![]()


cd frontend
npm install
frontend디렉토리에서 수행해야 합니다.
npm run dev
./gradlew clean build
- 미션 진행 후에 아래 질문의 답을 작성하여 PR을 보내주세요.
- 인덱스 설정을 추가하지 않고 아래 요구사항에 대해 1s 이하(M1의 경우 2s)로 반환하도록 쿼리를 작성하세요.
- 활동중인(Active) 부서의 현재 부서관리자 중 연봉 상위 5위안에 드는 사람들이 최근에 각 지역별로 언제 퇴실했는지 조회해보세요. (사원번호, 이름, 연봉, 직급명, 지역, 입출입구분, 입출입시간)
Environment
- "M1 MacBook Pro"
- "MySQL Workbench"
SQL DML
SELECT t.employee_id AS 사원번호,
t.last_name AS 이름,
t.annual_income AS 연봉,
t.position_name AS 직급명,
j.time AS 입출입시간,
j.region AS 지역,
j.record_symbol AS 입출입구분
FROM (
SELECT d.id,
m.employee_id,
e.last_name,
p.position_name,
s.annual_income
FROM tuning.department d
INNER JOIN tuning.manager m ON d.id = m.department_id
INNER JOIN tuning.employee e ON m.employee_id = e.id
INNER JOIN tuning.position p ON e.id = p.id
INNER JOIN tuning.salary s ON s.id = m.employee_id
WHERE d.note = 'active'
AND NOW() BETWEEN m.start_date AND m.end_date
