A predictive model that predicts the behavior of stocks of Dow Jones Index for a particular day given the historic data upto previous day. This model also leverages the power of Sentiment Analysis applied on Top News Headlines for each day to derive public sentiment- Positive, Negative or Neutral.
The model is built in an Anaconda Environment (Spyder) and Python 3.5.0. All the libraries which need to be downloaded are mentioned in requirements.txt.
The project makes use of 4 csv files namely:
-
data_old.csv - contains Top 25 news headlines for the days, stock exchange was operating in the year (2008-2016) along with actual sentiment of the day, downloaded from here
-
dji.csv - Stock data of DJI containing 7 base variables for the year (2008-2016) downloaded from Yahoo Finance website
-
combinednew.csv - Reddit website is crawled from here using psaw API to get news headlines which are then merged together to form a single agglomeration of news headlines for the year (2017-2019)
-
livestockdata.csv - Stock data of DJI containing 7 base variables for the year (2016-2019) downloaded from Yahoo Finance website
- Install Python3 or above using Anaconda or any other method
- Install the requirements using pip install -r requirements.txt in Anaconda Prompt
- Clone this repo to your local machine
- Extract the zip file you downloaded
- Open a Python editor like Spyder
- You may create and use a virtual environment to work on this project
- Set the working directory to the folder where you extracted the files
- Since the whole project is divided into 3 files, you need to set the path for all the files in order to execute them simultaneously
- In Spyder, Go to Tools-> PYTHONPATH manager-> Add PATH-> Browse to the folder containing python files
- Execute sentiment.py
- Execute regression.py
- Execute validate.py
- validate.py contains logic to extract news data from Reddit and create csv files corresponding to everyday news headlines. Total of 1094 csv files will be generated in the working directory. You can either merge all the csv files into one and use it or you can directly use the csv file provided in the dataset named as "combinednew.csv"
The pipeline followed in the project is as follows:
- Data Collection : Data extracted from the sources mentioned above in dataset headline
- Natural Language Processing on news headlines
- Data Processing
- Bag of Words Model
- TF-IDF Vectorization
- Classification Algorithm implementation
- Data Pre-Processing & EDA on Stock Data
- Creation of Derived variables & Data Visualization
- Feature Selection & Feature Engineering
- Regression Model Building
- Model validation
Many economic indices were studied from Federal Reserve Economic Data(FRED) and Moody's Analytics and their trends were assessed for stability across years. The data for these indices are publically released by US Government. The frequency of the published indices vary weekly, monthly, quarterly and yearly. Given below is the list of all the 37 derived variables used in the project and each one of the economic index can be better understood by searching for the tag given in brackets from here
-
Quarterly : Gross Domestic Product(GDP), Median Sales Price of Houses Sold (MSPUS)
-
Monthly : Federal Funds Rate(FEDFUNDS), Consumer Price Index (CPILFESL), Producer Price Index (PPI), Unemployment Rate (UNRATE), Current Employee Statistics (PAYEMS), Advanced Retail Sales(RSXFS), Industrial Production (INDPRO), UMich Consumer Sentiment (UMCSENT), Leading economic Index (USSLIND), One Family Houses Sold (HSN1F), Housing Starts (HOUST), Total Business Inventories (BUSINV), Total Business Sales (TOTBUSSMSA), Advanced Retail Sales (RSAFS),
-
Yearly : Inflation Rate (FPCPITOTLZGUSA)
-
Weekly : M2 Money stock (M2)
-
Other derived variables : daily returns, Cumulative daily returns, volatility, date related derived features
-
37 new variables were created that contributed to the model performance
-
XG Boost predicted sentiments with 85.6% accuracy
-
Multiple Linear Regression with Backward Elimination resulted in 11 most important columns
-
Model verified on 2017-2019 data led to 0.83 R2 score
-
Model results on a random data point is given below
-
Model prediction:

-
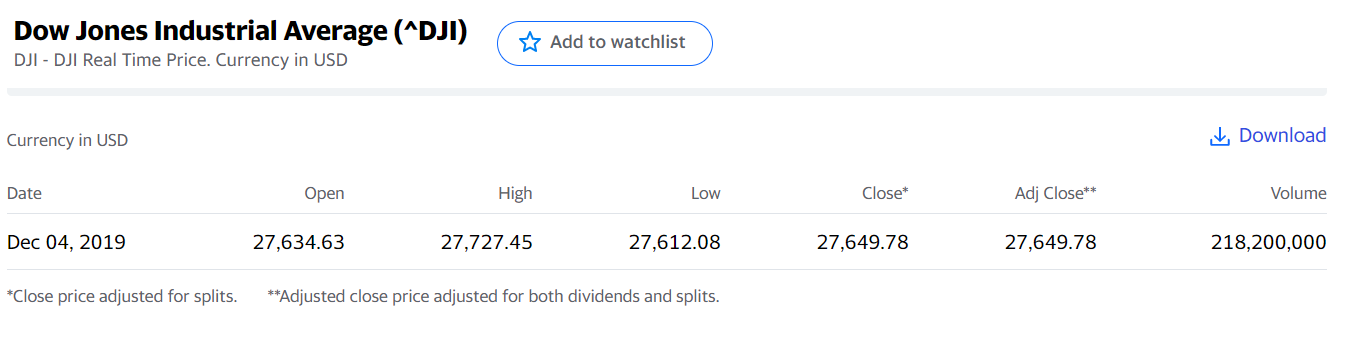
Actual Closing price on 2019-12-04: