建TextToSpeech对象,并且在初始化引擎回调的onInit方法中,设置朗读语音操作。因为,在团餐机中有英文tts;
- 播放:设置tts语音播放,在这个里面设置tts监听listener,然后调用speak方法对内容进行播放;
- 销毁:在不需要使用 TTS 功能时,应及时停止语音合成并释放相关资源,以避免资源浪费。可以使用 stop() 方法停止当前的语音合成,使用 shutdown() 方法释放 TTS 引擎。
- 系统MediaPlayer来实现统一播放接口,具体可以看MediaAudioPlayer
- 播放:在播放的时候,通过MediaPlayer的api加载本地资源。然后prepare准备,在准备监听listener回调完成后,开始play播放音频;
- 销毁:在不需要播放的时候,需要及时释放音频对象,避免资源浪费。
- 比如添加数据,按照顺序播放(先播放raw,然后播放tts文本,最后播放url资源,按照添加的先后顺序播放),代码如下所示
AudioPlayData data = new AudioPlayData.Builder(AudioTtsPriority.HIGH_PRIORITY) .tts("我是一个混合的协议的语音播报") .rawId(R.raw.timeout) .tts("Hello TTS Service") .url("https://asraudio.cdnjtzy.com/eb93cfd82d0044a1a9ce047c3aeafb8c.mp3") .url("https://asraudio.cdnjtzy.com/52bdab34457e4d9ca14a5a7feee94a23.mp3") .url("https://asraudio.cdnjtzy.com/eb93cfd82d0044a1a9ce047c3aeafb8c.mp3") .build(); AudioService.getInstance().play(data); - 按照添加的顺序,排序顺序播放的实践步骤
- 设计一个AudioPlayData对象,用链表实现
- 如何处理分析器中的消息队列
- AudioTaskDispatcher,在分发器中开启线程死循环,不断从链表中取出消息,处理消息。
- 这个可以给音频bean添加类型标签
- 其设计**可以借鉴:handler普通消息和屏障消息的设计**,给消息打个标签,先从消息队列中取出所有的屏障消息处理,然后在从消息队列中取出所有的普通消息做处理。
- 消息机制的同步屏障核心**:屏障消息就是为了确保异步消息的优先级,设置了屏障后,同步消息会被挡住。屏障消息优先级高于普通消息。
- 如何保证多线程播放安全,分别该如何选择?
- 对象锁
- lock锁
- synchronized
- 三种锁分别有不同的应用场景
- 这里在分发器的while循环中,关于设置线程wait操作,使用synchronized锁,用在代码块中。保证同一个对象在多线程中操作是线程安全的。
- 关于addTask添加tts播放任务,这里用到了lock锁,在开始添加调用lock(),在执行结束调用unlock释放。
- 在 Android 中,使用 TTS(Text-to-Speech)播放长内容可以通过以下步骤实现:
- 将长内容分割为适当的片段:由于 TTS 引擎可能有长度限制,将长内容分割为适当的片段是必要的。可以根据需要的片段长度或其他标准将长内容分割为多个较短的文本片段。
- 使用 speak() 方法逐个播放片段:使用 TextToSpeech 类的 speak() 方法逐个播放分割后的文本片段。可以在每个片段的朗读完成后,通过监听器的回调方法(如 onDone())来触发播放下一个片段。
- 控制播放速度和延迟:根据需要,可以使用 setSpeechRate() 方法设置播放速度,以控制 TTS 引擎的语音合成速度。此外,可以使用 setOnUtteranceProgressListener() 方法设置延迟,以确保在播放下一个片段之前有适当的间隔。
- 处理播放顺序和逻辑:根据需要,可以使用队列或其他数据结构来管理要播放的文本片段的顺序。可以在每个片段的朗读完成后,根据播放逻辑决定下一个要播放的片段。
- 监听播放状态和错误:使用 setOnUtteranceProgressListener() 方法设置监听器,以便在播放过程中获取播放状态和错误信息。通过监听器的回调方法,可以处理播放开始、完成和错误等
- 异步处理:为了避免阻塞主线程,建议在后台线程中执行 TTS 操作。可以使用 AsyncTask 或其他异步机制来执行 TTS 操作,以确保长内容的播放不会影响应用程序的响应性能。
- 处理播放长内容,是比较复杂的逻辑。
- 将长内容分割为适当的片段,并使用 TTS 的播放方法逐个播放这些片段。同时,注意处理播放顺序、播放状态和错误,以及中断和暂停播放的情况。
- 对于 TTS 使用有几点使用上的建议
- TTS Request App 的 Activity 或 Service 生命周期销毁的时候,比如 onDestroy() 等时候,需要调用 TextToSpeech 的 shutdown() 释放连接、资源。
- 可以通过 addSpeech() 指定固定文本的对应 audio 资源 (比如说语音里常用的几套唤醒后的欢迎词 audio),在后续的文本请求时直接播放该 audio,免去文本转语音的过程、提高效率。
- 比如:播放A,B,C三条TTS语音。B播放异常,C还会播放吗?
