-
Node.js Koa2 the movie trailer site
-
视频课程出品时间:2018年 年初
-
- koa-router简单配置
- 配置路由层级
- router.use路由分层
- 动态路由参数
- 分割路由文件
- 第1章 2018 年的编程姿势
- 第2章 必会 ES6-7 语法特性与规范
- 第3章 层层学习 Koa 框架的 API
- 第4章 Koa2 与 Koa1 、Express 框架对比
- 第5章 从 0 开发一个电影预告片网站
- 第6章 利用爬虫搞定网站基础数据
- 第7章 彩蛋篇 - [高难度拔高干货] 深度理解 Node.js 异步 IO 模型
- 第8章 实战篇 - 在 Koa 中向 MongoDB 建立数据模型
- 第9章 实战篇 - 为网站增加路由与控制器层对外提供 API 服务
- 第10章 实战篇 - 集成 AntDesign 与 Parcel 打通前后端与构建
- 第11章 实战篇 - 实现网站前端路由与页面功能
- 第12章 实战篇 - 实现后台登录权限与管理功能
- 第13章 服务器部署与发布
- 第14章 课程总结与展望
-
- 市场常见 Node.js Web 服务框架
- Express
- Koa
- Sail
- Hapi
- 本课程概况
- 做什么?
- 开发一个可以实时更新的预告片网站
- 有哪些功能?
- 网站首页
- 网站首页播放窗口
- 网站播放详情页
- 网站详情
- 同类推荐
- 网站后台登陆
- 网站后台管理列表
- 技术栈?
- Koa2
- Nodejs
- MongoDB
- Puppeteer
- Parcel
- AntDesign
- 做什么?
- 解答 过去我们 遇到的问题?
- Koa 框架到底为我们做了什么?
- 他的内部到底是什么样子?
- 他向下一直到 Node.js 底层,到底是怎么处理事件循环的?
- 一个异步的 HTTP 过程,到底是怎么样进行的?
- 市场常见 Node.js Web 服务框架
-
- https://node.green/
- 查看 当前阶段 各个Node.js版本 对ECMA规范 实现的程度,及支持情况
- NVM
- 问题:本地如何管理 那么多的 Node.js 版本?
- 什么是 NVM?
- Node.js版本管理工具
- 使用 NVM 这个 Node.js版本管理工具
- 如何安装 NVM ?
- 到 github 搜索
- Mac / Linux 安装 NVM 方式
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.1/install.sh | bash
- 由于 Windows 和 Mac / Linux 的安装方式不同
- 如何使用 NVM
nvm ls #查看本地安装的node版本 nvm install stable # 安装最新稳定版 node,现在是 5.0.0 nvm install 4.2.2 # 安装 4.2.2 版本 nvm install 0.12.7 # 安装 0.12.7 版本 # 特别说明:以下模块安装仅供演示说明,并非必须安装模块 nvm use 4 # 切换至 4.2.2 版本 npm install -g mz-fis # 安装 mz-fis 模块至全局目录,安装完成的路径是 /Users/<你的用户名>/.nvm/versions/node/v0.12.7/lib/mz-fis nvm use 0 # 切换至 0.12.7 版本 npm install -g react-native-cli #安装 react-native-cli 模块至全局目录,安装完成的路径是 /Users/<你的用户名>/.nvm/versions/node/v4.2.2/lib/react-native-cli nvm alias default 0.12.7 #设置默认 node 版本为 0.12.7
- https://node.green/
-
- Promises 官网
- Promises 是什么?
- 问题来了,Promise是什么玩意呢?是一个类?对象?数组?函数?
- 别猜了,直接打印出来看看吧,console.dir(Promise),就这么简单粗暴。
➡ console.dir(Promise) ⬇ function Promise() ➡ all: function all() ➡ allSettled: function allSettled() arguments: (...) caller: (...) length: 1 name: "Promise" ⬇ prototype: Promise ➡ catch: function catch() ➡ constructor: function Promise() ➡ finally: function finally() ➡ then: function then() Symbol(Symbol.toStringTag): "Promise" ➡ __proto__: Object ➡ race: function race() ➡ reject: function reject() ➡ resolve: function resolve() Symbol(Symbol.species): (...) ➡ get Symbol(Symbol.species): function [Symbol.species]() ➡ __proto__: function () ➡ [[Scopes]]: Scopes[0]-
这么一看就明白了
- Promise是一个构造函数 - 自己身上有 `all、reject、resolve` 这几个眼熟的方法 - 原型上有 `then、catch` 等同样很眼熟的方法。 - 这么说用Promise new出来的对象肯定就有then、catch方法喽,没错。 -
古人云:“君子一诺千金”,这种
“承诺将来会执行”的对象在JavaScript中称为Promise对象。 -
Promises 不是一个简单的语法糖
-
而是一个规范
- 如 bluebird 就实现了这个规范
-
各种各样的库 都可以去实现这套规范,进而向我们 提供Promises能力的接口 函数
-
const fs = require('fs') // 1.回调方式 fs.readFile('./1-3 Promise.js', (err, data) =>{ if (err) throw err console.log(data.toString()) })
-
const fs = require('fs') function readFileAsync (path) { return new Promise((resolve, reject) => { fs.readFile(path, (err, data) => { if (err) reject(err) else resolve(data) }) }) } readFileAsync('./1-3 Promise.js') .then(data => { console.log(data.toString()) }) .catch(err => { console.log(err) })
- 虽然这种写法 有点冗长,但是也没有什么弊端
-
- Node.js 进入 v8.x 版本以后
- 我们就可以使用 nodejs util 模块提供的 promisify 让我们可以轻易的 包装一个 回调式的 Api ,让它直接支持 promise
const fs = require('fs') const util = require('util') util.promisify(fs.readFile)('./1-3 Promise.js') .then(data => { console.log(data.toString()) }) .catch(err => { console.log(err) })
- 解释
util.promisify()- 传入某一个回调函数,这里传入 fs.readFile ,fs.readFile 它本身是一个回调的异步函数
util.promisify(fs.readFile)- 我们把这个函数包装之后,它会返回一个 promise function,再来调用
util.promisify(fs.readFile)('./1-3 Promise.js')- 后面的这个 () 才是传参数
- 总结
- 优点:减少了代码量。将原来 promise 方法中的 20行代码,减少到 10行
- 在项目中遇到有 回调处理异步的场景,推荐大家 使用这种 promisify,来完成 从回调到 向promise 迁移到工作
-
- 先来看 这段 使用 async function 实现 上一节中的同样的功能
const fs = require('fs') const util = require('util') const readAsync = util.promisify(fs.readFile) async function init () { try { let data = await readAsync('./1-3 Promise.js') console.log(data.toString()) } catch (err) { console.log(err) } } init()
- 存在的问题
- 使用这些新的语法,虽然用起来很爽
- 但是,也带来一些问题
- 当你的运行环境不支持 这些前卫的新语法时,就会导致无法正确运行代码。
- 如:你在node v4.x 或者 v6.x 版本中使用时
- 所以这个时候,就需要用到 babel 来编译, 将这些 旧版本不支持的新语法,编译成 他们能够识别执行的语法
-
- 1.generator function
- generator function 是ES6 新增的特性,node.js v4.x 版本后就可以直接使用了
- generator function 的核心是
generator 生成器 generator 生成器的本质是Iterator 迭代器- 所以我们先要理解,什么是
Iterator 迭代器这个概念
-
- 定义:迭代器是一个拥有 next() 方法的特殊对象,每次调用 next() 都返回一个结果对象
- Iterator 迭代器
- 跟 Promise 一样,并不是 某一个具体的语法 或者 对象
- 它是一个 协议
- 只要遵循这个 协议 所实现的,都是迭代器对象
- 下面来手写一个 Iterator 迭代器
- 例1
function makeIterator (arr) { let nextIndex = 0 // 返回一个迭代器对象 return { next: () => { // next() 方法返回的结果对象 if (nextIndex < arr.length) { return { value: arr[nextIndex++], done: false } } else { return { done: true } } } } } const it = makeIterator(['吃饭', '睡觉', '打豆豆']) console.log('首先', it.next().value) console.log('其次', it.next().value) console.log('然后', it.next().value) console.log('最后', it.next().done) // 打印结果 首先 吃饭 其次 睡觉 然后 打豆豆 最后 true
- 这是一个非常简易的 Iterator 迭代器
- 例2
- 感受一下用ES5语法模拟创建一个迭代器:
function createIterator(items) { var i = 0; return { // 返回一个迭代器对象 next: function() { // 迭代器对象一定有个next()方法 var done = (i >= items.length); var value = !done ? items[i++] : undefined; return { // next()方法返回结果对象 value: value, done: done }; } }; } var iterator = createIterator([1, 2, 3]); console.log(iterator.next()); // "{ value: 1, done: false}" console.log(iterator.next()); // "{ value: 2, done: false}" console.log(iterator.next()); // "{ value: 3, done: false}" console.log(iterator.next()); // "{ value: undefiend, done: true}" // 之后所有的调用都会返回相同内容 console.log(iterator.next()); // "{ value: undefiend, done: true}"
- 下面我们来调用 一下 迭代器
var colors = ["red", "green", "blue"]; var iterator = createIterator(colors); while(!iterator.next().done){ console.log(iterator.next().value); }
- createIterator()只需写一次,就可以一直复用
- 例1
-
- 以上,我们通过调用createIterator()函数,返回一个对象 - 这个对象存在一个next()方法 - 当next()方法被调用时,返回格式 { value: 1, done: false} 的结果对象。 - 因此,我们可以这么定义:迭代器是一个拥有next()方法的特殊对象,每次调用next()都返回一个结果对象。- 每一次迭代的值,都是跟上一次迭代的值 有关系的,它是处于上一个值,下一个序列中 即将被执行的链路 - 每一次迭代的值,都反映了 迭代器内部的状态 - 这些状态的组合 是一个完整的状态流程 - 我们通过 next 方法,依次拿到某个状态的值 - 迭代器内部 总有一个 next 方法,通过它 总能拿到一个对象 - 其中 value 是某一次迭代的结果,done 是当前是否迭代完成的标志
-
-
1.什么是 generator 生成器?
generator 生成器函数是一个可以生成迭代器的函数 (返回迭代器)- 我们本质上 来是在操作 迭代器,只不过 借助于生成器函数 来完成这个过程
- ES6引入了生成器对象,可以让创建迭代器的过程变得更加简单。
-
- generator 生成器 比普通 function 多一个 * 星号
- 生成器 每一次迭代,都是通过 yield 关键字来实现
-
3.来看一下 如何使用 generator 生成器
- 例1
function *makeIterator (arr) { for (let i = 0; i < arr.length; i++) { yield arr[i] } } const it = makeIterator(['吃饭', '睡觉', '打豆豆']) console.log('首先', it.next().value) console.log('其次', it.next().value) console.log('然后', it.next().value) console.log('最后', it.next().done) // 打印结果 首先 吃饭 其次 睡觉 然后 打豆豆 最后 true
- 例2
function *createIterator(items) { for(let i=0; i<items.length; i++) { yield items[i]; } } let iterator = createIterator([1, 2, 3]); // 既然生成器返回的是迭代器,自然就可以调用迭代器的next()方法 console.log(iterator.next()); // "{ value: 1, done: false}" console.log(iterator.next()); // "{ value: 2, done: false}" console.log(iterator.next()); // "{ value: 3, done: false}" console.log(iterator.next()); // "{ value: undefiend, done: true}" // 之后所有的调用都会返回相同内容 console.log(iterator.next()); // "{ value: undefiend, done: true}"
- 上面,我们用 `ES6` 的生成器,大大简化了迭代器的创建过程。 - 我们给生成器函数 createIterator() 传入一个items数组, - 函数内部,for循环不断从数组中 **生成新的元素放入迭代器中**, - 每遇到一个 `yield` 语句循环都会停止; - 每次调用迭代器的next()方法,循环便继续运行并停止在下一条 `yield` 语句处。
- 例1
-
- 通过 generator 生成器,我们实现了 跟上面 Iterator 迭代器 一样的结果 - 生成器的出现,就是为了简化掉 我们以前需要 手写 这一大坨 返回的迭代器对象 - **生成器** 就是 为了更方便 我们使用 **迭代器** 而出现的 - 简化掉 我们手写 迭代器的过程 - 通过 yield 关键字,我们还能够做到 断点执行,一步一步调用 的效果// 返回一个迭代器对象 return { next: () => { // next() 方法返回的结果对象 if (nextIndex < arr.length) { return { value: arr[nextIndex++], done: false } } else { return { done: true } } } }
-
- 1.generator function
-
-
- https://github.com/tj/co
- co 是一个 js 库
- 由 tj 大神所贡献的,tj 活跃于 node.js社区、go社区 ... 很多编程语言社区
- co 是一个 function, 它试图把 所有传入的 参数,都转成 promise。 co 这个库 非常的单纯,就只是一个包装 和 转化 的作用 - 用于 Generator 函数的自动执行 - co 函数库可以让你不用编写 Generator 函数的执行器 - co 会把 所有传入的 generator function 都转成 promise- 将接收到的参数,如
数组、函数、generator function、对象 ...全都转成 promise
-
const co = require('co') const fetch = require('node-fetch') // node-fetch 用于异步请求数据 co(function *() { const res = yield fetch('https://api.douban.com/v2/movie/subject/30261964?apikey=0df993c66c0c636e29ecbb5344252a4a') const movie = yield res.json() // 将文本解析为 json const summary = movie.summary console.log('summary', summary) }) // 打印结果 // summary 《古田军号》是庆祝中华人民共和国成立70周年献礼影片。影片用真诚的艺术表达和创新的手法,以一个红军小号手的视角,讲述了红军从井冈山突围到闽西期间,年轻的革命领袖带领年轻的红军,在绝境中探索真理,开辟了**革命成功的非凡历程。
-
上面代码解析
- co() 传入一个 generator function
- 题外话 res.json()
const movie = yield res.json() // 将文本解析为 json
Bodymixin 的json()方法接收一个 Response 流,并将其读取完成。它返回一个 Promise,Promise 的解析 resolve 结果是将文本体解析为JSON。- 参考链接 Body.json() https://developer.mozilla.org/zh-CN/docs/Web/API/Body/json
-
总结
-
结合上节 和 现在的这个代码,我们可以非常直观的理解
genertor function和 它内部的yield -
通过 yield 这种同步的方式,基本上就实现了 一个状态 或者 一个进程 的暂停
-
当 第一个 yield 没有执行完的时候,第二个 yield 是不会执行的,也就是说实现了一个 函数暂停
-
- co 这个函数,让里面的每一个 暂停函数 ,都能够得到 一步一步的自动执行 - 也就是 实现了 generator function 的自动执行 -
在上一节中,我们看到,generator function 必须手动调用 next ,才能继续往下执行
-
但是,我们有了 co,就能实现自动执行完 里面的 暂停函数了
-
-
-
- 下面我们用 run() 函数 来模拟一下,co库 的内部执行过程,让大家直观的理解 co库 的内部是如何运作的
function run (generator) { const iterator = generator() // generator 执行的结果 是最终生成了一个 iterator 迭代器 const it = iterator.next() const promise = it.value promise.then(data => { const it2 = iterator.next(data) const promise2 = it2.value promise2.then(data2 => { iterator.next(data2) }) }) } // 调用 run函数 run(function *() { const res = yield fetch('https://api.douban.com/v2/movie/subject/30261964?apikey=0df993c66c0c636e29ecbb5344252a4a') const movie = yield res.json() // 将文本解析为 json,参考链接 Body.json() https://developer.mozilla.org/zh-CN/docs/Web/API/Body/json const summary = movie.summary console.log('summary', summary) }) // 打印结果 // summary 《古田军号》是庆祝中华人民共和国成立70周年献礼影片。影片用真诚的艺术表达和创新的手法,以一个红军小号手的视角,讲述了红军从井冈山突围到闽西期间,年轻的革命领袖带领年轻的红军,在绝境中探索真理,开辟了**革命成功的非凡历程。
