- 网络整体:x_net.py
- 特征融合网络层:x_net_fusion_layers.py
- 网络配置文件:xnet
使用pycharm的SSH连接docker,不如设置pycharm的编译器为docker中的python。这样做的优势有三:
- 不需要通过ssh传输图像,pycharm的运行速度更快。
- 因为docker同步了工作目录,不需要使用pycharm来同步,节省时间。
- 不需要重新弄配置pycharm。
需要修改的有两个位置,一个是configs中的配置文件,一个是mmdet3d中的models相关文件。参照官方教程:教程 1: 学习配置文件和教程 4: 自定义模型
整个框架的思路是从配置文件中去找对应的模型,程序会在一开始把模型全部注册到一个位置,然后使用配置文件中的type关键字去搜索,然后使用其他的作为参数输入,具体需要什么参数由模型决定。
阅读代码的时候发现,框架对自编码器有一定的支持,这一点在完成主干网络的构建后深入调查一下。
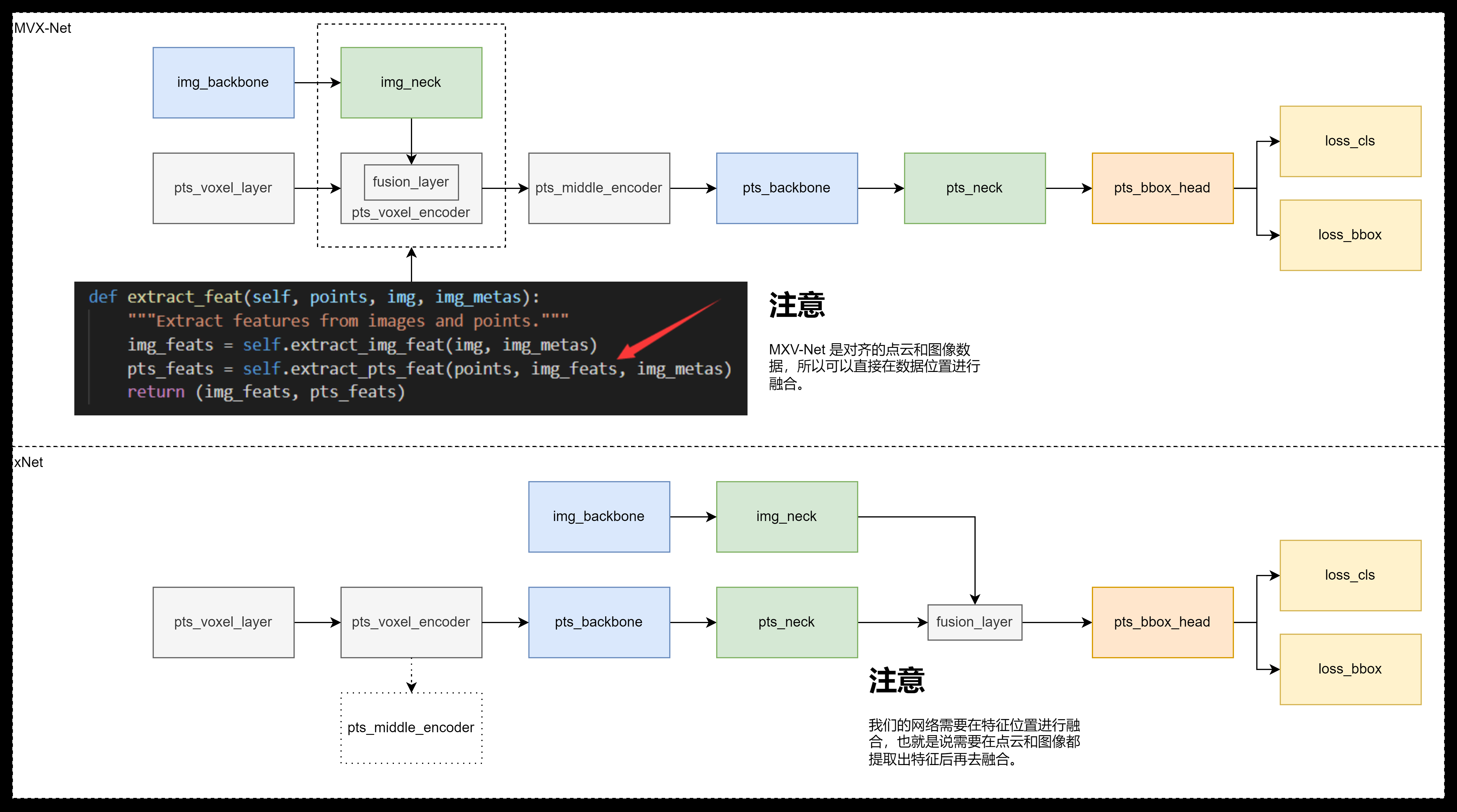
注意到代码中 fusion layer 本来是分出来的,但是因为代码复用的问题,实际上并没有分出来,导致变量冗余。我们对代码进行重构,在完成图像和点云特征提取后再使用 fusion layer 合并。
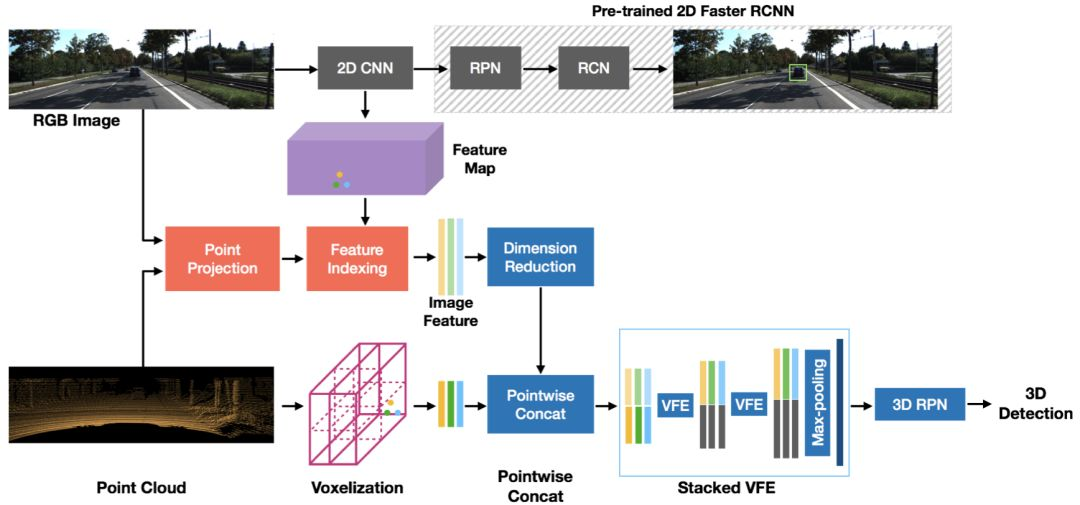
上述问题描述并不正确,这样的结构不仅仅是因为代码复用,也是因为分析的MVX-Net的模型的结构。MVX-Net是一个数据级融合,需要对齐点云和图像数据,然后将图像的数据提炼(降维),然后将提炼后的数据补充到点云数据上,最后进入检测主干网络(这里用的SECOND backbone)。
哪一块儿网络需要预训练参数,哪里就加上Pretrained参数,格式为Pretrained="<模型路径>"
小技巧:直接搜索配置文件中的tpye关键字即可找到对应的模型类位置。
主模态交换网络是可以使用的,而且很容易实现,因为在fusion返回了每一个模态对应的输出,所以只要融合以后返回对应的就好了。
辅模态Attention机制稍微有些麻烦,需要多出来很多的计算量,但是也是很简单就可以实现的。
PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds

我们也可以直接用PointNet++的解码器来做这件事。
将数据集软链接到工作目录下。
ln -/usr/local/mysql/bin/mysql /usr/bin
使用wget下载anaconda,配置运行权限,开始安装。
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
pip install "mmcv-full>=1.3.17, <=1.5.0" -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.1/index.html
pip install "mmdet>=2.19.0, <=3.0.0"
pip install "mmsegmentation>=0.20.0, <=1.0.0"
python tools/train.py configs/xnet/xnet_model_Voxel_SECOND_ResNet_Fusion_kitti-3d-car.py原先使用的MVX使用的是预训练图像特征提取网络,所以代码中没有图像特征提取模型的训练。
# 单卡训练:
python tools/train.py ${CONFIG_FILE} [optional arguments]
