This repo is the official Tensorflow code implementation of our paper Fast Gradient Non-sign Methods.
In our paper, we give a theoretical analysis of the side-effect of 'sign' which is adopted in current methods, and further give a correction to 'sign' as well as propose the methods FGNM.
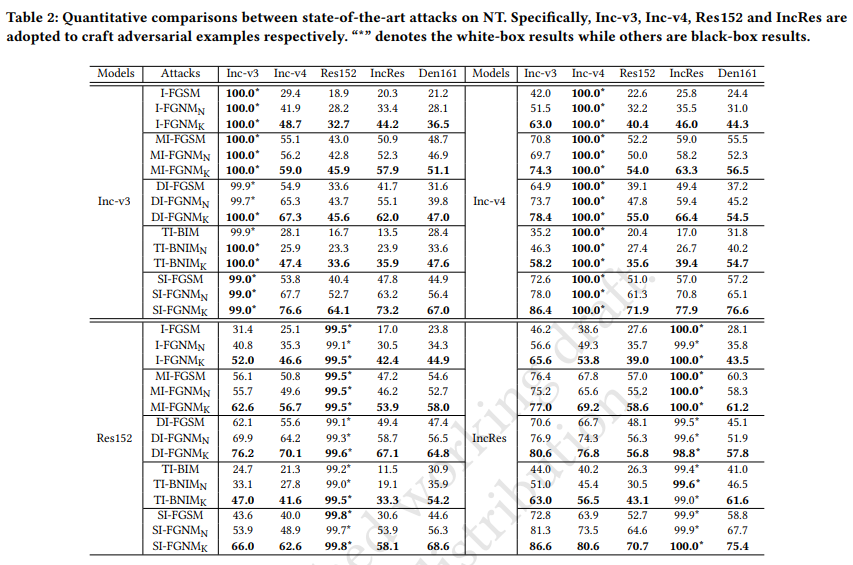
Adversarial attacks make their success in “fooling” DNNs and among them, gradient-based algorithms become one of the main streams. Based on the linearity hypothesis [12], under ℓ∞ constraint, 𝑠𝑖𝑔𝑛 operation applied to the gradients is a good choice for generating perturbations. However, the side-effect from such operation exists since it leads to the bias of direction between the real gradients and the perturbations. In other words, current methods contain a gap between real gradients and actual noises, which leads to biased and inefficient attacks. Therefore in this paper, based on the Taylor expansion, the bias is analyzed theoretically and the correction of sign, i.e., Fast Gradient Non-sign Method (FGNM), is further proposed. Notably, FGNM is a general routine, which can seamlessly replace the conventional 𝑠𝑖𝑔𝑛 operation in gradient-based attacks with negligible extra computational cost. Extensive experiments demonstrate the effectiveness of our methods. Specifically, ours outperform them by 27.5% at most and 9.5% on average.

-
Download the models
- Normlly trained models (DenseNet can be found in here)
- Ensemble adversarial trained models
-
Then put these models into ".models/"
-
Run IFGNM_N:
python attack.py --method if --mode affine
If you find this work is useful in your research, please consider citing:
@article{cheng2021fast,
title={Fast Gradient Non-sign Methods},
author={Cheng, Yaya and Zhu, Xiaosu and Zhang, Qilong and Gao, Lianli and Song, Jingkuan},
journal={arXiv preprint arXiv:2110.12734},
year={2021}
}