-
上面代码解析
- 我们用 run() 函数 来模拟一下,co库 的内部执行过程,让大家直观的理解 co库 的内部是如何运作的 - run() 函数 里面,有两次 promise 分别对应 上面co() 函数中的两次 yield - 着两段代码,执行的结果是一样,执行的过程是类似的 -
co() 内部的工作原理
- 将传入的 generator function 转化成 iterator, 然后再将 iterator 转化成 promise - 然后不断的 调用 promise.then() 直到所有的 promise 的链路都执行完毕 -
co 存在的意义:
- 在这个例子中,只有两个 promise ,手写起来还可以接受, - 但是 在其他情况下,如果 promise 多了的话,还需要手动去写 去调用,就基本不可能了 (要么就烦死) - 但是 有了 co库 就不一样了,整个过程 被它自动化掉了,这就是 co 带给我们的便利 -
co 的缺点:
- co 只能 yield 对象、数组、promise、generator、chunck function - 不能 yield 字符串、布尔值
-
-
- ES6 中允许使用“箭头”(=>)定义函数
-
const arrow = function (param) {} // ES5 函数定义 const arrow = (param) => {} // ES6 中箭头函数 const arrow = param => {} // 如果只有一个 参数 const arrow = param => console.log(param) // 如果函数内 只有一行代码 const arrow = param => ({param: param}) // 如果要返回一个对象 const arrow = (param1, param2) => {} // 如果要传入多个参数 // {id: 1, movie: xxx} const arrow = ({id, movie}) => { // 如果传入的参数是一个 Object console.log(id, movie) }
-
const luke = { id: 2, say: function () { setTimeout(function(){ console.log('id: ', this.id) }, 50) }, sayWithThis: function(){ let _this = this setTimeout(function(){ console.log('this id: ', _this.id) }, 500) }, sayWithArrow: function(){ setTimeout(() => { console.log('arrow id: ', this.id) }, 1500) }, sayWithGlobalArrow: () => { setTimeout(() => { console.log('global arrow id: ', this.id) }, 2000) } } luke.say() luke.sayWithThis() luke.sayWithArrow() luke.sayWithGlobalArrow() // 考察 对于箭头函数,this 作用域 的掌握程度 // 打印结果 // id: undefined // this id: 2 // arrow id: 2 // global arrow id: undefined
-
- 箭头函数 语法简洁 - this 指向函数定义时候 所属的作用域下,而不是运行时的作用域 - 这种作用域 更加可控、安全
-
- 1.JS 语言特性变迁史
- 1.我们从前锁定 this 的作用域,都是通过 `var _this = this`, 这种形式 交给另外一个变量进行缓存。 - 然而 有了箭头函数后 这种方式就成为历史了- 2.我们从前 控制异步的流程,一般通过回调函数 - 然而有了 Promise 、generator function、async function 之后,它又成为历史了 -
-
const fs = require('fs') // 过去回调函数 控制异步流程 function readFile (callback) { fs.readFile('./package.json', (err, data) => { if (err) return callback(err) callback && callback(null, data) }) } readFile((err, data) => { if (err) throw err data = JSON.parse(data) console.log(data) })
-
const fs = require('fs') function readFileAsync (path) { return new Promise((resolve, reject) => { fs.readFile(path, (err, data) => { if (err) reject(err) else resolve(data) }) }) } readFileAsync('./package.json') .then(data => { data = JSON.parse(data) console.log(data) }) .catch(err => { console.log(err) })
-
- 借助 co 让generator function自动迭代完毕
const fs = require('fs') const co = require('co') const util = require('util') co(function *() { let data = yield util.promisify(fs.readFile)('./package.json') data = JSON.parse(data) console.log(data) })
-
const fs = require('fs') const util = require('util') const readAsync = util.promisify(fs.readFile) async function init () { let data = await readAsync('./package.json') data = JSON.parse(data) console.log(data) } init()
- 从上面的例子中,我们可以看到、了解到 这些年 控制异步的历史
-
- 1.JS 语言特性变迁史
-
-
1.先来看以前的用法
const fs = require('fs') const { writeFile } = require('fs') // 解构方式的模块加载
-
- 像上面这种
require()方法 - 是 运行时的模块加载
- 先加载整个 fs 对象,然后再从 fs对象 上拿到 writeFile,
- 并且 这个加载必须要等待代码运行的时候 才会 来获取,所以这种加载方式又叫做 运行时加载 (而不是静态加载)
- 像上面这种
-
- 静态加载 是代码在编译的时候 就能够获取到这个方法 (而不是在运行到时候)
- 那么,如何才能实现 静态加载呢?
- 这就需要用到
import模块加载方式
import { writeFile } from 'fs'
-
-
-
import 和 export是 ES6 的新特性 -
上面的例子,可以这样改写
import { writeFile } from 'fs'
-
存在的问题
- 最新的几个 Node.js 版本 都没有实现
import这个关键字,不支持 - 先来看个 案例
// demo.js import fs from 'fs'
- 执行代码,
node demo.js - 然后出现报错
import fs from 'fs' ^^^^^^ SyntaxError: Cannot use import statement outside a module at Module._compile (internal/modules/cjs/loader.js:895:18) at Object.Module._extensions..js (internal/modules/cjs/loader.js:995:10) at Module.load (internal/modules/cjs/loader.js:815:32) at Function.Module._load (internal/modules/cjs/loader.js:727:14) at Function.Module.runMain (internal/modules/cjs/loader.js:1047:10) at internal/main/run_main_module.js:17:11- 大概意思是nodejs不支持import语法,如果要支持,需要babel来支持
- 执行代码,
- 最新的几个 Node.js 版本 都没有实现
-
解决的问题
- 所以这个时候,就需要用到 babel 来编译
import - 但是,使用 babel 又会带来另外一个问题,使得 项目的依赖 变得比较臃肿
- 所以这个时候,就需要用到 babel 来编译
-
-
-
npm i babel-cli babel-preset-env -D
-
- bable 配置文件
- 在项目根目录下 新建 .babelrc 文件
// .babelrc { "presets": [ [ "env", { "targets": { "node": "current" } } ] ] }
- bable 配置文件
-
// /src/index.js import fs from 'fs'
- 这时候 执行
node src/index.js会报错,跟上面提到的错误一样
- 这时候 执行
-
- 我们这里使用
nodemon来做 自动监听 - nodemon用来监视node.js应用程序中的任何更改并自动重启服务,非常适合用在开发环境中。
// /package.json { "scripts": { "dev": "nodemon -w src --exec \"babel-node src --presets env\"" } }
- 这句命令的意思是,监听 src目录下的 写入操作,如果监听到,就执行 后面的代码- 安装 nodemon
npm i nodemon -D-D保存到开发依赖当中
- 开启监控
npm run dev, 如果有变化 则自动重新编译[nodemon] 2.0.2 [nodemon] to restart at any time, enter `rs` [nodemon] watching dir(s): src/**/* [nodemon] watching extensions: js,mjs,json [nodemon] starting `babel-node src --presets env` [nodemon] clean exit - waiting for changes before restart
- 示例代码
// /src/index.js import { promisify } from 'util' import { resolve as r } from 'path' import { readFile, writeFileSync as wfs } from 'fs' import * as qs from 'querystring' promisify(readFile)(r(__dirname, '../package.json')) .then(data => { data = JSON.parse(data) console.log(data.name) wfs(r(__dirname, './name_demo.js'), String(data.name), 'utf8') }) .catch(err => { console.log(err) })
- 一旦文件改动,就会自动执行 这个文件
- 为什么会自动执行,而不是 编译这个文件?
- 添加
start命令 :nodemon --exec babel-node src/server.js。这个命令是告诉nodemon去监听文件的变化,一旦检测到有文件发生了变化,就会重启并用babel-node去运行src/server.js文件。这个命令一般用于本地开发。 - 参考文章: [译]使用Babel7+nodemon打造你的Node.js项目开发
- 添加
- 我们这里使用
-
-
// /src/ex.js export const name = 'Luke' export const getName = () => { return name }
// /src/index.js import { name } from './ex' import { getName } from './ex' // import { name, getName } from './ex' // 或者一次性拿到两个
- 执行
npm run dev, 也就是"nodemon -w src --exec \"babel-node src --presets env\"" - 他会打印
Luke Luke - 注意:
- 我们在 import export 的时候,要注意默认值的问题
- 1.在 import 的时候,要把变量名 放在花括号
{}里, 如import { name } from './ex' - 2.但是,在导出 默认值 的时候 是可以直接导出的
// /src/ex.js const age = 19 export default age
import age from './ex' // 或者 import ageeee from './ex' // 或者 import yourAge from './ex'
- 在导出的时候,可以 更改变量名
- 但,上面那种,不是导出默认值的,不能直接更改变量名
- 可以这样改
import { resolve as r } from 'path'
- 可以这样改
- 批量导出
// /src/ex.js export const name = 'Luke' export const getName = () => { return name } const age = 19 export default age // 批量导出 export { name as name2, getName as getName2, age }
// /src/index.js // 批量导入 import { name2 as name3, getName2 as getName3, age as age3 }
- 执行
-
-
-
- 在上一节中,我们通过介绍 使用 nodemon 来监听代码修改 ,然后使用 babel-node 实时执行代码
- 以达到 实时修改,实时编译,实时服务重启
- 那么,到了线上的时候,就需要有一份编译后的 静态脚本 来运行
- 在上一节中,我们通过介绍 使用 nodemon 来监听代码修改 ,然后使用 babel-node 实时执行代码
-
// /package.json { "scripts": { "dev": "nodemon -w src --exec \"babel-node src --presets env\"", "build": "babel src -s -D -d dist --presets env" } }
-
- 在每次执行编译的时候,我们希望 每次编译前都能自动删除 dist 目录下所有文件,然后重新编译
- 借助 rimraf 来实现这个 删除操作
- rimraf dist 删除这个文件夹
// /package.json { "scripts": { "dev": "nodemon -w src --exec \"babel-node src --presets env\"", "build": "rimraf dist && babel src -s -D -d dist --presets env" } }
- 安装 rimraf
npm i rimraf -D
- 执行代码
npm run build
-
- 5-1.问题描述:
- 当我们在编译 async function 的时候 会报错
- bable 编译的时候 配置的不太正确
- 5-2.原因
- async function 转 generator function 的时候,
- async function 是 ES7 的特性,但是 目前的 babel 是只支持 ES6 的,所以会报错
- 5-3.问题重现
// /src/index.js import { promisify } from 'util' import { resolve as r } from 'path' import { readFile, writeFileSync as wfs } from 'fs' import * as qs from 'querystring' promisify(readFile)(r(__dirname, '../package.json')) .then(data => { data = JSON.parse(data) console.log(data.name) wfs(r(__dirname, './name_demo.js'), String(data.name), 'utf8') }) .catch(err => { console.log(err) }) // async function async function init () { let data = await promisify(readFile)(r(__dirname, '../package.json')) data = JSON.parse(data) console.log(data.name) } init()
// /package.json { "scripts": { "dev": "nodemon -w src --exec \"babel-node src --presets env\"", "build": "rimraf dist && babel src -s -D -d dist --presets env" } }
- 编译完后,执行
node dist/index.js - 然后就会报错
/Users/limi/Documents/Node.js-Koa2-the-movie-trailer-site/project/dist/index.js:5 var _ref = _asyncToGenerator( /*#__PURE__*/regeneratorRuntime.mark(function _callee() { ^ ReferenceError: regeneratorRuntime is not defined at /Users/limi/Documents/Node.js-Koa2-the-movie-trailer-site/project/dist/index.js:5:48 at Object.<anonymous> (/Users/limi/Documents/Node.js-Koa2-the-movie-trailer-site/project/dist/index.js:33:2) at Module._compile (internal/modules/cjs/loader.js:959:30) at Object.Module._extensions..js (internal/modules/cjs/loader.js:995:10) at Module.load (internal/modules/cjs/loader.js:815:32) at Function.Module._load (internal/modules/cjs/loader.js:727:14) at Function.Module.runMain (internal/modules/cjs/loader.js:1047:10) at internal/main/run_main_module.js:17:11
- 编译完后,执行
- 5-4.解决问题
- 安装两个插件
- 一个是 babel 的运行环境,一个是 babel 插件的编译 运行环境
npm i -S babel-plugin-transform-runtime babel-runtime
- 修改 babel 配置
{ "presets": [ [ "env", { "targets": { "node": "current" } } ] ], "plugins": [ [ "transform-runtime", { "polufill": false, "regenerator": true } ] ] }
- 重新编译
npm run build - 执行 `node dist/index.js
- 这样 就不会报错了`
- 安装两个插件
- 5-1.问题描述:
-
-
-
- Koa 和 Express 其实是一样的
- 都是 Node.js 上的 web 服务框架
- 他们都是围绕 核心服务 而展开的
- 那么 什么是核心服务呢?
- 1.接收 HTTP 请求
- 2.
HTTP -> 接收 -> 解析 -> 响应 - 3.