- B播放异常,C会播放的。B播放异常,在播放器异常监听的回调中,处理逻辑是先停止播放,然后将异常信息暴露给开发者,最后回调播放完成的api。
- 不管是那种tts可能遇到播放异常,异常该如何处理呢
- 将异常错误通过监听接口,回调给外部开发者。方便排查问题。
- 播放异常后,先调用stop停止player播放,最后再回调播放完成方法。
- 子线程exo播放异常
java.lang.IllegalStateException: Player is accessed on the wrong thread. See https://exoplayer.dev/issues/player-accessed-on-wrong-thread- 不管是哪一种tts播放方式,在调用play方法播放时,会判断是否是主线程。代码如下所示
@Override public void playTts(final String tts) { if (null != this.mDelegate) { if (DelegateTaskExecutor.getInstance().isMainThread()) { this.mDelegate.playTts(tts); } else { DelegateTaskExecutor.getInstance().postToMainThread(() -> mDelegate.playTts(tts)); } } }
- 先说一下兼容性问题
- 如果出现speak failed: not bound to TTS engine并且是Android 11。则需要做兼容处理。
- 兼容性考虑设计
- 为兼容Android11系统手机,我们需要在应用程序AndroidManifest.xml文件中增加如下声明:
<queries> <intent> <action android:name="android.intent.action.TTS_SERVICE"/> </intent> </queries>
- 语言 TextToSpeech 机制简单介绍
- 任意 App 都可以方便地采用系统内置或第三方提供的 TTS Engine 进行播放铃声提示、语音提示的请求,Engine 可以由系统选择默认的 provider 来执行操作,也可由 App 具体指定偏好的目标 Engine 来完成。
- 默认 TTS Engine 可以在设备设置的路径中找到,亦可由用户手动更改: Settings -> Accessibility -> Text-to-speech output -> preferred engine
- 系统默认的 TTS(Text-to-Speech)引擎是 Google TTS 引擎,它基于语音合成技术实现文本到语音的转换。
- 文本处理:当应用程序调用 TTS 引擎时,首先将待合成的文本传递给引擎。引擎会对文本进行处理,包括分词、标点符号处理、语法分析等,以便更好地理解和合成语音。
- 文本转音素:引擎将处理后的文本转换为音素序列。音素是语音的最小单位,每个音素对应一个特定的发音。通过将文本转换为音素序列,引擎可以更准确地控制语音的合成过程。
- 合成语音:基于音素序列,引擎使用声学模型和语音合成算法来生成语音波形。语音合成算法根据音素序列和声学模型,生成合成语音的波形。
- 参数调整:在语音合成过程中,引擎可以根据设置的参数进行调整。例如,可以调整语速、音调、音量等参数,以满足不同的应用需求和用户偏好。
- 播放语音:生成的语音波形可以通过音频输出设备进行播放。引擎将合成的语音波形传递给音频系统,然后由音频系统输出到扬声器或耳机,供用户听取。
