Link to notebook: https://github.com/yashk2000/LearningPyTorch/blob/main/PyTorchPretrained.ipynb
- A pretrained network is a model that has already been trained on a dataset.
- Such networks produce useful results immediately after loading the network parameters.
- Put the network into eval mode for the dropout and batch normalization layers to work properly before making inferences.
- Generative adversarial networks (GANs) have two parts—the generator and the discriminator—that work together to produce output indistinguishable from authentic items.
- CycleGAN uses an architecture that supports converting back and forth between two different classes of images.
- Torch Hub is a standardized way to load models and weights from any project with an appropriate hubconf.py file.
Link to notebook: https://github.com/yashk2000/LearningPyTorch/blob/main/Tensors.ipynb
- Neural networks transform floating-point representations into other floating-point representations. The starting and ending representations are typically human interpretable, but the intermediate representations are less so. These floating-point representations are stored in tensors.
- Tensors are multidimensional arrays; they are the basic data structure in PyTorch
- Tensors can be serialized to disk and loaded back.
- All tensor operations in PyTorch can execute on the CPU as well as on the GPU(
tensor.to(device="cuda")). - PyTorch uses a trailing underscore to indicate that a function operates in place on a tensor (for example, Tensor.sqrt_ ).
Link to notebook: https://github.com/yashk2000/LearningPyTorch/blob/main/Datasets.ipynb
- Neural networks require data to be represented as multidimensional numerical tensors, often 32-bit floating-point.
- Images can have one or many channels. The most common are the red-green-blue channels of typical digital photos. Many images have a per-channel bit depth of 8, though 12 and 16 bits per channel are not uncommon. These bit depths can all be stored in a 32-bit floating-point number without loss of precision.
- Single-channel data formats sometimes omit an explicit channel dimension.
- Volumetric data is similar to 2D image data, with the exception of adding a third dimension (depth).
- Converting spreadsheets to tensors can be very straightforward. Categorical and ordinal-valued columns should be handled differently from interval-valued columns.
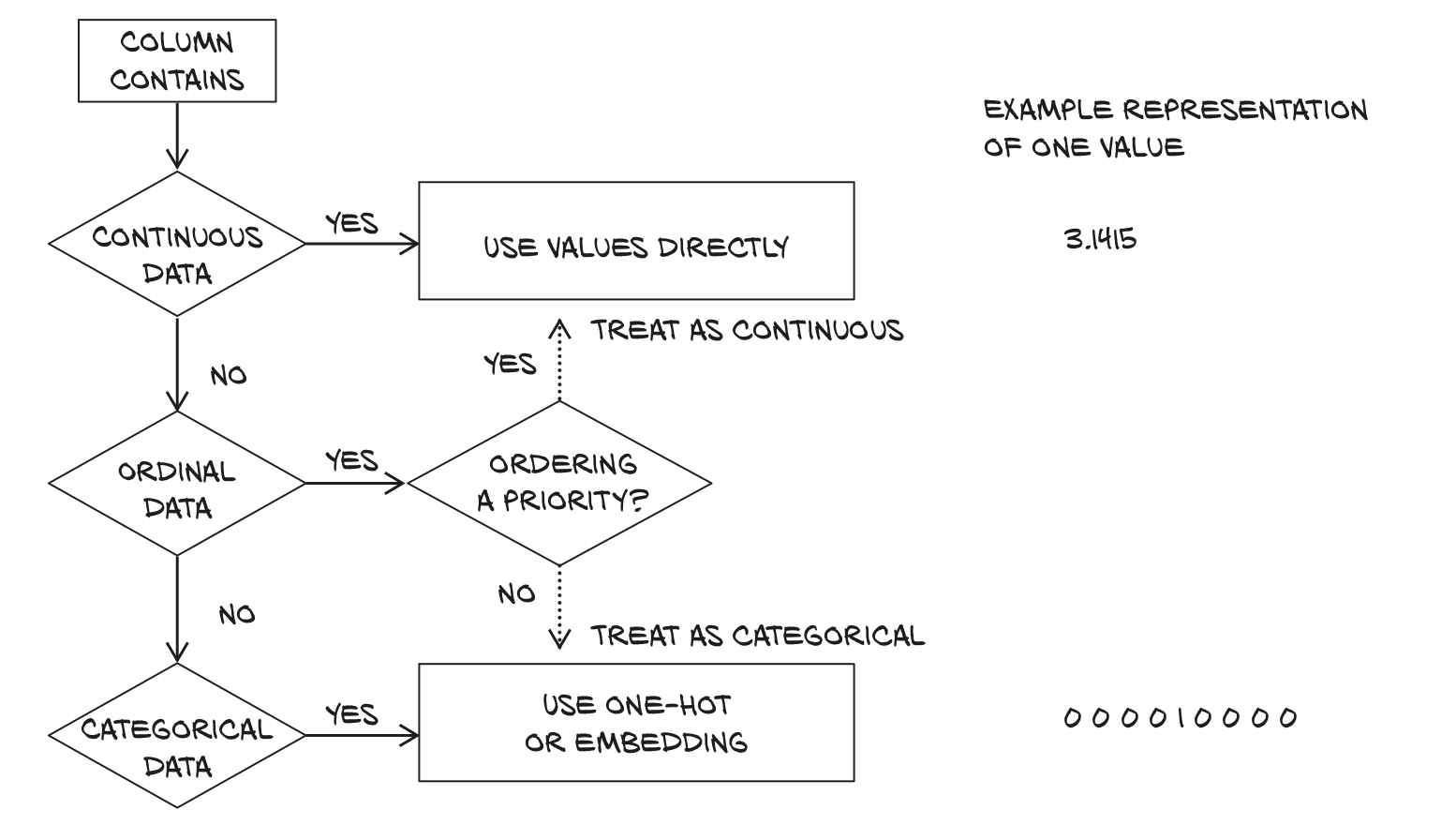 |
|---|
| Deciding between using values directly, one hot encoding or embedding |
Link to notebook: https://github.com/yashk2000/LearningPyTorch/blob/main/StuffLikeAutograd.ipynb
- Linear models are the simplest reasonable model to use to fit data.
- Convex optimization techniques can be used for linear models, but they do not generalize to neural networks, so we focus on stochastic gradient descent for parameter estimation.
- Deep learning can be used for generic models that are not engineered for solving a specific task, but instead can be automatically adapted to specialize them- selves on the problem at hand.