# 指定显卡训练:
CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG_FILE} 4# 单块显卡测试/生成评估结果
python
tools/test.py
${CONFIG_FILE}
${CHECKPOINT_FILE}
[--out ${RESULT_FILE}]
[--eval ${EVAL_METRICS}]
[--show]
[--show-dir ${SHOW_DIR}]
# 多块显卡测试/生成评估结果
./tools/dist_test.sh
${CONFIG_FILE}
${CHECKPOINT_FILE}
${GPU_NUM}
[--out ${RESULT_FILE}]
[--eval ${EVAL_METRICS}]
# 将三维检测框投影到图像
python
demo/multi_modality_demo.py
${PCD_FILE}
${IMAGE_FILE}
${ANNOTATION_FILE}
${CONFIG_FILE}
${CHECKPOINT_FILE}
[--device ${GPU_ID}]
[--score-thr ${SCORE_THR}]
[--out-dir ${OUT_DIR}]
[--show]- 显存问题:Pytorch Memory management
- 解决no grad问题:https://discuss.pytorch.org/t/ddp-parameters-didnt-receive-gradients-for-used-module/137796
- concate方法实现,不需要修改太多的东西,我们只需要保证Fusion layer输出的形状是4维即可。
可以使用tensorboard监控训练过程:
# 启动制作好的tensorboard环境
conda activate tensorboard-view
# 启动tensorboard
LOG_DIR="relative/path/to/tf_logs/dir"
tensorboard --logdir ${LOG_DIR}使用vscode执行上述命令后,服务器上的链接会转到本地,根据终端提示,打开链接即可看到监控窗口。

- Linux 启动后台任务的指令的方法是在命令后添加
&,但是这段命令是当前终端的子线程,终端退出,线程结束。如果不希望子线程退出,可以使用nohup命令,忽略退出命令。参考:Linux nohup 命令
可以写一个后台多显卡训练脚本:
#!/bin/bash
CONFIG_FILE="relative/path/to/config/file"
NUM_GPUS=5
CUDA_VISIBLE_DEVICES=0,1,2,5,6 \
PORT=8990 \
nohup \
tools/dist_train.sh \
${CONFIG_FILE} \
${NUM_GPUS} \
&- 完成GPU排队脚本:脚本详情待更新
Pearson相关矩阵
图神经网络torch库
释放引后台脚本占用的GPU
ps -ef | grep yanghao+.*train.py | grep -v grep |cut -c 9-15 | xargs kill
ps -ef | grep 【进程名正则表达式】 | grep -v grep |cut -c 9-15 | xargs kill -9- 第一版PearsonFusion:将高相关性的通道剔除,保留相互独立的通道。
- 改进策略:高相关性的通道应该也需要保留才对,而不是一股脑剔除。就像之前说过的,将高相关性的通道取平均,将独立的通道叠加