AND NOW() BETWEEN p.start_date AND p.end_date
AND NOW() BETWEEN s.start_date AND s.end_date
ORDER BY s.annual_income DESC
LIMIT 5
) t
INNER JOIN
(
SELECT r.employee_id,
r.time,
r.region,
r.record_symbol
FROM tuning.record r
WHERE r.record_symbol = 'O'
) j
ON j.employee_id = t.employee_id;SQL Execution Explain
 SQL Query Results
SQL Query Results

- 인덱스 적용해보기 실습을 진행해본 과정을 공유해주세요
Environment
- "M1 MacBook Pro"
- "MySQL Workbench"
Answer 1) Coding as a Hobby 와 같은 결과를 반환
- 기존 실행 쿼리
SELECT p.hobby AS 'answer', CONCAT(ROUND((COUNT(p.hobby) / (SELECT COUNT(1) FROM programmer)) * 100, 1), '%') AS 'ratio' FROM subway.programmer p GROUP BY p.hobby ORDER BY p.hobby DESC;
- 실행 계획
- 실행 결과
- 실행 시간 : 4.177 sec
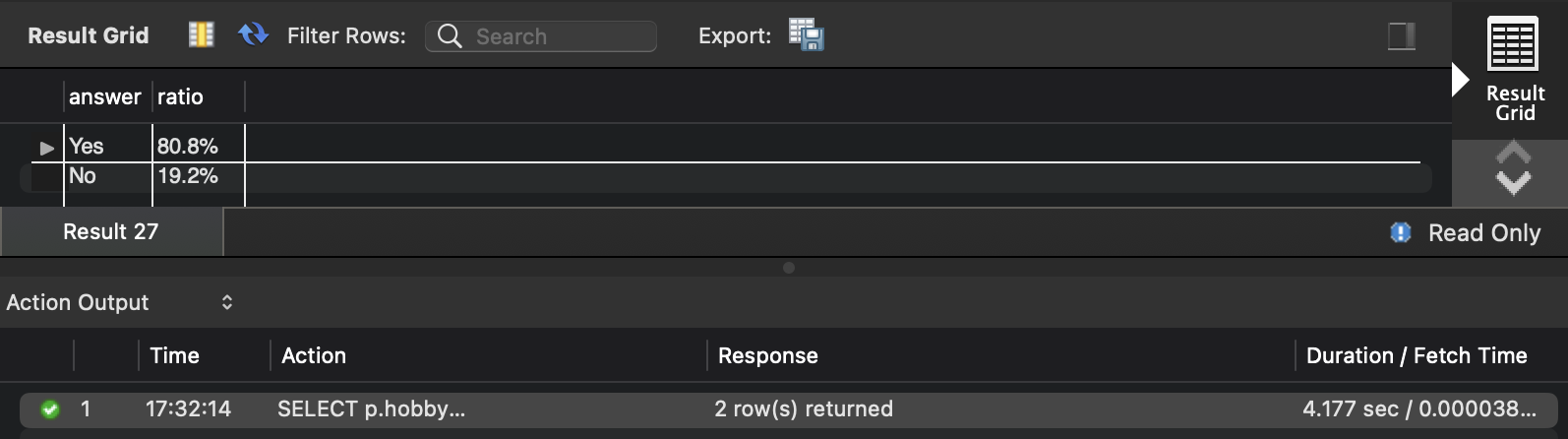
- 실행 계획
- 인덱싱 추가
create index idx__programmer_hobby on programmer (hobby);
- 실행 계획
- 실행 결과
- 실행 시간 :
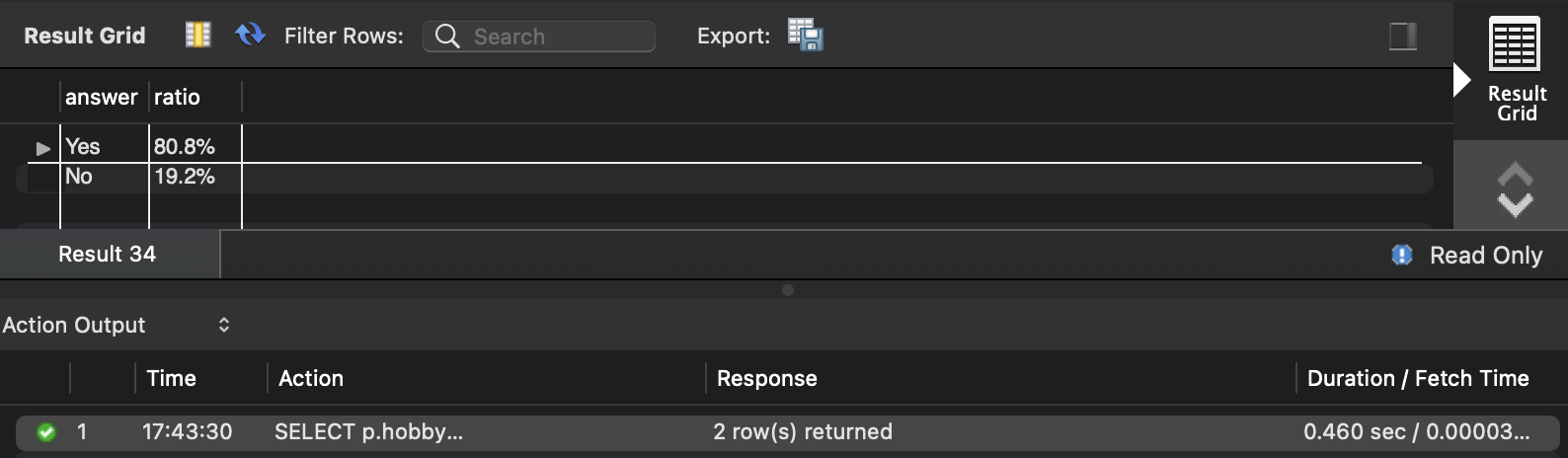
- 실행 계획
- 개선 시간
- 4.177 sec -> 0.460 sec : 89% 개선