中间件 执行上下文
- 其中 响应,可以返回 html页面、JSON 文本
- 在
解析请求和响应请求之间 会有一些 第三方的中间件- 如 日志、表单解析... 来增强服务能力
- 执行上下文
- 可以理解为 HTTP 请求周期内的
作用域环境 - 来托管请求响应 和 中间件,方便它们之间 互相访问
- 可以理解为 HTTP 请求周期内的
- 应用服务对象
Application Context Request Response Middlewares Session Cookie
- Koa 和 Express 其实是一样的
-
// /server/index.js const Koa = require('koa') const app = new Koa() app.use(async (ctx, next) => { ctx.body = 'Hi Luck' }) app.listen(2333)
- 安装 koa
npm i koa -S - 启动服务
node server/index.js - 访问网站
localhost:2333
- 安装 koa
-
- 在 node_modules 中找到 koa,打开 package.json
- 其中 main 就是 koa 的入口文件
"main": "lib/application.js",
-
-
- 源码解读,具体请查看视频
- 1.其实,我们在 起一个 Koa 服务的时候,只需要3行代码就够了
const app = new Koa() // Application app.use(middleware) app.listen(2333)
- 2.Application 思维导图
Application - Class App extends Emitter - constructor - use - listen - this.callback() - callback - createContext - handleRequest - compose(middlewares) - context - request/response - context.app = this - context.req/res = req/res - request/response - ctx - context - cookies/ip - respond - res.end - buffer - string - stream.pipe - json
- 3.Application 核心源码
// Koa/application.js module.exports = class Application extends Emitter { constructor(options) { super(); options = options || {}; this.proxy = options.proxy || false; this.subdomainOffset = options.subdomainOffset || 2; this.proxyIpHeader = options.proxyIpHeader || 'X-Forwarded-For'; this.maxIpsCount = options.maxIpsCount || 0; this.env = options.env || process.env.NODE_ENV || 'development'; if (options.keys) this.keys = options.keys; this.middleware = []; this.context = Object.create(context); this.request = Object.create(request); this.response = Object.create(response); if (util.inspect.custom) { this[util.inspect.custom] = this.inspect; } } listen(...args) { debug('listen'); const server = http.createServer(this.callback()); return server.listen(...args); } use(fn) { debug('use %s', fn._name || fn.name || '-'); this.middleware.push(fn); return this; } callback() { const fn = compose(this.middleware); if (!this.listenerCount('error')) this.on('error', this.onerror); const handleRequest = (req, res) => { const ctx = this.createContext(req, res); return this.handleRequest(ctx, fn); }; return handleRequest; } handleRequest(ctx, fnMiddleware) { const res = ctx.res; res.statusCode = 404; const onerror = err => ctx.onerror(err); const handleResponse = () => respond(ctx); onFinished(res, onerror); return fnMiddleware(ctx).then(handleResponse).catch(onerror); } createContext(req, res) { const context = Object.create(this.context); const request = context.request = Object.create(this.request); const response = context.response = Object.create(this.response); context.app = request.app = response.app = this; context.req = request.req = response.req = req; context.res = request.res = response.res = res; request.ctx = response.ctx = context; request.response = response; response.request = request; context.originalUrl = request.originalUrl = req.url; context.state = {}; return context; } onerror(err) { if (!(err instanceof Error)) throw new TypeError(util.format('non-error thrown: %j', err)); if (404 == err.status || err.expose) return; if (this.silent) return; const msg = err.stack || err.toString(); console.error(); console.error(msg.replace(/^/gm, ' ')); console.error(); } };
-
- 源码解读,详情看视频
-
- 源码解读,详情看视频
-
- 源码解读,详情看视频
-
- 源码解读,详情看视频
-
- 源码解读,详情看视频
- 在中间件执行的策略中,是会先通过 koa-compose,来吧这些 中间件 来组合到一起,一个接一个的 把数组里面的函数 依次执行,通过一个 next() 中间的回调函数 不断的将 控制权(执行权) 向下传递
- 理解了 koa-compose 就理解了 koa 的洋葱模型,也是理解 koa中间件 的关键
- 洋葱模型: 一层层进去,处理核心业务,然后再一层层出来
-
- 参考我的其他两篇 学习笔记
-
-
什么是纯函数?
- 对于一个函数,如果 输入一个的变量 X , 那么它一定能输出一个结果 y
- 不管调用多少次,只要 x 相等,那么得到的 y 也一定相等
-
举个例子
function pure (x) { return x + 1 } console.log(pure(1)) console.log(pure(1)) console.log(pure(1)) console.log(pure(1))
-
- 1.不管你调用多少次,只要入参一样,那么输出的结果也一样
- 2.纯函数与外界交换数据,只有一个渠道,就是入参 的参数 与返回值
- 3.
无副作用:既不依赖,也不会改变全局的状态
-
为什么要提到 纯函数 和 函数式 编程?
- 因为一个函数 一旦纯化之后,他就可以像积木一样,跟更多的函数进行组合 compose
- 而这种
可组合又是函数式编程非常重要的概念
-
参考文章
-
-
-
先来看个 基础递归 的例子
function tail (i) { if (i > 3) return console.log('修改前', i) tail(i + 1) console.log('修改后', i) } tail(0) // 打印结果 修改前 0 修改前 1 修改前 2 修改前 3 修改后 3 修改后 2 修改后 1 修改后 0
- 每次递归的时候,程序都会保存当前的方法调用栈,我们执行
tail(2)的时候必须要记住,之前是如何调用tail(1)的,这样的话 才能在执行完毕tail(2)之后,返回到tail(1)的下一行代码 来打印一下console.log('修改后', i) - 缺点:
- 在整个函数执行过程中,需要记住太多的 堆栈深度、堆栈状态 比较浪费性能
- 每次递归的时候,程序都会保存当前的方法调用栈,我们执行
-
把上面的函数 改成 尾递归
function tail (i) { if (i > 3) return i console.log('修改前', i) return tail(i + 1) } tail(0) // 打印结果 修改前 0 修改前 1 修改前 2 修改前 3
- 这样修改后:
- 它每次调用的结果,就是下次执行的入参
- 这样修改后:
-
参考文章
-
什么是 尾递归?
- 1.函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
- 2.如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。
-
-
1.尾调用的概念非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
function f(x){ return g(x); }
上面代码中,函数f的最后一步是调用函数g,这就叫尾调用。
-
2.以下两种情况,都不属于尾调用。
// 情况一 function f(x){ let y = g(x); return y; } // 情况二 function f(x){ return g(x) + 1; }
上面代码中,情况一是调用函数g之后,还有别的操作,所以不属于尾调用,即使语义完全一样。情况二也属于调用后还有操作,即使写在一行内。
-
3.尾调用不一定出现在函数尾部,只要是最后一步操作即可。
function f(x) { if (x > 0) { return m(x) } return n(x) }
上面代码中,函数m和n都属于尾调用,因为它们都是函数f的最后一步操作。
-
-
-
- 源码解读,详情看视频
npm i koa-session-
-
- session 原理
- 客户端 和 服务端 有一个会话
- 这个会话会 交流并保存 一些状态 (变量),如 登陆状态、参数变量 ... 等
- 直接来看个直观的
Response Headers Connection: keep-alive Content-Length: 7 Content-Type: text/plain; charset=utf-8 Date: Thu, 02 Jan 2020 08:07:42 GMT Set-Cookie: koa:sess=eyJ2aWV3cyI6NSwiX2V4cGlyZSI6MTU3ODAzODg2MjIyOCwiX21heEFnZSI6ODY0MDAwMDB9; path=/; expires=Fri, 03 Jan 2020 08:07:42 GMT; httponly Set-Cookie: koa:sess.sig=vLtDOmkiYkcjEX3ouxAfg_NULhI; path=/; expires=Fri, 03 Jan 2020 08:07:42 GMT; httponly
- 其中
Set-Cookie: koa:sess=ID;这个id 就是 session id,每一个用户的身份识别,就是靠这个 session id 了
- 其中
- session 原理
-
// /server/index.js const Koa = require('koa') const session = require('koa-session') const app = new Koa() app.keys = ['Hi Luke']; app.use(session(app)); // app.use(session(CONFIG, app)); 当不传config的时候 使用 默认配置 app.use(ctx => { // ignore favicon if (ctx.path === '/favicon.ico') return let n = ctx.session.views || 0 ctx.session.views = ++n ctx.body = n + ' views' }) app.listen(2333)
- 执行结果
- 启动服务器后,访问
localhost:2333 - 显示
1 views,刷新一次2 views,再刷新一次3 views... 以此类推
- 启动服务器后,访问
- 执行结果
-
-
- 什么是路由?
- 一个网站 肯定有很多
不同的页面,不同的页面对应不同的URL地址,服务器要能识别出不同的页面,然后给不同的页面返回不同的结果。这个时候就需要用到路由了
- 一个网站 肯定有很多
- 最简示例
const Koa = require('koa') const session = require('koa-session') const app = new Koa() app.keys = ['Hi Luke']; app.use(session(app)); app.use(ctx => { if (ctx.path === '/favicon.ico') return if (ctx.path === '/') { let n = ctx.session.views || 0 ctx.session.views = ++n ctx.body = n + ' views' } else if (ctx.path == '/hi') { ctx.body = 'Hi Luke' } else { ctx.body = '404' } }) app.listen(2333)
- 原理 就是这样
- 我们后面是不会使用这么简单的方式,而是 使用第三方的中间件
- 什么是路由?
-
- 1.在 Koa 里一切的流程都是中间件
- 2.一个 HTTP请求 进入了 Koa 之后,都会流经 预先配置好的中间件 (middlewares)
- 3.在中间件执行的策略中,是会先通过 koa-compose,来吧这些 中间件 来组合到一起,一个接一个的 把数组里面的函数 依次执行,通过一个
next()中间的回调函数 不断的将 控制权(执行权) 向下传递- 理解了 koa-compose 就理解了 koa 的洋葱模型,也是理解 koa中间件 的关键
- 4.每一个中间件 都会拿到整个 HTTP 请求的上下文 (也就是
context),通过 context 能访问到request对象,也能访问到respond对象,而且能访问到 他们上面的属性 和方法 - 5.
请求上下文:贯穿中间件的请求上下文,也就是 context、request、respond 之间互相引用,方便调用。- 特别是 request, respond 他们在 Koa中 分别扩展出两个对象,它们两个并非是 node 原生的对象。
- Node 原生的是 req res
- 6.
request, respond和req, res因为互相引用,所以我们能够通过context来访问到request, respond是 Koa扩展对象req, res是 Node原生对象
- 7.通过这一章 源代码 读下来之后,发现,其实只有4个 核心概念
- 请求上下文 context
- 请求对象 request
- 响应对象 respond
- 中间件 middlewares
- 8.但是真正复杂的是
- HTTP协议
- 资源
- TCP/IP 相关的网络通信知识
- 前后端请求的策略设定
- 请求流程的性能优化
- 以上这些都不是属于 Koa web服务框架中的知识,但却是 这个框架之上的硬知识
-
-
本节目标
- 通关例子讲解,帮助大家理解 koa2 和 koa1 的异同之处
-
1.先来看个 koa1 的例子
var Koa = require('koa') var app = new Koa() var logger = require('koa-logger') // 打印日志,第三方模块 var indent = function (n) { return new Array(n).join(' ') } var mid1 = function () { return function *(next) { this.body = '<h3>请求 => 第一层中间件</h3>' yield next this.body += '<h3>请求 <= 第一层中间件</h3>' } } var mid2 = function () { return function *(next) { this.body += '<h3>请求' + indent(4) + ' => 第二层中间件</h3>' yield next this.body += '<h3>请求' + indent(4) + ' <= 第二层中间件</h3>' } } var mid3 = function () { return function *(next) { this.body += '<h3>请求' + indent(8) + ' => 第三层中间件</h3>' yield next this.body += '<h3>请求' + indent(8) + ' <= 第三层中间件</h3>' } } app.use(logger()) app.use(mid1()) app.use(mid2()) app.use(mid3()) app.use(function *(next) { this.body += '<p style="color: #f60">' + indent(12) + 'Koa 核心处理业务</p>' }) app.listen(2333)
- 执行之前,先安装 koa1
npm i koa@1.2.0 koa-logger@1.3.0 -S-S 是保存- 切换koa版本
- 直接
npm i koa@1.2.0 -S即可 - 切换到 koa2
npm i koa@2.4.1 -S
- 直接
- koa-logger 的作用
- 在命令行中打印日志
node server // 启动服务 <-- GET / --> GET / 200 12ms 342b
- 执行之前,先安装 koa1
-
2.再来看个 koa2 的例子
- 把koa1改成koa2
- 1.把所有 var 改成 const / let
- 2.把所有 function 都改成 箭头函数
- 3.把 generator function 改成 async function
- 4.把
this.body改成ctx.body - 5.把 yield next 改成 await next
- 6.把字符串拼接的方式,改成模版字符串
'<h3>请求' + indent(4) + ' => 第二层中间件</h3>' // 改成 `<h3>请求${indent(4)} <= 第二层中间件</h3>`
const Koa = require('koa') const app = new Koa() const logger = require('koa-logger') // 打印日志,第三方模块 const indent = (n) => new Array(n).join(' ') const mid1 = () => { return async (ctx, next) => { ctx.body = `<h3>请求 => 第一层中间件</h3>` await next() ctx.body += `<h3>请求 <= 第一层中间件</h3>` } } const mid2 = () => { return async (ctx, next) => { ctx.body += `<h3>请求${indent(4)} => 第二层中间件</h3>` await next() ctx.body += `<h3>请求${indent(4)} <= 第二层中间件</h3>` } } const mid3 = () => { return async (ctx, next) => { ctx.body += `<h3>请求${indent(8)} => 第三层中间件</h3>` await next() ctx.body += `<h3>请求${indent(8)} <= 第三层中间件</h3>` } } app.use(logger()) app.use(mid1()) app.use(mid2()) app.use(mid3()) app.use(async (ctx, next) => { ctx.body += `<p style="color: #f60">${indent(12)}Koa 核心处理业务</p>` }) app.listen(2333)
- 执行结果
请求 => 第一层中间件 请求 => 第二层中间件 请求 => 第三层中间件 Koa 核心处理业务 请求 <= 第三层中间件 请求 <= 第二层中间件 请求 <= 第一层中间件
- 把koa1改成koa2
-
3.总结
- 1.依托的方式不一样
- koa1 依托于 generator function ,以及 配套的 co库
- koa2 依托于 async function
- 2.语法
- koa1 语法主要以 ES5 为主,有部分ES6
- koa2 语法跟进新规范 ES6 ES7
- 3.koa2 koa1 中间件 执行特征、链路 虽然相似,但是 代码层面的设计策略 执行逻辑稍微不一样
- 1.依托的方式不一样
-
-
- koa 与 express 其实是同一班人的 开发者
- express
- 出现的够早,占了整个市场的先机,市场份额大
- 当时还没有 成熟的 generator function , async function 这些语言规范的推出
- 从最开始的 大而全,囊括大部分中间件 -> 到后面 抽离出这些 中间件
- 每次大升级 都会引发社区火热的讨论
- 这充分说明 express 有很好的 社区支持 和群众基础
-
- express
- 提供更多的控制权 和 配置权
- 更让人省心,拿过来就能用,不需要操心太多 定制的东西
- koa
- koa 比 express 更容易做底层的深度定制
- express
- api 对比
Koa - cosnt app = new Koa() - app - settings - env - proxy - subdomains - listen(3000) - callback() - use( async () ) - keys = [] - context - on('error') - ctx API - req - res - request - header - headers - methods - url - originUrl - origin - href - path - query - queryString ??????? - host - hostname - fresh - stale - socket - protocol - secure - ip - ips - subdomains - is() - accepts() - acceptEncodings() - acceptCharsets() - acceptLanguages() - get() - respond - ctx - body - status - message - length - type - headerSent - redirect() - attachment() - set() - append() - lastModified - etag - state - app - cookies.get() - cookies.set() - throw() - assert() - respond() - method - url - path
Express - const app = express() - app - settings - env - trust proxy - json callback name - json replace - case sensitive routing - strict routing - view cache - view engine - views - set() - get() - enable() - enabled() - disable() - use() - listen() - engine() - param() - VERB - get('/a/:b') - all() - route() - locals() - render() - request - req - query - params - param() - route - cookies - signedCookies - get() - accepts() - acceptsCharset() - acceptsLanguage() - is() - ip - ips - path - host - fresh - stale - xhr - protocol - secure - subdomains - originUrl - respond - res - status() - set() - get() - redirect() - cookie() - clearCookie() - location() - send() - json() - jsonp() - type() - format() - attachment() - sendfile() - download() - links() - locals() - locals - render()
-
-
- 安装
npm i express -S - 用 express 起一个服务
const express = require('express') const app = express() app.get('/', (req, res) => { res.send('Hi Luke') }) app.listen(2334)
- 把之前 4-1 koa2与koa1 的用法对比 中 koa2 使用中间件的代码,改成 express
- 改动
- 把 async function 改成 普通箭头函数
- 把
(ctx, next) => {}改成(req, res, next) => {} - 把
await next()改成next() - 把
ctx.body改成res.body - 最后
// koa app.use((ctx, next) => { ctx.body += `<p style="color: #f60">${indent(12)}Koa 核心处理业务</p>` })
- 改成
// express app.get('/', (req, res, next) => { res.send( `${res.body}<p style="color: #f60">${indent(12)}Koa 核心处理业务</p>`) })
- 改动
// express 使用中间件 const express = require('express') const app = express() const indent = (n) => new Array(n).join(' ') const mid1 = () => { return (req, res, next) => { res.body = `<h3>请求 => 第一层中间件</h3>` next() res.body += `<h3>请求 <= 第一层中间件</h3>` } } const mid2 = () => { return (req, res, next) => { res.body += `<h3>请求${indent(4)} => 第二层中间件</h3>` next() res.body += `<h3>请求${indent(4)} <= 第二层中间件</h3>` } } const mid3 = () => { return (req, res, next) => { res.body += `<h3>请求${indent(8)} => 第三层中间件</h3>` next() res.body += `<h3>请求${indent(8)} <= 第三层中间件</h3>` } } app.use(mid1()) app.use(mid2()) app.use(mid3()) app.get('/', (req, res, next) => { res.send( `${res.body}<p style="color: #f60">${indent(12)}Express 核心处理业务</p>`) }) app.listen(2334)
- 执行结果
请求 => 第一层中间件 请求 => 第二层中间件 请求 => 第三层中间件 Express 核心处理业务
- 安装
-
const Koa = require('koa') const app = new Koa() const logger = require('koa-logger') // 打印日志,第三方模块 const indent = (n) => new Array(n).join(' ') const mid1 = () => { return async (ctx, next) => { ctx.body = `<h3>请求 => 第一层中间件</h3>` await next() ctx.body += `<h3>请求 <= 第一层中间件</h3>` } } const mid2 = () => { return async (ctx, next) => { ctx.body += `<h3>请求${indent(4)} => 第二层中间件</h3>` await next() ctx.body += `<h3>请求${indent(4)} <= 第二层中间件</h3>` } } const mid3 = () => { return async (ctx, next) => { ctx.body += `<h3>请求${indent(8)} => 第三层中间件</h3>` await next() ctx.body += `<h3>请求${indent(8)} <= 第三层中间件</h3>` } } app.use(logger()) app.use(mid1()) app.use(mid2()) app.use(mid3()) app.use(async (ctx, next) => { ctx.body += `<p style="color: #f60">${indent(12)}Koa 核心处理业务</p>` }) app.listen(2333)
- 执行结果
请求 => 第一层中间件 请求 => 第二层中间件 请求 => 第三层中间件 Koa 核心处理业务 请求 <= 第三层中间件 请求 <= 第二层中间件 请求 <= 第一层中间件
- 执行结果
-
- 1.进出模型
- 观察
- Koa 的中间件 是一个
洋葱模型,一层层进去,然后一层层出来 - 但是在 Express 里面,虽然代码 也是这样写的,中间件也生效了
- Express 的整个链路 只进不出
- Koa 的中间件 是一个
- 总结:如果不借助外力,仅仅是语言本身的能力,Express 是很难做到, 跟 Koa 一样 数据流入流出能力的
- 如果 express 想要一层层进去,目前这些代码是不够的,我们需要加上
事件触发,类似这样的机制,才能保证 它跟 koa 一样的进出模型
- 观察
- 2.编程体验上
- express,是这种常规的编程模型
- koa,是 async function 这种新语言特性
- 3.中间件
- express,是单向流动。而且需要借助事件机制,才能保障 一个数据进去之后 能够返程流动
- koa,由于有语法特性,又加强了 异步编程模型,所以 整个 HTTP流 处理起来 就非常的灵活。
- 这是非常美妙的编程体验,不仅仅是写起来爽
- koa 中间件的模型,运行起来的过程 非常的清晰,无论是调试、捕捉异常、做加减法的维护 都非常的轻松
- 1.进出模型
-
当一个中间件调用 next() 则该函数暂停并将控制传递给定义的下一个中间件。当在下游没有更多的中间件执行后,堆栈将展开并且每个中间件恢复执行其上游行为。
| | | middleware 1 | | | | +-----------------------------------------------------------+ | | | | | | | middleware 2 | | | | | | | | +---------------------------------+ | | | | | | | | | action | action | middleware 3 | action | action | | 001 | 002 | | 005 | 006 | | | | action action | | | | | | 003 004 | | | | | | | | | +----------------------------------------------------------------------------------> | | | | | | | | | | | | | | +---------------------------------+ | | | +-----------------------------------------------------------+ | +----------------------------------------------------------------------------------+先写一段贯穿全文的koa的代码
const Koa = require('koa'); let app = new Koa(); const middleware1 = async (ctx, next) => { console.log(1); await next(); console.log(6); } const middleware2 = async (ctx, next) => { console.log(2); await next(); console.log(5); } const middleware3 = async (ctx, next) => { console.log(3); await next(); console.log(4); } app.use(middleware1); app.use(middleware2); app.use(middleware3); app.use(async(ctx, next) => { ctx.body = 'hello world' }) app.listen(3001) // 输出1,2,3,4,5,6
await next()使每个middleware分成,前置操作,等待其他中间件操作可以观察到中间件的特性有:
- 上下文ctx
- await next()控制前后置操作
- 后置操作类似于数据解构-栈,先进后出
-
-
- koa 是基于新的语法特性,实现了 promise 链的传递
- 错误处理 也更友好
- koa 不绑定任务中间件,是非常干净的 裸的框架
- 如果 express 是
大而全,那么 koa 就是小而精,两者定位不同- koa 扩展性 非常好,只要装几个中间件 就马上可以跟 express 匹敌了
- koa 代码质量高,设计理念先进,语法特性比较超前
-
- 网站前台
- 首页
- 展示电影海报 和 部分信息
- 首页顶部 有电影分类
- 视频:点击首页海报图 弹出视频 弹窗
- 详情页:点击首页 电影标题 进入详情页,详情页内 又同类电影推荐
- 首页
- 网站后台
- 后台登陆功能
- 后台管理页面:展示 爬取到的 所有电影列表
- 网站前台
-
- github 新建仓库,并 clone 到本地
-
// /server/index.js const Koa = require('koa') const app = new Koa() const { normal } = require('./template') app.use(async (ctx, next) => { ctx.type = 'text/html; charset=utf-8' ctx.body = normal }) app.listen(2333)
// /server/template/index.js const normalTpl = require('./normal') module.exports = { normal: normalTpl }
// /server/template/normal.js module.exports = ` <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> hello world </body> </html> `
-
-
本节介绍3个 模版引擎
- ejs
- pug
- jage
-
BootCDN CDN 加速服务
-
- https://github.com/tj/ejs
- 安装
npm i ejs
// /server/template/ejs.js module.exports = ` <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> hello world <h1>Hi <%= you %></h1> <p>this is <%= me %></p> </body> </html> `
- 其中
<%= you %>里面放的是变量名
// /server/index.js const Koa = require('koa') const app = new Koa() const ejs = require('ejs') const { ejsTpl } = require('./template') app.use(async (ctx, next) => { ctx.type = 'text/html; charset=utf-8' ctx.body = ejs.render(ejsTpl, { you: 'Luke', // 为模版里的变量赋值 me: 'Scott' }) }) app.listen(2333)
// /server/template/index.js module.exports = { ejsTpl: require('./ejs') }
-
- https://github.com/pugjs/pug
- 安装
npm i pug
// /server/template/pug.js module.exports = ` doctype html html head meta(charset="utf-8") meta(name="viewport", content="width=device-width, initial-scale=1") title Koa Server Pug link(href="https://cdn.bootcss.com/animate.css/3.7.2/animate.css" rel="stylesheet") script(src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js") body .container .row .clo-md-8 h1 Hi #{you} p This is #{me} .clo-md-4 p 测试动态 Pug 页面 `
// /server/index.js const Koa = require('koa') const app = new Koa() const pug = require('pug') const { pugTpl } = require('./template') app.use(async (ctx, next) => { ctx.type = 'text/html; charset=utf-8' ctx.body = pug.render(pugTpl, { you: 'Luke 111', me: 'Scott 22' }) }) app.listen(2333)
// /server/template/index.js module.exports = { normal: require('./normal'), ejsTpl: require('./ejs'), pugTpl: require('./pug') }
-
-
- 存在的问题
- 在上一节中,我们使用模版引擎,都是通过 拼接字符串的方式
- 这种方式不是不行,只是比较的人肉,比较麻烦
- 那么,这一节,我们通过使用
模版引擎中间件的形式 集成到项目里
- 解决问题
- 在 github 搜索 koa-views
- 点击 List of supported engines 查看支持的
模版引擎 - 这节 我们选择 pug 模版引擎
-
- 安装
npm i koa-views
// /server/index.js const Koa = require('koa') const app = new Koa() const views = require('koa-views') const { resolve } = require('path') app.use(views(resolve(__dirname, './views'), { // 配置 koa-views extension: 'pug' })) app.use(async (ctx, next) => { await ctx.render('index', { you: 'Luke', me: 'Scoot' }) }) app.listen(2333)
// /server/views/index.pug doctype html html head meta(charset="utf-8") meta(name="viewport", content="width=device-width, initial-scale=1") title Koa Server Pug link(href="https://cdn.bootcss.com/animate.css/3.7.2/animate.css" rel="stylesheet") script(src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js") body .container .row .clo-md-8 h1 Hi #{you} p This is #{me} .clo-md-4 p 测试动态 Pug 页面
- 安装
-
- 选择 pug 到原因
- 语法简洁
- 支持 模版继承
- 支持 模块声明
- 项目目录
+ |- /dist + |- /node_modules + |- /server + |- /template + |- /views |- index.pug + |- /layouts 页面布局 |- default.pug + |- /includes 公用模块 |- script.pug |- style.pug |- index.js + |- /src |- package-lock.json |- package.json - pug 语法
include ../includes/style引入extends ./layouts/default继承block contentblock 定义模块block content //定义模块,模块名 content .container .row .clo-md-8 h1 Hi #{you} p This is #{me} .clo-md-4 p 测试动态 Pug 页面
- pug 模块拆分
// /server/views/index.pug extends ./layouts/default // 继承 block title // 模块定义 title Koa Douban 首页 block content .container .row .clo-md-8 h1 Hi #{you} p This is #{me} .clo-md-4 p 测试动态 Pug 页面
// /server/views/layouts/default.pug doctype html html head meta(charset="utf-8") meta(name="viewport", content="width=device-width, initial-scale=1") block title include ../includes/style body block content include ../includes/script
// /server/views/includes/script.pug script(src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js")
// /server/views/includes/style.pug link(href="https://cdn.bootcss.com/animate.css/3.7.2/animate.css" rel="stylesheet")
- 选择 pug 到原因
- 存在的问题
-
test pull request
-
-
DPlayer
- DPlayer github
- H5播放器,B站也在用这个播放器,可添加弹幕
-
项目目录
+ |- /dist + |- /node_modules + |- /server + |- /template + |- /views |- index.pug + |- /layouts 页面布局 |- default.pug + |- /includes 公用模块 |- header.pug |- script.pug |- style.pug |- index.js + |- /src |- package-lock.json |- package.json -
代码
// /server/index.js const Koa = require('koa') const app = new Koa() const views = require('koa-views') const { resolve } = require('path') app.use(views(resolve(__dirname, './views'), { extension: 'pug' })) app.use(async (ctx, next) => { await ctx.render('index', { you: 'Luke', me: 'Scoot' }) }) app.listen(2333)
// /server/views/index.pug extends ./layouts/default block title title Koa Douban 首页 block content style. header{ position: -webkit-sticky; position: sticky; top: 0; background: #00474f; color: #e7dacb; display: flex; justify-content: space-between; align-items: center; height: 50px; z-index: 500; } @media (min-width: 768px) { .sidebar { position: -webkit-sticky; position: sticky; top: 4rem; z-index: 1000; height: calc(100vh - 4rem); border-right: 1px solid rgba(0,0,0,.1); order: 0; border-bottom: 1px solid rgba(0,0,0,.1); } .cat-links { display: block!important; max-height: calc(100vh - 9rem); overflow-y: auto; padding-top: 1rem; padding-bottom: 1rem; margin-right: -15px; margin-left: -15px; } .modal-dialog { max-width: 800px; } } .sidebar-link { display: block; padding: .25rem 1.5rem; font-weight: 500; color: rgba(0,0,0.65) } .sidebar .nav>li>a{ display: block; padding: .25rem 1.5rem; font-size: 90%; color: rgba(0,0,0,.65) } .sidebar-item.active > .sidebar-inner { display: block; } .card{ margin-bottom: 1.5rem; } .swithcher{ position: relative; padding: 1rem 15px; margin-right: -15px; margin-left: -15px; border-bottom: 1px solid rgba(0,0,0,.05) } .sidebar-toggle{ line-height: 1; color: #212529; } .p-0{ padding: 0!important; } .ml-3, .mx-3{ margin-left: 1rem!important; } .btn-link{ font-weight: 400; color: #007bff; background-color: transparent; } include ./includes/header .container-fluid .row .col-12.col-md-3.col-xl-2.sidebar .collapse.cat-links .sidebar-item.active a.sidebar-link(href='/') Links ul.nav.sidebar-inner li.active.sidebar-inner-active a(href='/') Link1 li.sidebar-inner-active a(href='/') Link2 .col-12.col-md-9.col-xl-9.py-md-3.pl-md-5.content .row .col-md-6 .card img.card-img-top(src="https://img9.doubanio.com/view/photo/l/public/p2567198874.webp", data-video="http://vfx.mtime.cn/Video/2017/03/31/mp4/170331093811717750.mp4", data-title='小丑 Joker (2019)' data-toggle="modal", data-target="#exampleModal") .card-body h4.card-title 小丑 Joker (2019) p.card-desc 这是电影描述 .card-footer small.text-muted 1 天前更新 .col-md-6 .card img.card-img-top(src="https://img9.doubanio.com/view/photo/l/public/p2578045524.webp", data-video="http://clips.vorwaerts-gmbh.de/big_buck_bunny.mp4", data-title='82年生的金智英 82년생 김지영 (2019)' data-toggle="modal", data-target="#exampleModal") .card-body h4.card-title 82年生的金智英 82년생 김지영 (2019) p.card-desc 这是电影描述 .card-footer small.text-muted 1 天前更新 .row .col-md-6 .card img.card-img-top(src="https://img9.doubanio.com/view/photo/l/public/p2568902055.webp", data-video="http://www.w3school.com.cn/example/html5/mov_bbb.mp4", data-title='爱尔兰人 The Irishman' data-toggle="modal", data-target="#exampleModal") .card-body h4.card-title 爱尔兰人 The Irishman p.card-desc 这是电影描述 .card-footer small.text-muted 1 天前更新 .col-md-6 .card img.card-img-top(src="https://img1.doubanio.com/view/photo/l/public/p2571760178.webp", data-video="https://media.w3.org/2010/05/sintel/trailer.mp4", data-title='婚姻故事 Marriage Story' data-toggle="modal", data-target="#exampleModal") .card-body h4.card-title 婚姻故事 Marriage Story p.card-desc 这是电影描述 .card-footer small.text-muted 1 天前更新 <!-- Modal --> <div class="modal fade" id="exampleModal" tabindex="-1" role="dialog" aria-labelledby="exampleModalLabel" aria-hidden="true"> <div class="modal-dialog" role="document"> <div class="modal-content"> <div class="modal-header"> <h5 class="modal-title" id="exampleModalLabel">Modal title</h5> <button type="button" class="close" data-dismiss="modal" aria-label="Close"> <span aria-hidden="true">×</span> </button> </div> <div class="modal-body"> <div id="dplayer" referrerpolicy ="never"></div> </div> </div> </div> </div> include ./includes/script script. var player = null $(function(){ $('.card-img-top').click(function(){ var title = $(this).data('title') var video = $(this).data('video') var image = $(this).attr('src') $('.modal-title').text(title) player = new DPlayer({ container: document.getElementById('dplayer'), video: { url: video, pic: image, thumbnails: image }, }); }) })
// /server/views/layouts/default.pug doctype html html head meta(charset="utf-8") meta(name="viewport", content="width=device-width, initial-scale=1") block title include ../includes/style body block content
// /server/views/includes/header.pug header.navbar.narbar-expand.navbar-dark.flex-column.flex-md-row a.navbar-brand.mr-0.mr-md-2(href='/') 豆瓣预告片 .navbar-nav-scroll ul.navbar-nav.bd-navbar-nav.flex-row li.nav-item a.nav-link.active(href='/link1') 快捷连接 1
// /server/views/includes/script.pug script(src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js") script(src="https://cdn.bootcss.com/bootstrap/4.0.0-beta.2/js/bootstrap.bundle.min.js") script(src="https://cdn.jsdelivr.net/npm/dplayer/dist/DPlayer.min.js")