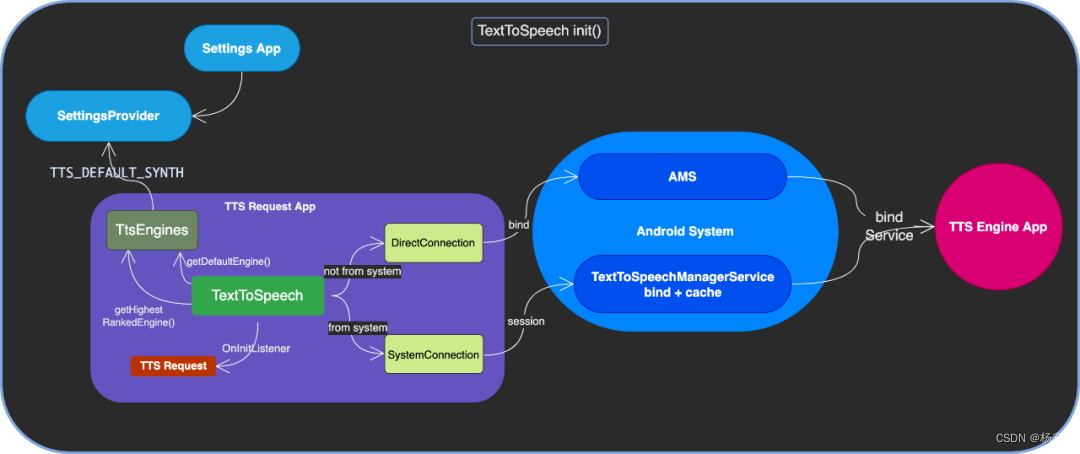
- Speech整体设计流程图
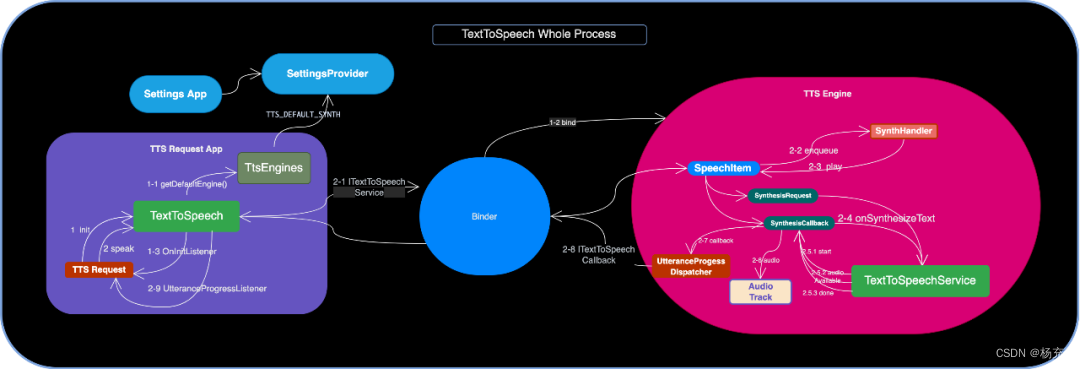
- 初始化TTS其实就是创建TextToSpeech对象。传递初始化完成的监听器,可以初始化 TTS 引擎。一旦引擎初始化完成,就可以开始使用 TTS 功能。
- 然后看一下源码流程
- 第一步:TextToSpeech#TextToSpeech(),看一下构造方法,最后可以看到,创建了TtsEngines引擎对象然后调用initTts初始化引擎操作。
- 第二步:TextToSpeech#initTts()初始化引擎工作
- 第三步:TextToSpeech#connectToEngine()连接引擎后建立连接服务
- 第四步:在connectToEngine方法中,回调最终连接结果
- TextToSpeech#initTts(),其核心逻辑是查找需要连接到哪个 Engine 。
- 如果构造 TTS 接口的实例时指定了目标 Engine 的 package,那么首选连接到该 Engine。
- 否则,获取设备设置的 default默认 Engine 并连接,设置来自于 TtsEngines 从系统设置数据 SettingsProvider 中读取 TTS_DEFAULT_SYNTH 而来。
- 如果 default 不存在或者没有安装的话,从 TtsEngines 获取第一位的系统 Engine 并连接。第一位指的是从所有 TTS Service 实现 Engine 列表里获得第一个属于 system image 的 Engine
- TextToSpeech#connectToEngine(),其核心逻辑就是通过bindService连接服务
- 封装 Action 为 INTENT_ACTION_TTS_SERVICE 的 Intent 进行 bindService(),后续由 AMS 执行和 Engine 的绑定。
- 这里的Engine可能是RequestedEngine,或者是系统的defaultEngine。
- 无论是哪种方式,在 connected 之后都需要将具体的 TTS Engine 的 ITextToSpeechService 接口实例暂存,同时将 Connection 实例暂存到 mServiceConnection,给外部类接收到 speak() 的时候使用。
- 在TextToSpeech#onServiceConnected()中,还会启动一个异步任务 SetupConnectionAsyncTask 将自己作为 Binder 接口 ITextToSpeechCallback 返回给 Engine 以处理完之后回调结果给 Request
- 将 speak() 对应的调用远程接口的操作封装为 Action 接口实例,并交给 init() 时暂存的已连接的 Connection 实例去调度。
- 然后看一下源码流程
- 第一步:TextToSpeech#speak(),看一下该方法,主要是传递一些参数到tts引擎中
- 第二步:TextToSpeech#runAction(),继续追踪到TextToSpeech#ServiceConnection.runAction(),看最后的action.run(mService)
- 第三步:最后回到TextToSpeech#speak(),从 mUtterances Map 里查找目标文本是否有设置过本地的 audio 资源,否则通过调用service.speak方法
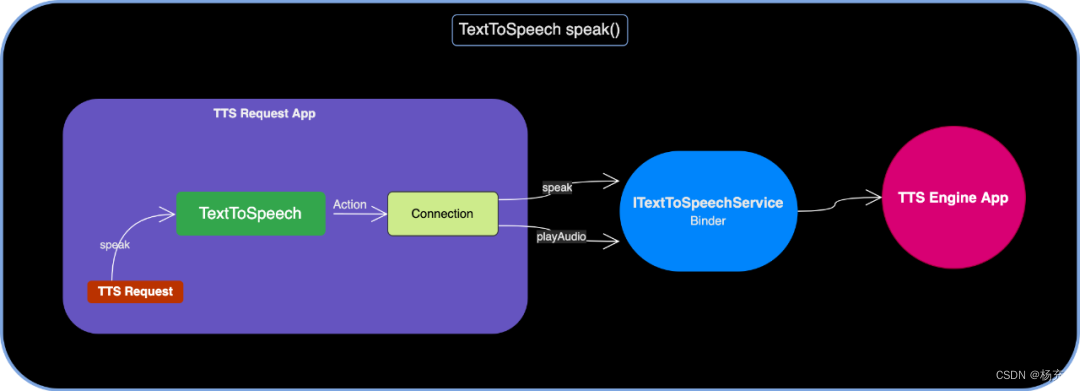