- Learning algorithms amount to optimizing parameters of models based on observations. A loss function is a measure of the error in carrying out a task, such as the error between predicted outputs and measured values. The goal is to get the loss function as low as possible.
- The rate of change of the loss function with respect to the model parameters can be used to update the same parameters in the direction of decreasing loss.
- The optim module provides a collection of ready-to-use optimizers for updating parameters and minimizing loss functions.
- Optimizers use the autograd feature of PyTorch to compute the gradient for each parameter, depending on how that parameter contributes to the final out- put. This allows users to rely on the dynamic computation graph during complex forward passes.
- Context managers like with
torch.no_grad(): can be used to control autograd’s behavior. - The grads are accumulated on top of each other. Therefore whenever we call grad again, it will calculate the loss, and accumulate the gradient on top of the existing one, giving a wrong value. Hence we need to manually set the grad to 0 at each iteration.
- We do not need to accumulate the gradients on the validaiton data set since we're not training models on it. In order to do this, we can use
torch.no_grad()ortorch.set_grad_enabled()
Link to notebook: https://github.com/yashk2000/LearningPyTorch/blob/main/NeuralNetworks.ipynb
- Neural networks can be automatically adapted to specialize themselves on the problem at hand.
- Neural networks allow easy access to the analytical derivatives of the loss with respect to any parameter in the model, which makes evolving the parameters very efficient.
- Activation functions around linear transformations make neural networks capable of approximating highly nonlinear functions, at the same time keeping them simple enough to optimize.
- The nn module together with the tensor standard library provide all the building blocks for creating neural networks.
- To recognize overfitting, it’s essential to maintain the training set of data points separate from the validation set. There’s no one recipe to combat overfitting, but getting more data, or more variability in the data, and resorting to simpler models are good starts.
Link to notebook: https://github.com/yashk2000/LearningPyTorch/blob/main/NeuralNetworks.ipynb
- Use
ToTensor()to convert images into tensors before feeding them to a network - Find the mean and standard deviation of an image and then normalize the image.
imgs.view(3, -1).mean(dim=1)
imgs.view(3, -1).std(dim=1)
transforms.Normalize((0.4915, 0.4823, 0.4468), (0.2470, 0.2435, 0.2616))- Use
DataLoaderto make batches from the input data.
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,
shuffle=True)- For a classification task, using the softmax function on the output of a network produces values that satisfy the requirements for being interpreted as probabilities. The ideal loss function for classification in this case is obtained by using the output of softmax as the input of a non-negative log likelihood function. The combination of softmax and such loss is called cross entropy in PyTorch.