// /server/views/includes/style.pug link(href="https://cdn.bootcss.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css" rel="stylesheet") link(href="https://cdn.jsdelivr.net/npm/dplayer/dist/DPlayer.min.css" rel="stylesheet")
-
-
- 网站框架上 骨架, 网站数据才是 血肉
··············· · · · 动态网站 · · · ··············· - 静态网站 - 数据服务 - Koa2 - 父子进程通信 - 数据爬取 - 储存 - MongoDB - MySQL - 获取 - 模拟浏览器 - phantomJS - NightMare - pupeteer - API同步接口 -
-
- Puppeteer github
- Puppeteer 可以简单理解为 它能够模拟浏览器
- 官方解释:Puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具
- Chrome Headless 必将成为 web 应用
自动化测试的行业标杆
- Chrome Headless 必将成为 web 应用
-
- 安装
npm i puppeteer - 示例
- 对于如何使用 Puppeteer,这非常之容易;如下简易的示例,即实现了:导航到 https://example.com 并将截屏保存为 example.png;
const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://example.com'); await page.screenshot({path: 'example.png'}); await browser.close(); })();
- 安装
// /server/crawler/trailer-list.js const puppeteer = require('puppeteer') console.log('You in...') const url = 'https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=rank&page_limit=20&page_start=0' const sleep = time => new Promise( resolve => { setTimeout(resolve, time) }) ;(async () => { console.log('Start visit the target page...') const browser = await puppeteer.launch({ args: ['--no-sandbox'], dumpio: false }) const page = await browser.newPage() await page.goto(url, { waitUntil: 'networkidle2' // 当网络空闲时。说明网络资源加载完毕 }) await sleep(3000) // 网络空闲时,再继续等待3秒 await page.waitForSelector('.more') // class='more' 的 div for (let i = 0; i < 1; i++ ) { // 只点击按钮一次 await sleep(3000) await page.click('.more') } // 获取网页内容 const result = await page.evaluate(() => { var $ = window.$ // 由于页面中 本身加载了 jQuery,所以这里直接使用就行 var items = $('.list-wp a') // 获取本页面 所有电影列表的 item var links = [] if (items.length >= 1) { // 如果items 不为空 items.each((index, item) => { let it = $(item) let doubanID = it.find('div').data('id') let title = it.find('p').html() let rate = Number(it.find('strong').text()) let poster = it.find('img').attr('src') if(title){ title = title.replace(/[\s|\n\r]/g, '').replace(/<strong>([\s\S]*?)<\/strong>/, '') } if(poster){ // 如果存在。 如果不判断 可能会报错 poster = poster.replace('s_ratio', 'l_ratio') // 将小图片 换成大图片 } links.push({ doubanID, title, rate, poster }) }) } return links }) browser.close() console.log(result) })()
- 执行脚本
node server/crawler/trailer-list.js,然后会打印出下面结果[ { doubanID: 6981153, title: '爱尔兰人', rate: 9, poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2568902055.jpg' }, { doubanID: 27119724, title: '小丑', rate: 8.7, poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2567198874.jpg' }, { doubanID: 26100958, title: '复仇者联盟4:终局之战', rate: 8.5, poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2552058346.jpg' }, // ... ]
-
-
- 对于一个网站,我们通常提到一个词 ——
可用性- 换一个词来描述,就是
稳定 - 服务器上运行的程序、提供的服务 要足够的稳定,不能说挂就挂了
- 换一个词来描述,就是
- 而在 Node.js 它天生就是单线程的,这时候 如果我们在 Node.js 里面跑一个比较 重的服务的话,很容易导致 服务器整个挂掉
- 所以,我们为了不让 服务器有挂掉的风险,我们会在 服务器 里,起若干个
子进程来跑一些其他程序,降低服务器 挂掉的风险 - 这样的话,即使 子进程挂了,主进程还健在
- 所以,我们为了不让 服务器有挂掉的风险,我们会在 服务器 里,起若干个
- fork 可以派生出一个子进程
// /server/tasks/movie.js const cp = require('child_process') const { resolve } = require('path') ;(async () => { // 自动执行函数 const script = resolve(__dirname, '../crawler/trailer-list') const child = cp.fork(script, []) // fork 可以派生出一个子进程。通过 child_process.fork 来执行我们要 跑的脚本 let invoked = false // 表示 这个脚本是否有 执行过 child.on('error', err => { if (invoked) return // 如果执行过,直接 return invoked = true console.log(err) }) child.on('exit', code => { if (invoked) return invoked = true let err = code === 0 ? null : new Error('exit code ' + code) console.log(err) }) child.on('message', data => { let result = data.result console.log(result) }) })()
- 在我们上一节的代码中,只是 简单的 拿到了信息,然后打印了一下
- 现在我们加上
// ... process.send({result}) // 将结果发送出去 process.exit(0) // 退出程序
// /server/crawler/trailer-list.js const puppeteer = require('puppeteer') console.log('You in...') const url = 'https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=rank&page_limit=20&page_start=0' const sleep = time => new Promise( resolve => { setTimeout(resolve, time) }) ;(async () => { console.log('Start visit the target page...') const browser = await puppeteer.launch({ args: ['--no-sandbox'], dumpio: false }) const page = await browser.newPage() await page.goto(url, { waitUntil: 'networkidle2' // 当网络空闲时。说明网络资源加载完毕 }) await sleep(3000) // 网络空闲时,再继续等待3秒 await page.waitForSelector('.more') // class='more' 的 div for (let i = 0; i < 1; i++ ) { // 只点击按钮一次 await sleep(3000) await page.click('.more') } // 获取网页内容 const result = await page.evaluate(() => { var $ = window.$ // 由于页面中 本身加载了 jQuery,所以这里直接使用就行 var items = $('.list-wp a') // 获取本页面 所有电影列表的 item var links = [] if (items.length >= 1) { // 如果items 不为空 items.each((index, item) => { let it = $(item) let doubanID = it.find('div').data('id') let title = it.find('p').html() let rate = Number(it.find('strong').text()) let poster = it.find('img').attr('src') if(title){ title = title.replace(/[\s|\n\r]/g, '').replace(/<strong>([\s\S]*?)<\/strong>/, '') } if(poster){ // 如果存在。 如果不判断 可能会报错 poster = poster.replace('s_ratio', 'l_ratio') // 将小图片 换成大图片 } links.push({ doubanID, title, rate, poster }) }) } return links }) browser.close() console.log(result) process.send({result}) // 将结果发送出去 process.exit(0) // 退出程序 })()
- 执行代码 验证一下
node server/tasks/movies.js
- 对于一个网站,我们通常提到一个词 ——
-
-
前言
- 互联网上的
信息传递,都是基于各种请求和返回, 比如说基于 TCP/IP 的 HTTP 协议 - 而上节课 我们的方法 比较不一样,他是在本地 启动一个 puppeteer 无界面浏览器(Headless browser),
来爬一些 比较难以爬取的数据- 请求网页 -》 分析文本 -》 提取目标信息
- 本节,我们介绍 平常 服务器端 对 服务器端 的数据请求 ,也就是 HTTP 协议请求
- 互联网上的
-
搜索
douban API, 找到 豆瓣API 官网 https://douban-api-docs.zce.me/ -
遇到的问题
- 豆瓣接口调用失败
- http://api.douban.com/v2/movie/subject/1764796
- 当我直接访问上面的连接时,回返回下面的 错误提示
{ msg: "invalid_apikey, Please contact bd-team@douban.com for authorized access.", code: 104, request: "GET /v2/movie/subject/1764796" } - 解:
-
豆瓣API有变化,需要在请求API的url后面跟一个apikey参数:
-
电影列表API:http://api.douban.com/v2/movie/in_theaters?apikey=0df993c66c0c636e29ecbb5344252a4a&start=0&count=10
-
电影详情API:
http://api.douban.com/v2/movie/subject/${event.movieid}?apikey=0df993c66c0c636e29ecbb5344252a4a
-
- 最终解:http://api.douban.com/v2/movie/subject/1764796?apikey=0df993c66c0c636e29ecbb5344252a4a
- 豆瓣接口调用失败
-
安装
npm i request-promise-nativenpm i request
// /server/tasks/douban_api.js // http://api.douban.com/v2/movie/subject/1764796?apikey=0df993c66c0c636e29ecbb5344252a4a const rp = require('request-promise-native') // 引入发起请求的库. request-promise-native 实际上就是 request 的上层封装 async function fetchMovie (item) { const url = `http://api.douban.com/v2/movie/subject/${item.doubanID}?apikey=0df993c66c0c636e29ecbb5344252a4a` const res = await rp(url) return res } ;(async () => { let movies = [ { doubanID: 27119724, title: '小丑', rate: 8.7, poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2567198874.jpg' }, { doubanID: 26100958, title: '复仇者联盟4:终局之战', rate: 8.5, poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2552058346.jpg' } ] movies.map(async movie => { // 遍历数组 let movieData = await fetchMovie(movie) console.log(movieData) }) })()
- 执行脚本 能打印出爬出结果,即为 脚本没有错误
-
-
- 本节目标:
- 爬取 视频地址
- 爬取 视频封面图
// /server/crawler/movie.js const puppeteer = require('puppeteer') console.log('You in...') const url = 'https://movie.douban.com/subject/' const doubanID = 1652592 // const video = 'https://movie.douban.com/trailer/243269/' const sleep = time => new Promise( resolve => { setTimeout(resolve, time) }) ;(async () => { console.log('Start visit the target page...') const browser = await puppeteer.launch({ args: ['--no-sandbox'], dumpio: false }) const page = await browser.newPage() await page.goto( url + doubanID, { waitUntil: 'networkidle2' // 当网络空闲时。说明网络资源加载完毕 }) await sleep(3000) // 网络空闲时,再继续等待3秒 // 获取网页内容 const result = await page.evaluate(() => { var $ = window.$ // 由于页面中 本身加载了 jQuery,所以这里直接使用就行 var it = $('.related-pic-video') if ( it && it.length > 0 ) { // 如果这个 div 存在 var link = it.attr('href') var coverImage = it.attr('style') return { link, coverImage } } return {} }) let video if (result.link) { // 如果有视频 预告片 await page.goto(result.link, { // page.goto 页面跳转 waitUntil: 'networkidle2' }) await sleep(2000) video = await page.evaluate( () => { var $ = window.$ // 获取 jquery var it = $('source') if ( it && it.length > 0 ) { return it.attr('src') } return '' // 如果没有视频 }) } // 数据拼装 const data = { doubanID, coverImage: result.coverImage, video } browser.close() console.log(data) process.send(data) // 将结果发送出去 process.exit(0) // 退出程序 })()
// /server/tasks/trailer.js const cp = require('child_process') const { resolve } = require('path') ;(async () => { // 自动执行函数 const script = resolve(__dirname, '../crawler/movie') const child = cp.fork(script, []) // fork 可以派生出一个子进程。通过 child_process.fork 来执行我们要 跑的脚本 let invoked = false // 表示 这个脚本是否有 执行过 child.on('error', err => { if (invoked) return // 如果执行过,直接 return invoked = true console.log(err) }) child.on('exit', code => { if (invoked) return invoked = true let err = code === 0 ? null : new Error('exit code ' + code) console.log(err) }) child.on('message', data => { console.log(data) }) })()
- 执行脚本
node server/tasks/trailer.js - 打印结果
You in... Start visit the target page... { doubanID: 1652592, coverImage: 'background-image:url(https://img1.doubanio.com/img/trailer/medium/2545038147.jpg?)', video: 'http://vt1.doubanio.com/202001121811/3c584fc7b6d3bf46a64cd4c1fd90ad4a/view/movie/M/402410829.mp4' } { doubanID: 1652592, coverImage: 'background-image:url(https://img1.doubanio.com/img/trailer/medium/2545038147.jpg?)', video: 'http://vt1.doubanio.com/202001121811/3c584fc7b6d3bf46a64cd4c1fd90ad4a/view/movie/M/402410829.mp4' } null
- 本节目标:
-
- 由于这个节课 视频文件是 .exe ,下载最新 迅雷影音 双击即可播放
- 为啥要另外上传到
对象存储上?- 因为网络资源 有时候会不稳定,现在能访问,过一会就可能 无法访问了,
数据源不可靠 - 所以,我们要把它下载下来,保存在 自己可控 的地方
- 但是,由于视频什么的,文件体积非常大,保存到服务器中,又很占地方
- 所以,我们把 数据 上传到第三方的
对象存储是最合适的
- 因为网络资源 有时候会不稳定,现在能访问,过一会就可能 无法访问了,
-
- 1.我们先执行代码
/server/crawler/movie.js和/server/tasks/movies.js- 拿到 一条电影 资源数据
- 然后 我们需要把 电影的 预告片视频,图片 上传到 七牛图床 上去
let movies = [{ doubanID: 27119724, coverImage: 'background-image:url(https://img1.doubanio.com/img/trailer/medium/2567151398.jpg?)', video: 'http://vt1.doubanio.com/202001181136/1916c3c70a7f98a747790516303480e4/view/movie/M/402510982.mp4', poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2567198874.jpg' }]
- 2.配置文件
- AccessKey/SecretKey 在 个人中心 - 密钥管理 里
// /server/config/index.js module.exports = { "qiniu": { "bucket": "threeki-douban", "video": "http://video.iblack7.com/", "AK": "", // AccessKey "SK": "" // SecretKey } }
- 3.上传逻辑代码
// /server/tasks/qiniu.js // 我们需要把 电影的 预告片视频,图片 上传到 七牛图床 上去 const qiniu = require('qiniu') const nanoid = require('nanoid') // 随机ID生成器 const config = require('../config') const bucket = config.qiniu.bucket const mac = new qiniu.auth.digest.Mac(config.qiniu.AK, config.qiniu.SK) const cfg = new qiniu.conf.Config() const client = new qiniu.rs.BucketManager(mac, cfg) // 七牛上传对象 const uploadToQiniu = async (url, key) => { return new Promise((resolve, reject) => { client.fetch(url, bucket, key, (err, ret, info) => { // client.fetch 能够获取网络静态资源 if (err) { reject(err) } else { if (info.statusCode == 200) { resolve({ key }) } else { reject(info) } } }) }) } ;(async () => { let movies = [{ doubanID: 27119724, coverImage: 'https://img1.doubanio.com/img/trailer/medium/2567151398.jpg', video: 'http://vt1.doubanio.com/202001181136/1916c3c70a7f98a747790516303480e4/view/movie/M/402510982.mp4', poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2567198874.jpg' }] movies.map(async movie => { if (movie.video && !movie.key) { try { console.log('开始传 video') let videoData = await uploadToQiniu(movie.video, nanoid() + '.mp4') console.log('开始传 coverImage') let coverImageData = await uploadToQiniu(movie.coverImage, nanoid() + '.jpg') console.log('开始传 poster') let posterData = await uploadToQiniu(movie.poster, nanoid() + '.jpg') if (videoData.key) { movie.videoKey = videoData.key } if (coverImageData.key) { movie.coverImageKey = coverImageData.key } if (posterData.key) { movie.posterKey = posterData.key } console.log('正确 ', movie) } catch (err) { console.log('错误', err) } } }) })()
- 4.执行代码
node server/tasks/qiniu.js开始传 video 开始传 coverImage 开始传 poster 正确 { doubanID: 27119724, coverImage: 'https://img1.doubanio.com/img/trailer/medium/2567151398.jpg', video: 'http://vt1.doubanio.com/202001181136/1916c3c70a7f98a747790516303480e4/view/movie/M/402510982.mp4', poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2567198874.jpg', videoKey: '0EOLAFiGwePfbJmll9ORA.mp4', coverImageKey: 'tMf5ckCnv_WWHzgDg2CA3.jpg', posterKey: 'vCLNfXVkfGCV5DW9y5AI7.jpg' }
- 1.我们先执行代码
```
···············
· ·
· 进程模型 ·
· ·
···············
- 子进程模型
- 进程的9个问题
- 什么是同步异步
- 什么是异步IO
- 什么是阻塞非阻塞
- 什么是事件循环与事件驱动
- 什么是单线程
- 什么是进程
- 什么是子进程
- 怎样启动子进程
- 进程间如何通信
```
-
- 什么是IO?
- Input / Output
- 说白了,就是数据的进出
- 3个线索
- process.nextTick 优先级
- libuv 相关知识
- eventEmitter
const { readFile } = require('fs') const EventEmitter = require('events') class EE extends EventEmitter {} const yy = new EE() yy.on('event', () => { console.log('出大事了!') }) setTimeout(() => { console.log('0 毫秒后到期执行的定时器回调') }, 0) setTimeout(() => { console.log('100 毫秒后到期执行的定时器回调') }, 100) setTimeout(() => { console.log('200 毫秒后到期执行的定时器回调') }, 200) readFile('../package.json', 'utf-8', data => { console.log('完成文件 1 读取操作的回调') }) readFile('../README.md', 'utf-8', data => { console.log('完成文件 2 读取操作的回调') }) setImmediate(() => { console.log('immediate 立即回调') }) process.nextTick(() => { console.log('process.nextTick 的回调') }) Promise.resolve() .then(() => { yy.emit('event') process.nextTick(() => { console.log('process.nextTick 的第 2 次回调') }) console.log('Promise 的第 1 次回调') }) .then(() => { console.log('Promise 的第 2 次回调') })
- 什么是IO?
-
- 前言
- Node.js 采用 Google Chrome V8 作为脚本解释引擎
- 在 处理 IO 方面,采用的是 自家设计的 libuv
- libuv 是一座桥 ,它封装了 针对不同系统的 IO 操作,向上呢 对 Node.js 提供了一致的 异步非阻塞接口 和 事件循环
- 当我们讨论 事件循环 的时候,往往都和 libuv 息息相关,下面 我们来看 libuv 的代码
- 打开 libuv github 代码
- https://github.com/libuv/libuv
- 按 t 键会打开一个文件浏览器,搜索
core.c, 选择unix/core.c文件 - 看里面的 核心函数
uv_run()uv_loop_t就是事件循环结构, 每次执行uv_run的时候 都会执行事件循环迭代( iteration )迭代( iteration ),我们之前的课程 也介绍过:把一个对象 内部运行的几个状态 通过 next() 这样的语法糖 可以把 它一层层的迭代完毕- 这里 uv_run() 也是一样的
- 里面有个 while , 会依次去执行
uv__update_time() uv__run_timers() uv__run_pending() uv__run_idle() uv__run_prepare() uv__io_poll() uv__run_check() uv__run_closing_handles()
- 这8个函数 可以看作是 头尾相连 的阶段,它们串起来 就组成了
事件循环的完整过程- 所谓的循环 就是这个 while 的循环了
- 所谓的处理顺序 无非就是这几个 函数调用来 调用去
- 事件循环 (event loop) 每次跑一圈 都是经过这里面的几个阶段
- 但是 这几个函数是做什么的呢?
- https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/
- 这篇文章 非常完整的介绍了 Node.js 的事件循环模型
-
- 事件循环 就是允许 node.js 去执行一些 异步非阻塞的操作,因为 js 是单线程的,所以 这些异步操作 都交给 操作系统的内核 去做。操作系统 基本都是 多线程的,可以在后台 同时处理 多个不同的操作。
- 一旦 某个操作完成了 比如说 文件读取到了,内核 就会通知 node.js 在合适的时机 去执行一个回调函数。
- 而这个时机,就是 我们上面提到的 uv_run() 里的 8个函数
-
- 这个 8个函数 有自己的执行顺序
- 这个顺序 就是 下面这张图
- node.js 在启动的时候会
初始化事件循环 - 然后 处理在 node.js 中运行的代码,这些代码中 包含各种 api 的调用
- 然后才运行事件循环
┌───────────────────────────┐ ┌─>│ timers │ │ └─────────────┬─────────────┘ │ ┌─────────────┴─────────────┐ │ │ pending callbacks (I/O) │ │ └─────────────┬─────────────┘ │ ┌─────────────┴─────────────┐ │ │ idle, prepare │ │ └─────────────┬─────────────┘ ┌───────────────┐ │ ┌─────────────┴─────────────┐ │ incoming: │ │ │ poll │<─────┤ connections, │ │ └─────────────┬─────────────┘ │ data, etc. │ │ ┌─────────────┴─────────────┐ └───────────────┘ │ │ check │ │ └─────────────┬─────────────┘ │ ┌─────────────┴─────────────┐ └──┤ close callbacks │ └───────────────────────────┘
- 这8个函数 可以看作是 头尾相连 的阶段,它们串起来 就组成了
┌────────────────────────────────────────────────────────────────┐ ┌─────────────────────────────────┐ │ libuv | | JavaScript | │ | | ┌───────────────────────────┐ | │ ┌───────────────────────────┐ | | │ setTimeout │ | │ Run expired timers ````````┌─>│ timers │````|`|``| setInterval | | │ │ └─────────────┬─────────────┘ | | └───────────────────────────┘ | │ │ ┌─────────────┴─────────────┐ | | ┌───────────────────────────┐ | │ Run completed I/O handlers`│``│ pending I/O callbacks │````|`|``│ some finished I/O work/ │ | │ │ └─────────────┬─────────────┘ | | │ I/O Errors │ | │ │ ┌─────────────┴─────────────┐ | | └───────────────────────────┘ | │ │ │ idle handlers │ | | | │ │ └─────────────┬─────────────┘ | | | │ │ ┌─────────────┴─────────────┐ | | | │ Some prep-work before `````│``│ prepare handlers │ | | ┌───────────────┐ | │ polling for I/O │ └─────────────┬─────────────┘ | | │ incoming: │ | │ │ ┌─────────────┴─────────────┐ | | | connections, │ | │ Wait for I/O to complete ``│``│ I/O Poll │ <──|─|───────┤ data, etc. │ | │ │ └─────────────┬─────────────┘ | | └───────────────┘ | │ │ ┌─────────────┴─────────────┐ | | ┌───────────────────────────┐ | │ Some checking stuff ```````│``│ check handlers │````|`|``│ setImmediate │ | │ after polling for I/O │ └─────────────┬─────────────┘ | | └───────────────────────────┘ | │ │ ┌─────────────┴─────────────┐ | | ┌───────────────────────────┐ | │ Run any close handlers ````└──┤ close callbacks │````|`|``│ *.on('close'... handlers) │ | │ └───────────────────────────┘ | | └───────────────────────────┘ | | | | | | | | | └────────────────────────────────────────────────────────────────┘ └─────────────────────────────────┘名字解释: ↓↓↓↓ poll 轮询 run expired timers <:::> 运行过期的计时器 run completed I/O handlers <:::> 运行已完成的I/O处理程序 some prep-work before polling for I/O <:::> 在轮询I/O之前做一些准备工作 wait for I/O to complete <:::> 等待I/O完成 some checking stuff after polling for I/O <:::> 在轮询I/O之后做一些检查工作 run any close handlers <:::> 运行任何关闭的处理程序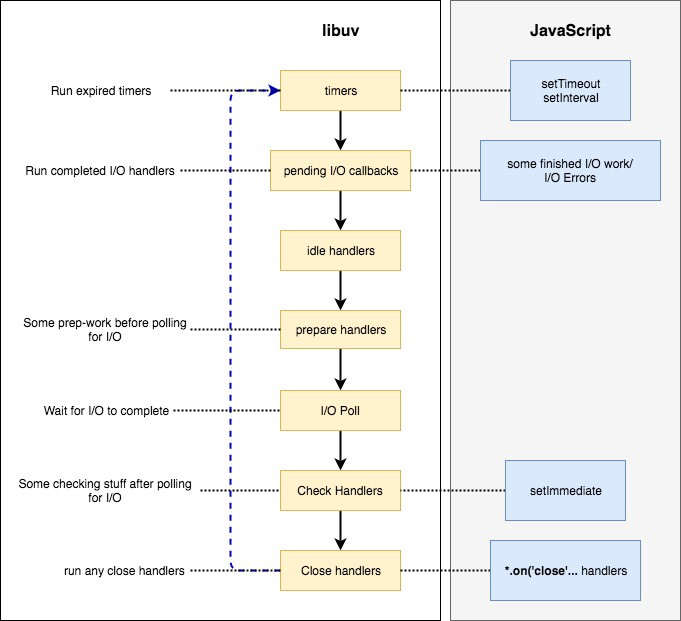 原链接 Node 定时器详解 【阮一峰】
原链接 Node 定时器详解 【阮一峰】-
它把 idle, prepare 并成了一个,而且 拿掉了 uv__update_time(), 整理成了 6个阶段
-
事件循环 6个阶段
-
setTimeout, setInterval在这个阶段被执行。这个阶段 对应的 源代码 就是uv__run_timers()
-
- 执行一些错误处理,如 socket , stream , TCP , Pipe。这个阶段 对应的 源代码 就是
uv__run_pending
- 执行一些错误处理,如 socket , stream , TCP , Pipe。这个阶段 对应的 源代码 就是
-
- 向系统去获取 新的 I/O 事件,执行对应的 I/O 回调
- 首先他会来处理 到期的定时器 的回调
- 然后处理 poll 队列中的回调
直到队列中的回调 全部被清空,或者达到处理上限
- 如果队列不为空的话,刚好有 setImmediate 那么他就会终止当前 poll 阶段,前往
check阶段 - 如果没有 setImmediate 的话,node.js 会去查看有没有 定时器任务到期了
- 如果有的话,就前往
timmer阶段来执行定时器的回调
- 如果有的话,就前往
- 向系统去获取 新的 I/O 事件,执行对应的 I/O 回调
-
- 在 check 阶段 会执行
Immediate回调,而且 setImmediate回调 只能在check阶段来执行
- 在 check 阶段 会执行
-
- 执行
on('close')这样一个结束的回调
- 执行
-
-
基本上事件循环是
按照这个模型顺序执行的,但是有的时候 会被外界事件所触发 或者 显示调用而触发 -
process.nextTick
- 是在任意两个阶段中间,只要有
process.nextTick还未被执行,那么就优先执行他的回调。 Promise.resolve()是仅次于process.nextTick优先级的
/* /src/unix/core.c */ int uv_run(uv_loop_t* loop, uv_run_mode mode) { int timeout; int r; int ran_pending; r = uv__loop_alive(loop); if (!r) uv__update_time(loop); while (r != 0 && loop->stop_flag == 0) { uv__update_time(loop); uv__run_timers(loop); ran_pending = uv__run_pending(loop); uv__run_idle(loop); uv__run_prepare(loop); timeout = 0; if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT) timeout = uv_backend_timeout(loop); uv__io_poll(loop, timeout); uv__run_check(loop); uv__run_closing_handles(loop); if (mode == UV_RUN_ONCE) { /* UV_RUN_ONCE implies forward progress: at least one callback must have * been invoked when it returns. uv__io_poll() can return without doing * I/O (meaning: no callbacks) when its timeout expires - which means we * have pending timers that satisfy the forward progress constraint. * * UV_RUN_NOWAIT makes no guarantees about progress so it's omitted from * the check. */ uv__update_time(loop); uv__run_timers(loop); } r = uv__loop_alive(loop); if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT) break; } /* The if statement lets gcc compile it to a conditional store. Avoids * dirtying a cache line. */ if (loop->stop_flag != 0) loop->stop_flag = 0; return r; }
- 是在任意两个阶段中间,只要有
-
执行顺序 解读
const { readFile } = require('fs') const EventEmitter = require('events') class EE extends EventEmitter {} const yy = new EE() yy.on('event', () => { console.log('出大事了!') }) setTimeout(() => { console.log('0 毫秒后到期执行的定时器回调') }, 0) setTimeout(() => { console.log('100 毫秒后到期执行的定时器回调') }, 100) setTimeout(() => { console.log('200 毫秒后到期执行的定时器回调') }, 200) readFile('../package.json', 'utf-8', data => { console.log('完成文件 1 读取操作的回调') }) readFile('../README.md', 'utf-8', data => { console.log('完成文件 2 读取操作的回调') }) setImmediate(() => { console.log('immediate 立即回调') }) process.nextTick(() => { console.log('process.nextTick 的回调') }) Promise.resolve() .then(() => { yy.emit('event') process.nextTick(() => { console.log('process.nextTick 的第 2 次回调') }) console.log('Promise 的第 1 次回调') }) .then(() => { console.log('Promise 的第 2 次回调') })
- 上一节的 脚本执行后,结果如下
process.nextTick 的回调 出大事了! Promise 的第 1 次回调 Promise 的第 2 次回调 process.nextTick 的第 2 次回调 0 毫秒后到期执行的定时器回调 完成文件 1 读取操作的回调 immediate 立即回调 完成文件 2 读取操作的回调 100 毫秒后到期执行的定时器回调 200 毫秒后到期执行的定时器回调- 1.首先 在第一个阶段之前,已经有了
process.nextTick, 所以会先执行process.nextTick - 2.然后就是
promise.resolve(), 它是 仅次于promise.nextTick优先级的- 在 执行
promise.resolve()的时候,遇到了 第一个.then() - 然后 按顺序执行
- 这其中,又注册了
process.nextTick(),所以,在执行完promise.resolve()后 会立刻执行下一个process.nextTick()
- 在 执行
- 3.当
process.nextTick()和promise.resolve()都执行完后,就会进入timers阶段setTimeout, setInterval都会被在这个timers阶段注册- 定时器为零的 会被立刻执行
setTimeout(() => {}, 0) - 定时器 没到期的,会被暂时搁置,直接进入下一个阶段
- 4.Poll阶段
- 前面
timers阶段走完后, 进入 Poll阶段,I/O 操作都会在这个阶段 执行 - 所以两个
readFile()会被开始执行
- 前面
- 5.当 poll队列 被清空之后,发现有
setImmediate 回调函数, 然后执行setImmediate - 6.最后在时间到了 就执行 剩下的两个 100ms 200ms 的 timers
- 前言
-
- 视频28分钟,暂时搁置 以后学深了 再回来看

-
-
mac安装 mongodb
- 课程视频时间 13:50
- Homebrew
- https://brew.sh/
- 先安装 Homebrew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"- 手动安装 Homebrew
注:Mac下/usr/local目录默认是对于Finder是隐藏,如果需要到/usr/local下去,打开Finder,然后使用command+shift+G,在弹出的目录中填写/usr/local就可以了。 Homebrew的安装建议直接在官方Git下载后手动安装: 1、下载Homebrew Git上所有文件 https://github.com/Homebrew/brew 2、把Homebrew文件夹中的文件复制到/usr/local/目录下,如果没有的文件夹请自行创建。 3、然后打开终端brew -v显示版本即安装成功。可以brew update更新一下 链接:https://www.zhihu.com/question/35928898/answer/133380744 来源:知乎 - 如果安装不了,参考 《安装homebrew报错curl: (7) Failed to connect to raw.githubusercontent.com port 443: Operation》
- Homebrew 是什么?