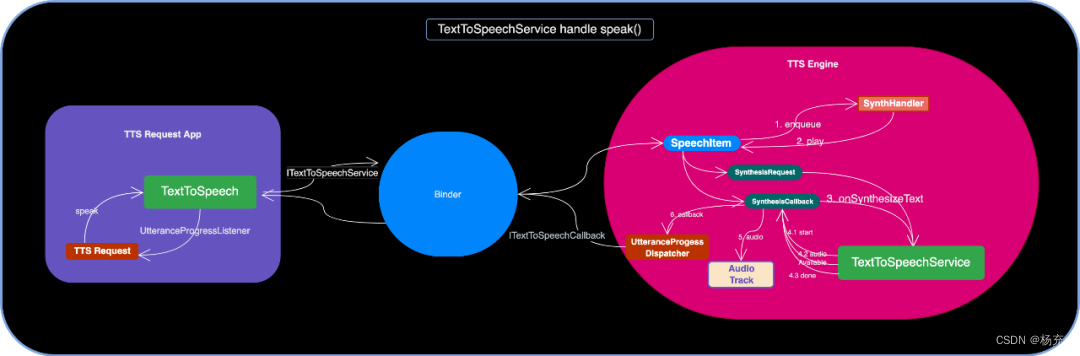
- 跟着上面继续分析,最终的实现细节在service中。这个具体看:TextToSpeechService
- 有设置的话,调用 TTS Engine 的 playAudio() 直接播放;否则调用 text 转 audio 的接口 speak()
public int speak(final CharSequence text, final int queueMode, final Bundle params, final String utteranceId) { return runAction((ITextToSpeechService service) -> { Uri utteranceUri = mUtterances.get(text); if (utteranceUri != null) { return service.playAudio(getCallerIdentity(), utteranceUri, queueMode, getParams(params), utteranceId); } else { return service.speak(getCallerIdentity(), text, queueMode, getParams(params), utteranceId); } }, ERROR, "speak"); } - TextToSpeechService 实现,它是一个Service服务。
- 在onCreate方法中,创建SynthThread作为一个独立线程,创建SynthHandler发送封装的speak或者audio的消息。
- 然后看一下,TextToSpeechService#ITextToSpeechService.speak()方法和TextToSpeechService#ITextToSpeechService.playAudio()方法。
- speak 请求封装给 Handler 的是 SynthesisSpeechItem;playAudio 请求封装的是 AudioSpeechItem;它们通过SynthHandler发送并处理消息。
- SynthHandler 拿到 SpeechItem 后根据 queueMode 的值决定是 stop() 还是继续播放。播放的话,是封装进一步 play 的操作 Message 给 Handler。
- 思考一下,tts如何将文本转化为audio文件播放,在TextToSpeechService是否能找到实现步骤?
- TextToSpeechService.SynthHandler#enqueueSpeechItem(),根据 queueMode 的值决定是 stop() 还是继续播放。播放的话,是封装进一步 play 的操作 Message 给 Handler。
- play() 具体是调用 playImpl() 继续。这块可以直接看AudioSpeechItem负责音频播放,SynthesisSpeechItem负责文本播放,这两个类都是继承SpeechItem抽象类。
- 对于 SynthesisSpeechItem 来说,将初始化时创建的 SynthesisRequest 实例和 SynthesisCallback 实例 (此处的实现是 PlaybackSynthesisCallback) 收集和调用 onSynthesizeText() 进一步处理,用于请求和回调结果。
- onSynthesizeText() 是 abstract 方法,需要 Engine 复写以将 text 合成 audio 数据,也是 TTS 功能里最核心的实现。