
Modern large scale machine learning applications require stochastic optimization algorithms to be implemented with distributed computational architectures. A key bottleneck is the communication overhead for exchanging information, such as stochastic gradients, among different nodes. Recently, gradient sparsification techniques have been proposed to reduce communications cost and thus alleviate the network overhead. However, most of gradient sparsification techniques consider only synchronous parallelism and cannot be applied in asynchronous distributed training.
In this project, we present a dual-way gradient sparsification approach (DGS) that is suitable for asynchronous distributed training.
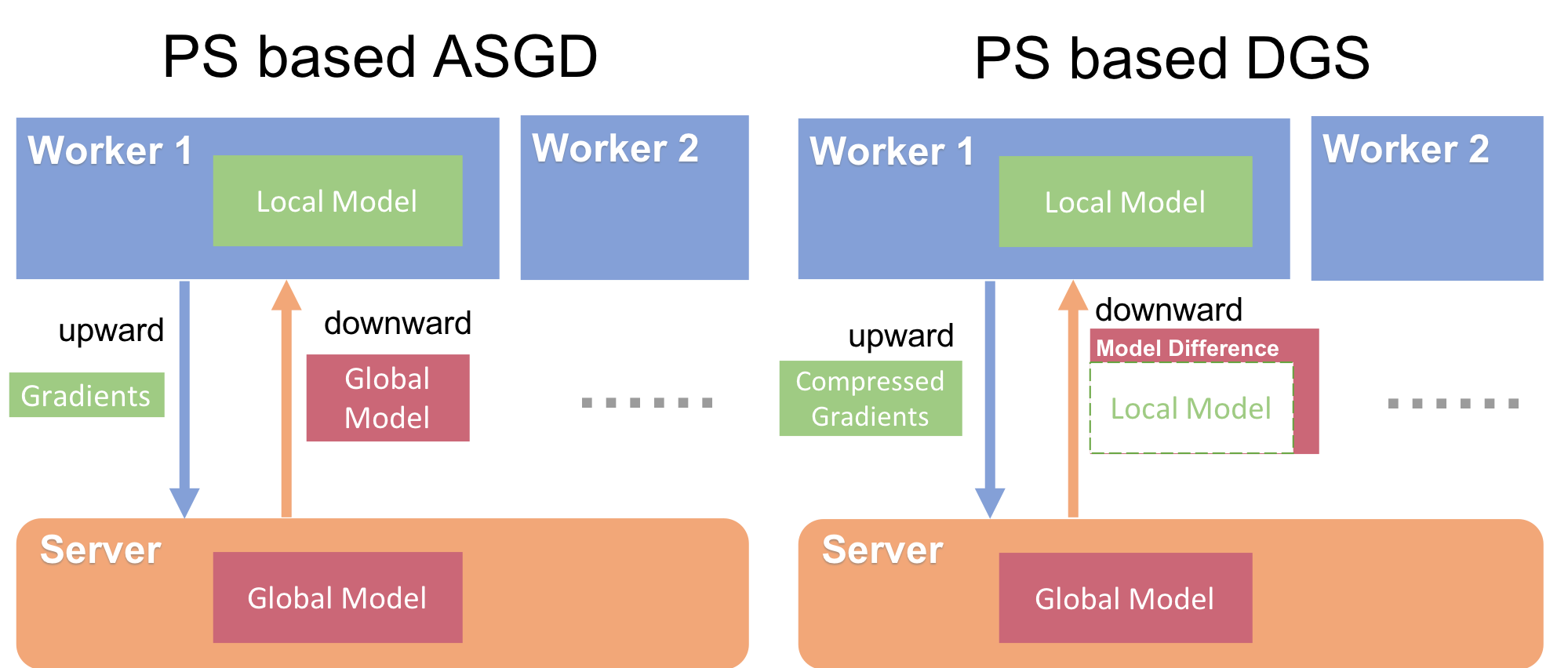
We implemented a async parameter server based on PyTorch gloo backend. Our optimizer implemented 5 training methonds: DGS, ASGD, GradientDropping, DeepGradientCompression, single node momentum SGD.
- Async parameter server on PyTorch
- Support gradient sparsification, e.g. gradient dropping [1].
- Sparse communication.
- GPU training.
- DALI dataloader for imagenet.
- Two distributed example script: cifar10 and ImageNet.
Experiments with different scales on ImageNet and CIFAR-10 show that:
(1) compared with ASGD, Gradient Dropping and Deep Gradient Compression, DGS with SAMomentum consistently achieves better performance;
(2) DGS improves the scalability of asynchronous training, especially with limited networking infrastructure.