- macOS 缺失的软件包管理工具
brew -v 显示版本即安装成功 brew install mongodb 通过 Homebrew 安装 mongodb // 2019年 无法通过这个命令安装 mongodb brew info mongodb 查看 帮助提示 brew services start mongodb 开启 mongodb 服务 -
安装 mongodb
- 这里是 安装 mac 版本的
- https://www.mongodb.com/download-center/community
- 安装参考文章 mac安装mongodb4.2及php7.2的mongodb扩展
- 安装完成后,我们可以把 MongoDB 的二进制命令文件目录(安装目录/bin)添加到 PATH 路径中:
export PATH=/usr/local/mongodb/bin:$PATH ## 添加全局变量
brew tap mongodb/brew ## 终端添加自定义的mongodb第三方 https://github.com/mongodb/homebrew-brew brew install mongodb-community@4.2 ## 安装mongodb4.2 brew services start mongodb-community@4.2 ## 运行mongodb4.2 brew services stop mongodb-community@4.2 ## 关闭 ## 常用mongodb操作 mongod -version mongo --host 127.0.0.1:27017 ## 连接到本地数据库 > show dbs douban-trailer 0.000GB ## 查看数据库 > use douban-trailer switched to db douban-trailer ## 切换到数据库 > show tables dogs ## 查看表 > db.dogs.find() { "_id" : ObjectId("5e2002d63bc8aa43c41d15b4"), "name" : "阿尔法", "__v" : 0 } ## 查找集合中数据 db.stats() ## 统计数据信息 db.user.insert({name:”phpnote.cc”,password:”123456″}) ##指定集合写入数据
-
- mongoose 是一个 连接器,连接 mongodb 数据库 和 node.js 连接器
- 安装
npm i mongoose -
// /server/database/init.js const mongoose = require('mongoose') const DATABASE_URL = 'mongodb://localhost/douban-trailer' // 数据库地址 // const DATABASE_URL = 'mongodb://127.0.0.1:27017/' mongoose.Promise = global.Promise // 指定 Promise 是 node 原生 promise,而不是 mongoose 自带的 promise function _connect() { // console.log('you in _connect') // mongoose.connect(db, { // 连接数据库, 填入地址 // // useUnifiedTopology: true, // useNewUrlParser: true, // }) mongoose.connect(DATABASE_URL, { useNewUrlParser: true, useUnifiedTopology: true, }, (err, connection) => { if(err) { console.error(err) return } // console.log('Connected to DB'); }).catch(err => console.log(err)); } exports.connect = () => { let maxConnectTimes = 0 /* 为什么要返回 promise? * 是为了 让我们 在外面,确保连到数据库之后,继续后面 的代码 */ return new Promise((resolve, reject) => { // 暴露一个 connect 方法 if (process.env.NODE_ENV !== 'production') { // 判断是不是 生产环境 mongoose.set('debug', true) // 打印日志内容 } _connect() mongoose.connection.on('disconnected', () => { // 当断开连接时 maxConnectTimes ++ if (maxConnectTimes < 5) { _connect() } else { throw new Error('Disconnected: 数据库重连超过5次,并失败了') // console.log('Disconnected: 数据库重连超过5次,并失败了') } }) mongoose.connection.on('error', err => { maxConnectTimes ++ if (maxConnectTimes < 5) { _connect() } else { // throw new Error('Error: 数据库重连超过5次,并失败了') console.log('Error: 数据库重连超过5次,并失败了') reject(err) } }) mongoose.connection.once('open', () => { console.log('MongoDB Connected Successfully !') resolve() }) }) }
-
// /server/index.js const Koa = require('koa') const app = new Koa() const views = require('koa-views') const { resolve } = require('path') const { connect } = require('./database/init') ;(async () => { await connect() // 调用连接方法, 连接 mongodb 数据库 })() app.use(views(resolve(__dirname, './views'), { extension: 'pug' })) app.use(async (ctx, next) => { await ctx.render('index', { you: 'Luke', me: 'Scoot' }) }) app.listen(2333)
-
- 临时插入:
- 在上面 init.js 的
mongoose.connection.once('open')中写
- 在上面 init.js 的
// /server/database/init.js mongoose.connection.once('open', () => { const Dog = mongoose.model('Dog', { name: String }) const doga = new Dog({ name: '阿尔法' }) doga.save().then(() => { console.log('wang') }) console.log('MongoDB Connected Successfully !') resolve() })
- 临时插入:
-
- 概念
- 数据库驱动:mySQL, Orcale 这些关系型数据库, 针对不同的语言 都有对应的驱动实现 如 Java Ruby...
- 在 MogoDB 里面,我们使用 Mongoose 作为数据库驱动
- 在上一节,我们简单的把 连接、插入数据 的流程跑通了,但是 有些概念还是 不清楚
- 概念
MongoDB - document : 文档,相当于是 是关系型数据库的一行记录 - collection : 集合,相当于是 关系型数据的 一张表 - database : 数据库, 可以理解成 关系型数据库的 database Mongoose - schema - model - entity-
- 文档,由 键值对 组成的,是 mongoDB 的核心单元
- 相当于是 是关系型数据库的一行记录
-
- 集合,是多个文档、多行记录的集合、多部电影、多个记录、多个用户 可以组成一个集合。
- 相当于是 关系型数据的 一张表
-
- 这个比较容易理解,把 逻辑、或业务上 有关系的 collection 把它们组织在一起 就是一个数据库了。
- 这个 database 可以理解成 关系型数据库的 database ,里面可以有 电影表、用户表... 等
-
- 一个函数集合
- Mongoose 是在 MongoDB驱动 之上,继续抽象 和 封装 的 对象模型工具。
- 通过 Mongoose 可以让我们在 数据层面 和 代码层面 更容易使用,门槛比较低
-
- 数据定义
- schema 可以看作是 mongoose 中的一种数据模式,或者 数据定义
- 可以参考 mySQL 中 创建表的时候,每个字段是什么类型,长度...
-
- 数据操作模型
- 模型
- 具备 某张表 操作能力的函数集合,增删改查
-
- 某条数据的 自我修改能力
- entity 是 model 创建的实体
ducument -- 多条数据 组成 --> collection -- 多个表 组成 --> database ·············· · · · ducument · --┓ · · | ·············· | | 多条数据 组成 | ·············· | · · ←-┛ · collection · --┓ · · | ·············· | | | 多个表 组成 | ·············· | · · | · database · ←-┛ · · ··············schema -- 发布生成 --> model -- 创建 --> entity ·············· · · · schema · --┓ · · | ·············· | | 发布生成 | ·············· | · · ←-┛ · model · --┓ · · | ·············· | | | 创建 | ·············· | · · | · entity · ←-┛ · · ·············· -
- 概念
-
- 项目目录
+ |- /dist + |- /node_modules + |- /server |- index.js + |- /template + |- /views + |- /crawler + |- /database |- init.js + |- /schema // schema 里面放 所有的 模型定义文件 |- movie.js // 电影的数据模型 + |- /src |- package-lock.json |- package.json
MongDB 数据类型 String Number Array Date Buffer ObjectId // 不需要 声明,是 唯一识别符。是 mongodb 一个特有 数据类型 Mixed // 这个 Mixed 比较特殊,他比较适用于 数据类型、数据结构 变换比较频繁的场景,它可以存储 任何数据类型的数据// /server/database/schema/movie.js const mongoose = require('mongoose') // 使用 mongoose 来建模 const Schema = mongoose.Schema // 拿到建模工具 const { Mixed, ObjectID } = Schema.Types // 基于数据模型的定义 const movieSchema = new Schema({ doubanID: { unique: true, type: String }, category: [{ type: ObjectID, ref: 'Category' // 关联表 }], rate: Number, title: String, summary: String, video: String, poster: String, cover: String, // 封面图 // 由于上面的 爬取数据时 获取到的原始地址 // 下面这里 是存 你转存后的图床地址 对象存储的地址 videoKey: String, posterKey: String, coverKey: String, rawTitle: String, // 原始标题 movieTypes: [String], // 电影类型。 声明为 数组,数组内 每一个值都是 String pubdate: Mixed, // 上映日期 year: Number, // 上映年份 tags: [String], // 标签 meta: { // 描述 createdAt: { // 这条数据被 创建时间 type: Date, default: Date.now() }, updateAt: { // 更新时间 type: Date, default: Date.now() } } }) // 创建时间 更新时间 中间件的实现 movieSchema.pre('save', function(next) { // pre save 就是保存之前 if (this.isNew) { this.meta.createdAt = this.meta.updateAt = Date.now() } else { this.meta.updateAt = Date.now() } next() }) mongoose.model('Movie', movieSchema) // 传入模型名字 Movie,具体的 Schema
- 项目目录
-
- 这节 比较难 暂时跳过
- 登陆、注册、密码验证
- 对密码的 加盐 加密,密码修改有效期 的控制,密码比对的实现
- 课前基础 《node 建站攻略(二期)—— 网站升级》《node+mongodb 建站攻略 (一期)》
- 《node 建站攻略(二期)—— 网站升级》
- 第三章 开发用户的注册 登陆功能
- 用户模型 密码处理
- md5 ssha算法 词典暴力破解
- 为什么要 加密 加盐
- 用户模型 密码处理
- 第三章 开发用户的注册 登陆功能
- 《node 建站攻略(二期)—— 网站升级》
- 增加 用户登陆 网站是 被破解的难度
- 如果用户密码用 明文保存,一旦被 偷库,所有密码都将被暴露,所以这里 要用 密码加密 再保存
以下代码 没有经过测试,先写到这里,逻辑思路如此
// /server/database/schema/user.js const mongoose = require('mongoose') // 使用 mongoose 来建模 const bcrypt = require('bcrypt') // bcrypt 加密库 // 如果是比较老的版本 node ,就用 bcryptjs const Schema = mongoose.Schema // 拿到建模工具 const { Mixed, ObjectID } = Schema.Types const SALT_WORK_FACTOR = 10 const MAX_LOGIN_ATTEMPTS = 5 // 最大登陆失败次数 const LOCK_TIME = 2 * 60 * 60 * 1000 // 登陆超过最大失败次数,锁定时间 2小时 // 基于数据模型的定义 const userSchema = new Schema({ username: { unique: true, require: true, // 是否必须传 type: String }, eamil: { unique: true, require: true, // 是否必须传 type: String }, password: { // unique: true, tyep: String }, loginAttempts: { type: Number, require: true, // 是否必须传 default: 0 }, lockUntil: Number, // 如果登陆超过最大失败次数,记录 账户锁定到什么时候. 单位: ms meta: { // 描述 createdAt: { // 这条数据被 创建时间 type: Date, default: Date.now() }, updateAt: { // 更新时间 type: Date, default: Date.now() } } }) // 虚拟字段 // 虚拟字段不会被真正存到 数据库里 userSchema.virtual('isLocked').get( funciton () { // lockUntil 要被锁定到什么时候 // lockUntil > Date.now() 是否已经过了有效期 // 两次取反 拿到 true or false return !!(this.lockUntil && this.lockUntil > Date.now()) // 这里应该是 this.lockUntil < Date.now() 吧? }) // 创建时间 更新时间 中间件的实现 userSchema.pre('save', function(next) { // pre save 就是保存之前 if (this.isNew) { this.meta.createdAt = this.meta.updateAt = Date.now() } else { this.meta.updateAt = Date.now() } next() }) // 保存之前 对密码加密 userSchema.pre('save', function(next) { // pre save 就是保存之前 if (!this.isModified('password')) return next() // 检查 password 是否更改,如果没有更改了 直接跳过 // bcrypt 加密库 // SALT_WORK_FACTOR 这个值是一个产量,这个值越大 构建对盐的复杂度 越高,消耗的计算机 算力越多 bcrypt.genSalt(SALT_WORK_FACTOR, (err, salt) => { if (err) return next(err) // 如果出错了 就跳过 // 如果没错,我们拿到 盐值后, 我们通过 hash 对密码加密 bcrypt.hash(this.password, salt, (error, hash) => { if (error) return next(error) this.password = hash // 把 password 设置为 加盐加密的 hash值 // 走到这一步,这个密码已经不在是 明文的密码了 next() }) }) next() }) // 比对密码 userSchema.methods = { // 密码比对 comparePassword: (_password, password) => { // _password 是网站 提交过来的 password // 第二个 password 是 数据库中 加严加密后的 password return new Promise((resolve, reject) => { bcrypt.compare(_password, password, (err, isMatch) => { // isMatch 比较的结果是 true / false if (!err) resolve(isMatch) // 如果没有错误,把 isMatch 传出去 else reject(err) }) }) }, // 如果密码被频繁登陆,而且密码都是错的 // 就对 这个 账号进行保护,锁定账号,通过其他方式登陆,如短信验证码 // 每次密码输错 就+1 // incLoginAttepts 就是用于 判断登陆次数 是否超过 登陆次数 incLoginAttepts: (user) => { return new Promise((resolve, reject) => { // 如果用户已经被锁定 if (this.lockUntil && this.lockUntil < Date.now()) { this.update({ $set: { // 原子操作 loginAttempts: 1 // 设置为 1 }, $unset: { lockUntil: 1 // 设置为 1 } }, (err) => { if (!err) resolve(true) else reject(err) }) } else { let updates = { $inc: { // 通过 $inc 这个操作符 loginAttempts: 1 // +1 } } // 如果尝试登陆次数 大于 最大尝试次数 // 而且 当前用户没被锁定 if (this.loginAttempts + 1 >= MAX_LOGIN_ATTEMPTS && !this.isLocked) { updates.$set = { lockUntilL: Date.now() + LOCK_TIME } } this.update(updates, err => { if (!err) resolve(true) else reject(err) }) } }) } } mongoose.model('User', userSchema) // 传入模型名字 Movie,具体的 Schema
- 这样挂载到 入口文件?
