





Join us on
A package to generate synthetic tabular and time-series data leveraging the state of the art generative models.
These are must try features when it comes to synthetic data generation:
- A new streamlit app that delivers the synthetic data generation experience with a UI interface. A low code experience for the quick generation of synthetic data
- A new fast synthetic data generation model based on Gaussian Mixture. So you can quickstart in the world of synthetic data generation without the need for a GPU.
- A conditional architecture for tabular data: CTGAN, which will make the process of synthetic data generation easier and with higher quality!
Synthetic data is artificially generated data that is not collected from real world events. It replicates the statistical components of real data without containing any identifiable information, ensuring individuals' privacy.
Synthetic data can be used for many applications:
- Privacy compliance for data-sharing and Machine Learning development
- Remove bias
- Balance datasets
- Augment datasets
Looking for an end-to-end solution to Synthetic Data Generation?
YData Fabric enables the generation of high-quality datasets within a full UI experience, from data preparation to synthetic data generation and evaluation.
Check out the Community Version.
This repository contains material related with architectures and models for synthetic data, from Generative Adversarial Networks (GANs) to Gaussian Mixtures. The repo includes a full ecosystem for synthetic data generation, that includes different models for the generation of synthetic structure data and time-series. All the Deep Learning models are implemented leveraging Tensorflow 2.0. Several example Jupyter Notebooks and Python scripts are included, to show how to use the different architectures.
Are you ready to learn more about synthetic data and the bext-practices for synthetic data generation?
The source code is currently hosted on GitHub at: https://github.com/ydataai/ydata-synthetic
Binary installers for the latest released version are available at the Python Package Index (PyPI).
pip install ydata-synthetic
YData synthetic has now a UI interface to guide you through the steps and inputs to generate structure tabular data. The streamlit app is available form v1.0.0 onwards, and supports the following flows:
- Train a synthesizer model
- Generate & profile synthetic data samples
pip install ydata-synthetic[streamlit]
Use the code snippet below in a python file (Jupyter Notebooks are not supported):
from ydata_synthetic import streamlit_app
streamlit_app.run()Or use the file streamlit_app.py that can be found in the examples folder.
python -m streamlit_app
The below models are supported:
- CGAN
- WGAN
- WGANGP
- DRAGAN
- CRAMER
- CTGAN
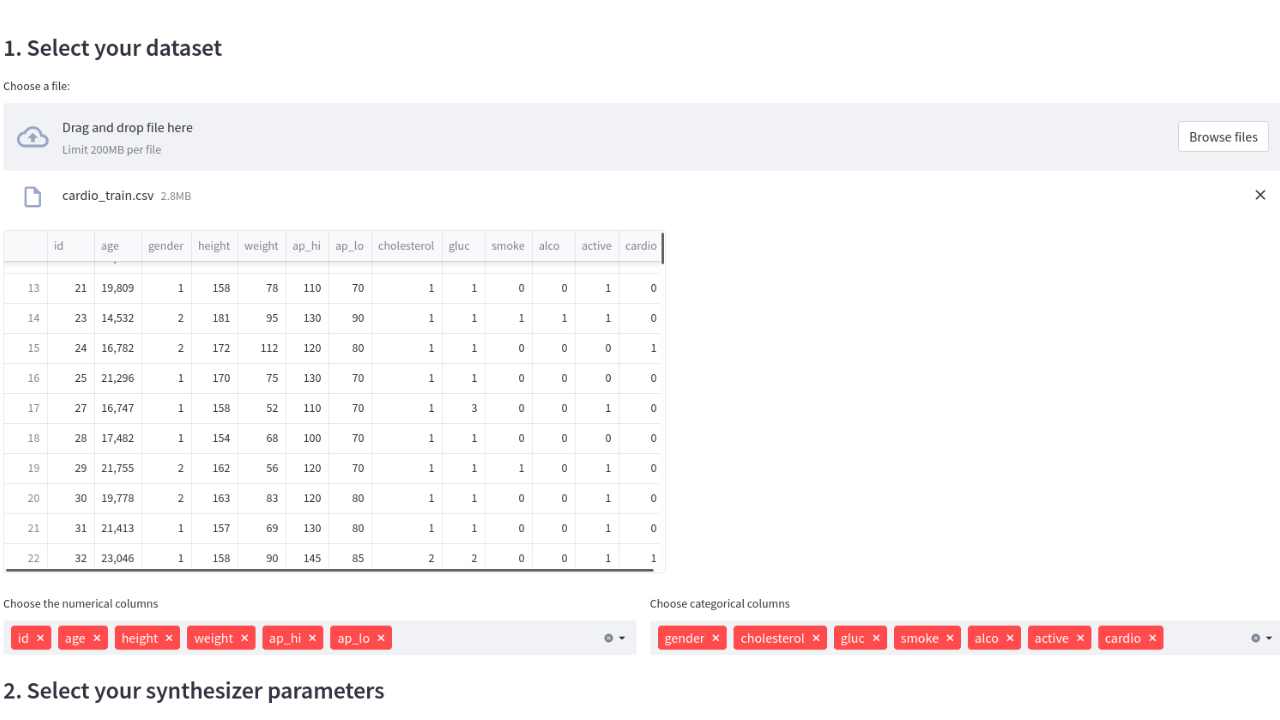
Here you can find usage examples of the package and models to synthesize tabular data.
- Fast tabular data synthesis on adult census income dataset
- Tabular synthetic data generation with CTGAN on adult census income dataset
- Time Series synthetic data generation with TimeGAN on stock dataset
- Time Series synthetic data generation with DoppelGANger on FCC MBA dataset
- More examples are continuously added and can be found in
/examplesdirectory.
Here are some example datasets for you to try with the synthesizers:
In this repository you can find the several GAN architectures that are used to create synthesizers:
- GAN
- CGAN (Conditional GAN)
- WGAN (Wasserstein GAN)
- WGAN-GP (Wassertein GAN with Gradient Penalty)
- DRAGAN (On Convergence and stability of GANS)
- Cramer GAN (The Cramer Distance as a Solution to Biased Wasserstein Gradients)
- CWGAN-GP (Conditional Wassertein GAN with Gradient Penalty)
- CTGAN (Conditional Tabular GAN)
- Gaussian Mixture
We are open to collaboration! If you want to start contributing you only need to:
- Search for an issue in which you would like to work. Issues for newcomers are labeled with good first issue.
- Create a PR solving the issue.
- We would review every PRs and either accept or ask for revisions.
For support in using this library, please join our Discord server. Our Discord community is very friendly and great about quickly answering questions about the use and development of the library. Click here to join our Discord community!
Have a question? Check out the Frequently Asked Questions about ydata-synthetic. If you feel something is missing, feel free to book a beary informal chat with us.