ChatTTS-Forge 是一个功能强大的文本转语音生成工具,支持通过类 SSML 语法生成丰富的音频长文本,并提供全面的 API 服务,适用于各种场景。无论是个性化的语音生成,还是高效的说话人和风格管理,ChatTTS-Forge 都能满足你的需求。
在线体验: ChatTTS-Forge 在线体验
- 风格提示词注入: 灵活调整输出风格,通过注入提示词实现个性化。
- 全面的 API 服务: 所有功能均通过 API 访问,集成方便。
- 友好的调试 GUI: 独立于 Gradio 的 playground,简化调试流程。
- OpenAI 风格 API:
/v1/openai/audio/speech提供类似 OpenAI 的语音生成接口。 - Google 风格 API:
/v1/google/text:synthesize提供类似 Google 的文本合成接口。 - 类 SSML 支持: 使用类 SSML 语法创建丰富的音频长文本。
- 说话人管理: 通过名称或 ID 高效复用说话人。
- 风格管理: 通过名称或 ID 复用说话风格,内置 32 种不同风格。
- 文本标准化: 针对 ChatTTS 优化的文本标准化,解决大部分不支持的 token。
- 独立 refine API: 提供单独的 refine 调试接口,提升调试效率。
- 高效缓存机制: 生成接口采用 LRU 缓存,提升响应速度。
-
克隆项目:
git clone https://github.com/lenML/ChatTTS-Forge.git -
准备模型,放到如下目录
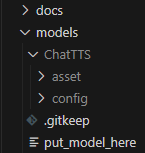
-
自行下载(任选其一)
-
使用脚本下载(任选其一)
- HuggingFace: 执行
python ./download_models.py --source huggingface - ModelScope: 执行
python ./download_models.py --source modelscope
- HuggingFace: 执行
-
-
安装 ffmpeg:
apt-get install ffmpeg -
安装 rubberband:
apt-get install rubberband-cli -
安装 Python 依赖:
python -m pip install -r requirements.txt

显存消耗估计在 3.7GB 左右
python launch.py| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
--host |
str |
"0.0.0.0" |
服务器主机地址 |
--port |
int |
8000 |
服务器端口 |
--reload |
bool |
False |
启用自动重载功能(用于开发) |
--compile |
bool |
False |
启用模型编译 |
--lru_size |
int |
64 |
设置请求缓存池的大小;设置为 0 禁用 lru_cache |
--cors_origin |
str |
"*" |
允许的 CORS 源,使用 * 允许所有源 |
| 项目 | 描述 | 部署或使用方式 | 图片 |
|---|---|---|---|
| API | 部署后打开 http://localhost:8000/docs 可查看详细信息 |
运行python launch.py |
 |
| WebUI | 某些情况可能需要 WebUI(比如免费使用 HuggingFace),这里实现了一个最简单的版本 | 运行 python webui.py |
 |
| Playground | 实现了一套用于调试 API 的 Playground 前端页面,独立于 Python 代码非 Gradio | 部署后打开 http://localhost:8000/playground/index.html |
 |
noop
WIP 开发中
- ChatTTS: https://github.com/2noise/ChatTTS
- PaddleSpeech: https://github.com/PaddlePaddle/PaddleSpeech