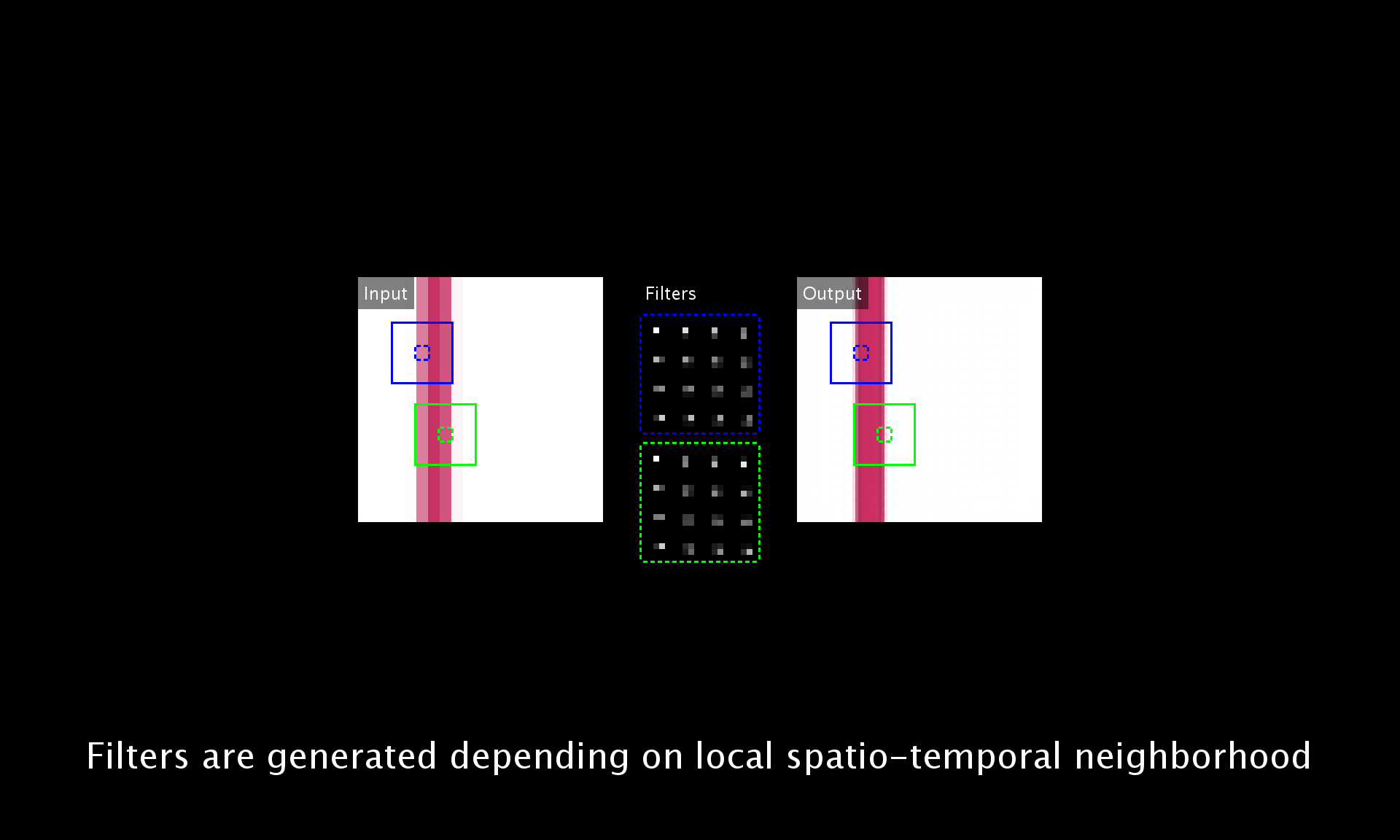
Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation
This is a tensorflow implementation of the paper. PDF
./inputs/G/ Ground-truth video frames
./inputs/L/ Low-resolution video frames
./results/<L>L/G/ Outputs from given ground-truth video frames using depth network
./results/<L>L/L/ Outputs from given low-resolution video frames using depth network
Put your video frames to the input directory and run test.py with arguments <R>, <L> and <T>.
python test.py <R> <L> <T>
<R> is the upscaling factor of 2, 3, 4.
<L> is the depth of network of 16, 28, 52.
<T> is the type of input frames, G denotes GT inputs and L denotes LR inputs.
For example, python test.py 4 16 G super-resolve input frames in ./inputs/G/* using 16 depth network with upscaling factor 4.
(Possible combinations for <R> <L> is 2 16, 3 16, 4 16, 4 28, and 4 52.)
This code was tested under Python 2.7 and TensorFlow 1.3.0.
@InProceedings{Jo_2018_CVPR,
author = {Jo, Younghyun and Oh, Seoung Wug and Kang, Jaeyeon and Kim, Seon Joo},
title = {Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}