// /server/index.js const Koa = require('koa' const mongoose = require('mongoose') const app = new Koa() const views = require('koa-views') const { resolve } = require('path') // const { connect, initSchemas } = require('./database/init') const { connect, initSchemas, initAdmin } = require('./database/init') ;(async () => { await connect() // 连接数据库 initSchemas() // 初始化 schema await initAdmin() // ????? // require('./tasks/movies') // 执行任务:爬取电影数据,并存到数据库 // require('./tasks/douban_api') })() app.use(views(resolve(__dirname, './views'), { extension: 'pug' })) app.use(async (ctx, next) => { await ctx.render('index', { you: 'Luke', me: 'Scoot' }) }) app.listen(2333)
-
- 本节目标
- 建立 一个电影 分类模型,让电影 和 电影分类 之间 建立一个关联关系
// /server/database/schema/category.js // 电影分类模型 const mongoose = require('mongoose') // 使用 mongoose 来建模 const Schema = mongoose.Schema // 拿到建模工具 const ObjectID = Schema.Types.ObjectID // 基于数据模型的定义 const categorySchema = new Schema({ name: { // 增加一个 name 字段 unique: true, type: String }, movies: [{ type: ObjectID, ref: 'Movie' // 建立一个 引用关系,关联关系 关联表. 这里让它关联 Movie 表 }], meta: { // 描述 createdAt: { // 这条数据被 创建时间 type: Date, default: Date.now() }, updateAt: { // 更新时间 type: Date, default: Date.now() } } }) categorySchema.pre('save', function(next) { // pre save 就是保存之前 if (this.isNew) { this.meta.createdAt = this.meta.updateAt = Date.now() } else { this.meta.updateAt = Date.now() } }) mongoose.model('Category', categorySchema) // mongoose.model 发布 model // 传入模型名字 Movie,具体的 Schema
- 在 init.js 添加的代码
// /server/database/init.js const glob = require('glob') // 允许你用*号 这种匹配符号 来写一个匹配规则 const { resolve } = require('path') exports.initSchemas = () => { // 这里吧所有的 schema 全部 require 进来就好了 // 因为每个 schema 都会发布 model: 都会自动执行 mongoose.model() // 加载所有 schema 文件 glob.sync(resolve(__dirname, './schema', '**/*.js')).forEach(require) // 拿到所有的 schema 之后,再 forEach(require) 逐个加载进来 }
- 在 index.js 添加代码
// /server/index.js const mongoose = require('mongoose') const { connect, initSchemas } = require('./database/init') ;(async () => { await connect() // 连接数据库 initSchemas() // 引入所有 数据库 schema // 数据查询 // mongoose.model() 就能拿到 这个model const Movie = mongoose.model('Movie') const movies = await Movie.find({}) console.log(movies) })()
- 完整代码
// /server/database/init.js const mongoose = require('mongoose') const DATABASE_URL = 'mongodb://localhost/douban-trailer' // 数据库地址 // const DATABASE_URL = 'mongodb://127.0.0.1:27017/' const glob = require('glob') // 允许你用*号 这种匹配符号 来写一个匹配规则 const { resolve } = require('path') mongoose.Promise = global.Promise // 指定 Promise 是 node 原生 promise,而不是 mongoose 自带的 promise function _connect() { mongoose.connect(DATABASE_URL, { useNewUrlParser: true, useUnifiedTopology: true, }, (err, connection) => { if(err) { console.error(err) return } // console.log('Connected to DB'); }).catch(err => console.log(err)); } exports.connect = () => { let maxConnectTimes = 0 /* 为什么要返回 promise? * 是为了 让我们 在外面,确保连到数据库之后,继续后面 的代码 */ return new Promise((resolve, reject) => { // 暴露一个 connect 方法 if (process.env.NODE_ENV !== 'production') { // 判断是不是 生产环境 mongoose.set('debug', true) // 打印日志内容 } _connect() mongoose.connection.on('disconnected', () => { // 当断开连接时 maxConnectTimes ++ if (maxConnectTimes < 5) { _connect() } else { throw new Error('Disconnected: 数据库重连超过5次,并失败了') // console.log('Disconnected: 数据库重连超过5次,并失败了') } }) mongoose.connection.on('error', err => { maxConnectTimes ++ if (maxConnectTimes < 5) { _connect() } else { // throw new Error('Error: 数据库重连超过5次,并失败了') console.log('Error: 数据库重连超过5次,并失败了') reject(err) } }) mongoose.connection.once('open', () => { console.log('MongoDB Connected Successfully !') resolve() }) }) } exports.initSchemas = () => { // 这里吧所有的 schema 全部 require 进来就好了 // 因为每个 schema 都会发布 model: 都会自动执行 mongoose.model() // 加载所有 schema 文件 glob.sync(resolve(__dirname, './schema', '**/*.js')).forEach(require) // 拿到所有的 schema 之后,再 forEach(require) 逐个加载进来 }
// /server/index.js const Koa = require('koa') const mongoose = require('mongoose') const app = new Koa() const views = require('koa-views') const { resolve } = require('path') const { connect, initSchemas } = require('./database/init') ;(async () => { await connect() initSchemas() // 数据查询 // mongoose.model() 就能拿到 这个model const Movie = mongoose.model('Movie') const movies = await Movie.find({}) console.log(movies) })() app.use(views(resolve(__dirname, './views'), { extension: 'pug' })) app.use(async (ctx, next) => { await ctx.render('index', { you: 'Luke', me: 'Scoot' }) }) app.listen(2333)
- 执行代码
node serverMongoDB Connected Successfully ! Mongoose: categories.ensureIndex({ name: 1 }, { unique: true, background: true }) Mongoose: movies.ensureIndex({ doubanID: 1 }, { unique: true, background: true }) Mongoose: users.ensureIndex({ username: 1 }, { unique: true, background: true }) (node:26295) DeprecationWarning: collection.ensureIndex is deprecated. Use createIndexes instead. Mongoose: movies.find({}, { projection: {} }) [] ## 这里打印了 空数组,就证明 代码没有BUG Mongoose: users.ensureIndex({ eamil: 1 }, { unique: true, background: true })
- 由于数据库中没有 数据,所以这里 打印了 空数组
- 到这里,整个流程就跑通了
- 本节目标
-
// /server/tasks/douban_api.js const rp = require('request-promise-native') // 引入发起请求的库. request-promise-native 实际上就是 request 的上层封装 const mongoose = require('mongoose') // 1.引入mongoose const Movie = mongoose.model('Movie') // 2.拿到 Movie 数据模型 const Category = mongoose.model('Category') async function fetchMovie (item) { const url = `http://api.douban.com/v2/movie/subject/${item.doubanID}?apikey=0df993c66c0c636e29ecbb5344252a4a` let res = await rp(url) try { res = JSON.parse(res) } catch(err) { console.log(err) } return res } ;(async () => { // let movies = [ // { // doubanID: 27119724, // title: '小丑', // rate: 8.7, // poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2567198874.jpg' // }, // { // doubanID: 26100958, // title: '复仇者联盟4:终局之战', // rate: 8.5, // poster: 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2552058346.jpg' // } // ] // 3.把原本写死的数据 改成 从数据库查询的数据 let movies = await Movie.find({ // 满足下面几种条件的,说明数据不完整,我们可以重新再爬取一次 // 我们通过一个 $or 或 的条件 // 满足这么几种条件的数据 都可以被拿出来 $or: [ { summary: { $exists: false } }, // 这个字段没有,刚刚被插进去,还没有被精加工的 { summary: null }, // 第二种情况是 null 的情况 { title: '' }, { year: { $exists: false } }, { summary: '' } ] }) // 拿到数据之后 // 由于豆瓣 api 每天数据请求次数有限制,所以每次测试的时候 只跑一条数据 for (let i = 0; i < movies.length; i++) { // for (let i = 0; i < [movies[0]].length; i++) { // 这一句代码 等价于 下面一句 // for (let i = 0; i < 1; i++) { let movie = movies[i] let movieData = await fetchMovie(movie) // 请求数据 if (movieData) { // 如果成功拿到 数据 movie.tags = movieData.tags || [] movie.summary = movieData.summary || '' movie.title = movieData.title || '' movie.original_title = movieData.original_title || [] // 原始标题 movie.movieTypes = movieData.genres || [] // genres 电影类型 movie.year = movieData.year || '未知上映年份' // 对于 movieTypes 当一个电影类目创建之后,我们要把这个 ref 也指向这个 category for (let i = 0; i < movie.movieTypes.length; i++) { let item = movie.movieTypes[i] let cat = await Category.findOne({ // 查询 电影分类数据库里 有没有这个电影 name: item }) // 如果不存在 这个电影分类 if (!cat) { cat = new Category({ name: item, // 将该分类存入 movies: [movie._id] // 并将该 电影id 存入 }) } else { // 如果这个 电影分类 存在,我们再来判断一下 是否保存过 这部电影的id if (cat.movies.indexOf(movie._id) === -1) { cat.movie.push(movie._id) // 如果不存在,则保存 } } // await cat.save() // 保存数据 // 这里如果取消注释,不知道为什么 程序好像就被卡住了 不动了 // 然后再检查 movie.category if (!movie.category) { movie.category.push(cat._id) // 如果为空,就将其 电影id 保存进去 } else { // 如果不为空,我们就 就来检查一下,看看有没有 存过 当前的 category if (movie.category.indexOf(cat._id) === -1) { // 如果没有 movie.category.push(cat._id) } // 如果有的话,就不做任何处理 } } // movie.movieTypes.forEach(async item => { // }) // 以下是上映日期的处理 let dates = movieData.pubdates || [] // 拿到电影的上映日期 let pubdates = [] // 声明上映日期 dates.map(item => { if (item && item.split('(').length > 0) { let parts = item.split('(') let date = parts[0] let country = '未知' if (parts[1]) { country = parts[1].split(')')[0] } pubdates.push({ date: new Date(date), country }) } }) movie.pubdate = pubdates } // console.log(typeof movie, movie) await movie.save() } })()
-
- 安装
npm i koa-router - 1.Router 规则
// /server/routes/index.js const Router = require('koa-router') const mongoose = require('mongoose') const router = new Router() router.get('/movies/all', async (ctx, next) => { const Movie = mongoose.model('Movie') const movies = await Movie.find({}).sort({ // 拿到电影数据, 然后根据 创建时间 从最新到最旧 排序 'meta.createdAt': -1 }) // 排序之后的 movies 就把他挂到 ctx.body 进行返回 ctx.body = { movies } }) // 电影详情 router.get('/movies/detail/:id', async (ctx, next) => { const Movie = mongoose.model('Movie') const id = ctx.params.id const movie = await Movie.findOne({_id: id}) // 把拿到的数据结果, 挂载到 ctx.body 进行返回 ctx.body = { movie } }) module.exports = router
- 2.把 Router 规则 挂载到 入口文件
/server/index.js里// /server/index.js const Koa = require('koa') const mongoose = require('mongoose') const app = new Koa() const views = require('koa-views') const { resolve } = require('path') const { connect, initSchemas } = require('./database/init') const router = require('./routes') ;(async () => { await connect() // 连接数据库 initSchemas() // 初始化 schema // require('./tasks/movies') // 执行任务:爬取电影数据,并存到数据库 // require('./tasks/douban_api') })() // 挂载路由 app .use(router.routes()) .use(router.allowedMethods()) // 允许基本方法 app.use(views(resolve(__dirname, './views'), { extension: 'pug' })) app.use(async (ctx, next) => { await ctx.render('index', { you: 'Luke', me: 'Scoot' }) }) app.listen(2333)
- 3.测试验证
node server启动服务器- 所有电影 路由
http://localhost:2333/movies/all
- 详情页 路由
http://localhost:2333/movies/detail/5e2155d2e421626cef6fbaa4
- 安装
-
-
我们还可以通过
ctx.path === '/movies也能获取 并 判断 他的请求路径- 然后根据不同的路径,分配不同的 处理逻辑
- 但是,当路径规则变复杂之后,尤其是 要求判断是什么样的请求方法时,
代码就变得不太好维护了 - 所以,最好的方法 还是用 第三方路由库,例如
koa-router
-
在上一节代码中
- 我们在
routes/index.js里写了两个 路由规则 - 但是,在我们的项目中 如果有 三四十个 路由规则的话,如果我们都写在一个文件里,就会变得比较难以维护了
- 我们可以吧 文件拆开,利用 koa-router 生成多个
router实例,然后通过多个 router实例 来分配不同的 控制器 - 但是这样做 又会引发第三个问题,
- 如果这个请求 进来之后呢,我能够对这个 进来的参数 做一些处理、cookie 做一些认证、返回数据之前 对数据做一些加工,在 控制器 之前再加一些中间件,在这个 中间件 里做一些处理。加的这个中间件 koa-router 是支持的
- 那就算 是 koa-router 支持加这些中间件,如果是在 不同的 文件里面,以不同的
router实例进行分配的话,文件数 多了之后 依然会比较麻烦
- 我们可以吧 文件拆开,利用 koa-router 生成多个
- 我们在
-
koa-router 的基本用法
- 1.支持 连起来写
router.get().post()router .get('/movies/all', async (ctx, next) => { // 处理逻辑 }) .post()
- 2.可以带参数
router.get('/movies/all?abc=123', async (ctx, next) => { // 处理逻辑 })
- 3.多个路由 命中同一个 处理逻辑
router.get('/movies/all?abc=123', async (ctx, next) => { router.get('/movies/all?abc=456', async (ctx, next) => { // 处理逻辑 })
- 4.路由 参数
router.get('/movie/:id', async (ctx, next) => { const id = ctx.params.id // 通过 ctx.params 获取路由参数 })
- 5.多个 路由参数
router.get('/movie/:id/comments/:cid', async (ctx, next) => { const id = ctx.params.id // 通过 ctx.params 获取路由参数 const id = ctx.params.cid // 通过 ctx.params 获取路由参数 })
- 6.多个中间件
-
经过多个中间件的处理,我们在后面的中间件中,就能拿到前面 处理的结果
-
语法
router.get('/movies', (ctx, next)=>{}, (ctx, next)=>{} ) // 里面可以写多个中间件`
-
示例
router.get('/movies/all', async (ctx, next) => { // 在这个中间件里,我们先查询 电影的类别 const cats = await Category.find({}) ctx.body = cats return next() // 处理完后,往下调用 next() }, async (ctx, next) => { const Movie = mongoose.model('Movie') const movies = await Movie.find({}).sort({ // 拿到电影数据, 然后根据 创建时间 从最新到最旧 排序 'meta.createdAt': -1 }) // 排序之后的 movies 就把他挂到 ctx.body 进行返回 ctx.body = { movies } })
6:00
-
- 1.支持 连起来写
-