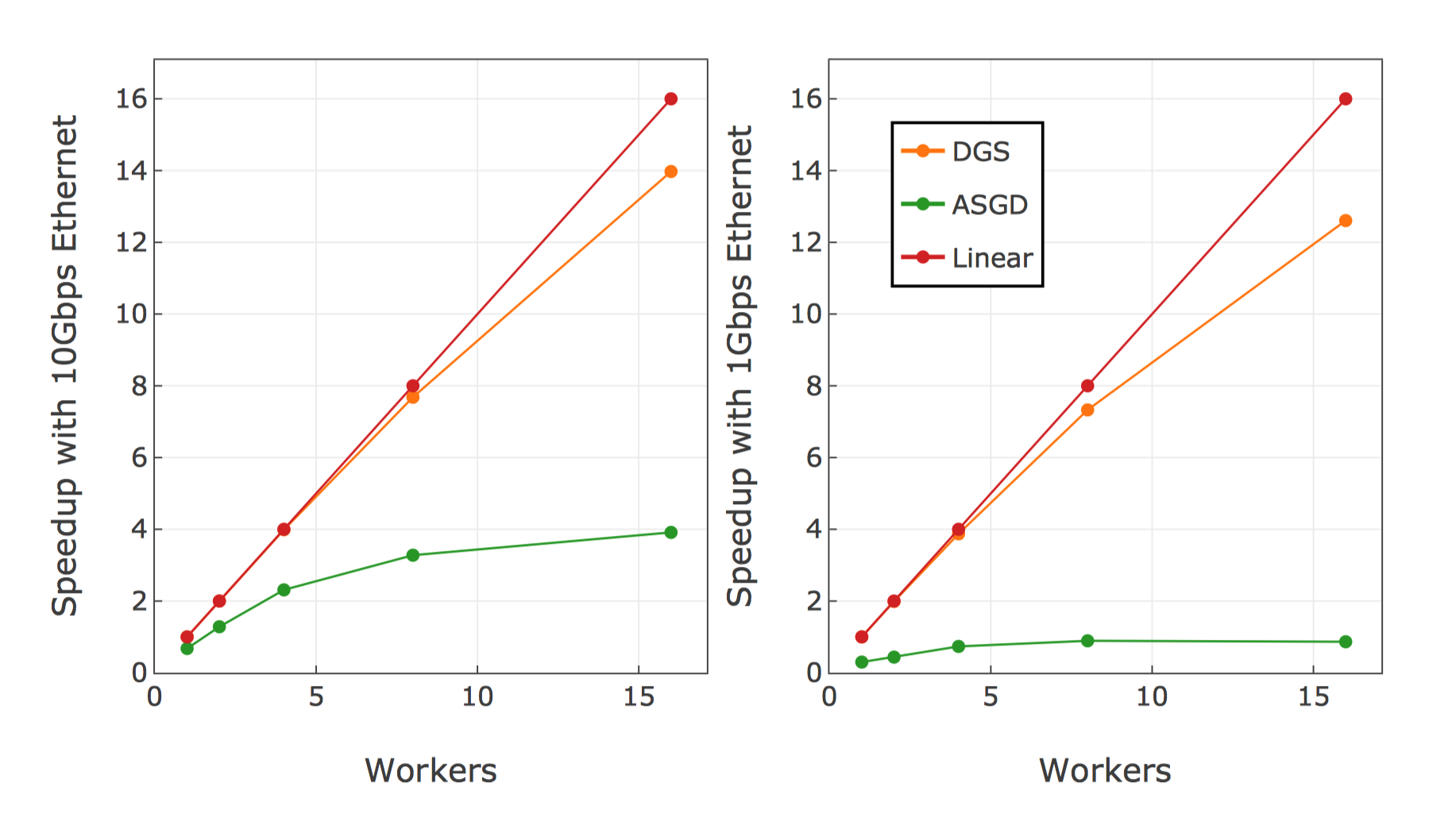
Figure above shows the training speedup with different network bandwidth values.
As the number of workers increases, the acceleration of ASGD decreases to nearly zero due to the bottleneck of communication. In contrast, DGS achieves nearly linear speedup with 10Gbps. With 1Gbps network, ASGD only achieves
# environ setup
git clone https://github.com/yanring/GradientServer.git
cd GradientServer
pip install -r requirements.txt
# distributed cifar-10 example
# On the server (rank 0 is the server)
python example/cifar10.py --world-size 3 --rank 0 --cuda
# On the worker 1
python example/cifar10.py --world-size 3 --rank 1 --cuda
# On the worker 2
python example/cifar10.py --world-size 3 --rank 2 --cuda
First, you should start a server.
init_server(args, net)
Second, replace your torch.optimizer.sgd with GradientSGD.
optimizer = GradientSGD(net.parameters(), lr=args.lr, model=net, momentum=args.momentum,weight_decay=args.weight_decay,args=args)
TODO
Zijie Yan, Danyang Xiao, Mengqiang Chen, Jieying Zhou, Weigang Wu: Dual-Way Gradient Sparsification for Asynchronous Distributed Deep Learning. ICPP 2020: 49:1-49:10
[1] Alham Fikri Aji and Kenneth Heafield, ‘Sparse communication for distributed gradient descent’, arXiv preprint arXiv:1704.05021, (2017). [2] Jesse Cai and Rohan Varma, Implementation of Google's DistBelief paper. https://github.com/ucla-labx/distbelief