- 使用 gcn2 作为主要网络
首先最开始的pearson fusion的简单融合方法是不可行的,不能很好的进行特征提取。如果在后面添加太过庞大的GNN网络,现在的设备是运算不动的,所以我们缩小我们的网络,在表层进行初步的特征提取,经过融合后再进行进一步的特征提取。
但是现在的网络结构已经非常简单了,进一步简化可能也没有必要了,所以内存开销是哪里来的呢?无非是参数设置的太大了,减小一些特征通道数量吧。
所以接下来的开发计划如下:
- 对现在的代码进行重构,使用在模型上添加不同模块的形式,而不是一个一个FusionLayer拆开。
- 对代码进行去重,构建更加合理的代码结构,并添加模块的注释。
重构后的融合层分为四个部分:融合前的特征预处理(pre fusion,如特征补齐)、特征相关性图生成(get graph)、特征融合(fusion)、特征融合层颈部网络(fusion neck,与下游任务对接)
需要在服务器有可使用资源的时候进行debug和下一步的开发工作。
接下来是继续增加模块,进行实验。
经过一段时间的实验,可以确定的是根据x得到的邻接矩阵很难很好的指导网络融合,还是需要可训练参数在其中。
所以对于新的模型邻接矩阵的预测有两种,第一种是使用深度学习网络直接预测邻接矩阵,第二种是添加邻接矩阵部分的损失函数。
修改了torch geometric库中加载模型参数的部分。

因为在第17轮后模型开始过拟合,所以我们尝试固定图预测部分的神经网络参数,重新开始训练模型其他部分。
下一步考虑多尺度特征图,不仅仅是考虑融合后的结果。
注:下表中的每一个epoch的数字几乎没有价值,因为是加载了预训练模型参数的。
| 实验标签 | 表现最优模型 | Overall bbox A40 moderate | Car bbox AP40 moderate | 实验描述 |
|---|---|---|---|---|
| xnet_base | epoch_37 | 83.4838 | 92.7984 | 点云单模态SECOND |
| xnet_exp00 | epoch_2 | 81.1241 | 92.1264 | 多模态特征通道拼接 |
| xnet_exp01 | epoch_21 | 68.3767 | 79.8669 | 多模态特征GCN |
| xnet_exp01_1 | epoch_5 | 72.0928 | 79.0513 | 多模态特征GCN+freeze |
| xnet_exp01_2 | epoch_14 | 47.8480 | 26.4355 | 多模态特征提取GCN+FPN |
| xnet_exp01_3/4 | epoch_NA | NA | NA | 多模态特征提取DGCN+DFPN |
因为notear方法的开销是因为cpu叉乘,我们可以先减小每一个通道的大小,然后再进行运算。
| 模块 | PreFusionCat | GetGraphPearson | FusionNN | FusionSummation | FusionGNN | FusionNeck |
|---|---|---|---|---|---|---|
| base | ||||||
| exp00 | ✅ | ✅ | ✅ | |||
| exp01 | ✅ | ✅ | ✅ | ✅ | ||
| exp02 | ✅ | ✅ | ✅ | ✅ |
代码更新
更新内容:这里可以写 commit message
下一步开发任务:稍微写一下
Gitee仓库链接:https://gitee.com/discover304/MMDetection3D-Explainable