Answer 2) 프로그래머별로 해당하는 병원 이름을 반환 (covid.id, hospital.name)
- 기존 실행 쿼리
SELECT c.id AS covid_id, h.name AS hospital_name FROM covid c INNER JOIN programmer p ON c.programmer_id = p.id INNER JOIN hospital h ON c.hospital_id = h.id;
- 실행 계획
- 실행 결과
- 실행 시간 : 3.974 sec
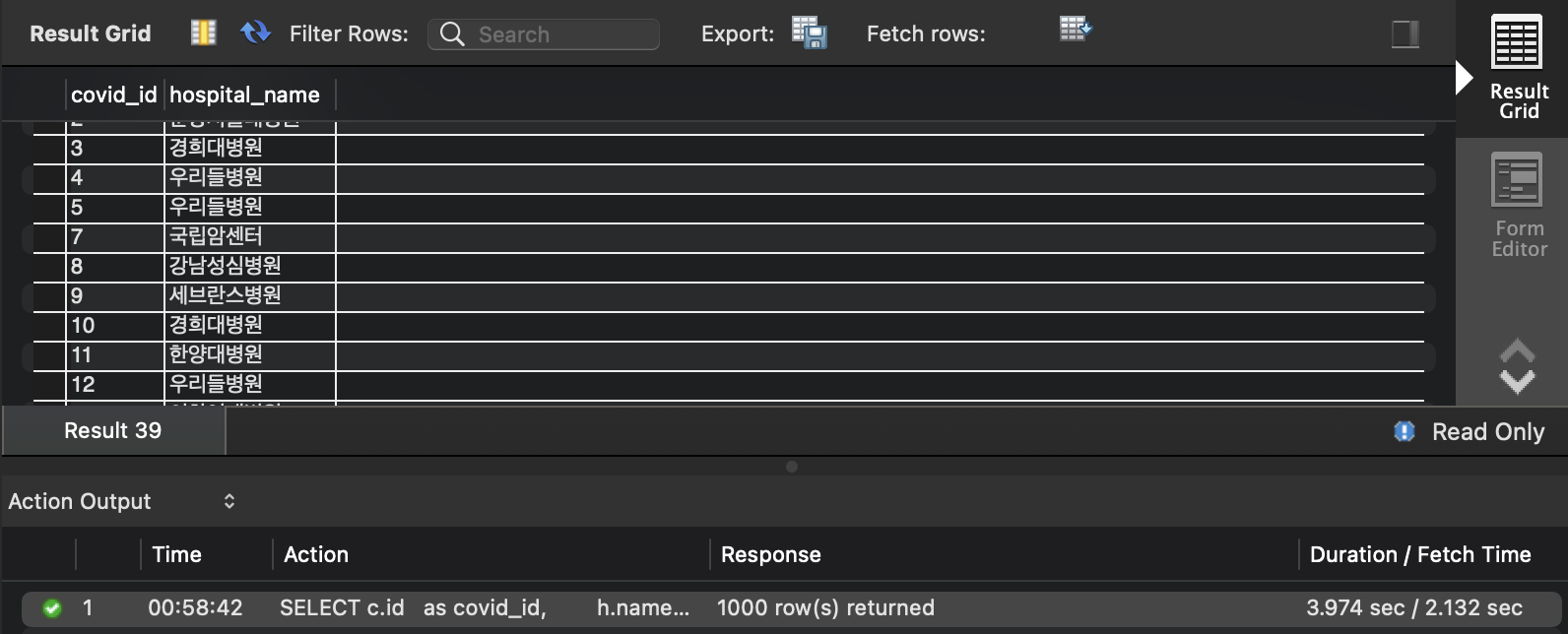
- 실행 계획
- 인덱싱 추가
-
ALTER TABLE covid ADD PRIMARY KEY(id); ALTER TABLE programmer ADD PRIMARY KEY(id); ALTER TABLE hospital ADD PRIMARY KEY(id); CREATE INDEX idx__covid_programmer_id ON covid (programmer_id); -- 대상 데이블의 카디널리티가 작기에 Full Index Scan 이 적용되어 이후에 적용해도 될 인덱싱 CREATE INDEX idx__covid_hospital_id ON covid (hospital_id);
- 실행 계획
- 실행 결과
- 실행 시간 : 0.037 sec
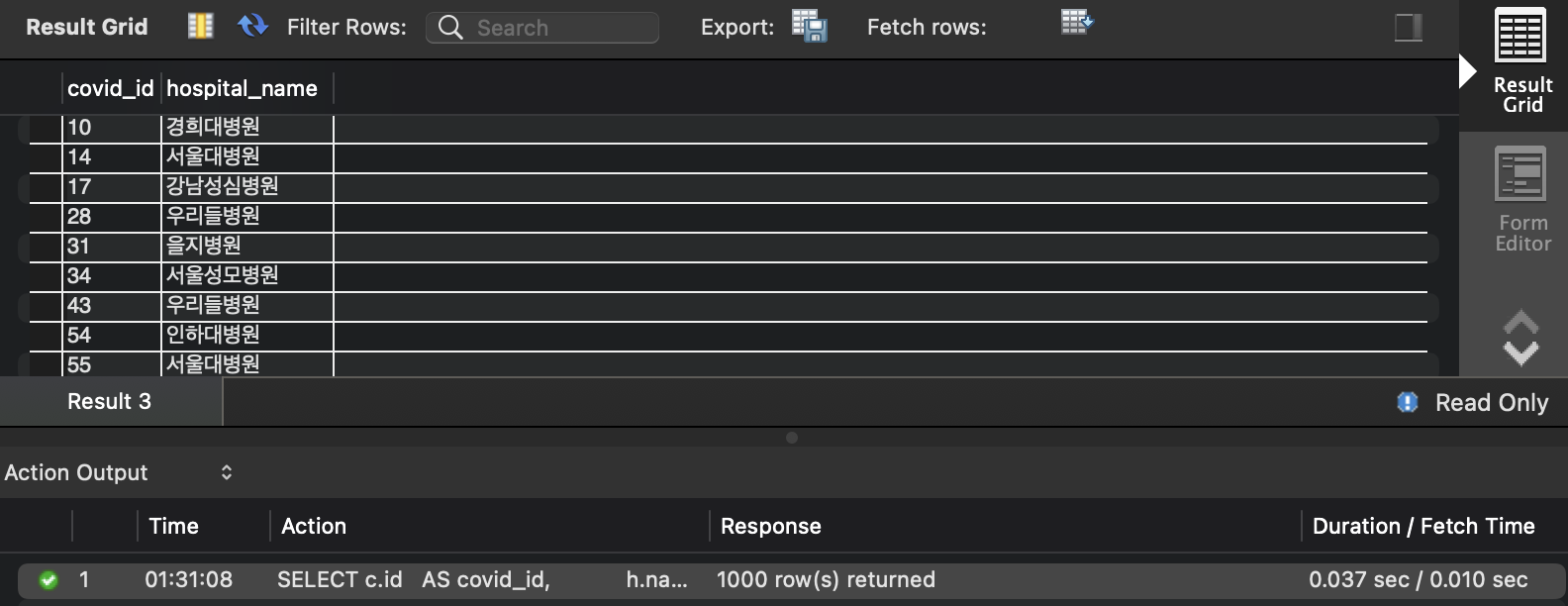
-
- 개선 시간
- 3.974 sec -> 0.037 sec : 99% 개선




Answer 3) 프로그래밍이 취미인 학생 혹은 주니어(0-2년)들이 다닌 병원 이름을 반환하고 user.id 기준으로 정렬 (covid.id, hospital.name, user.Hobby, user.DevType, user.YearsCoding)
- 기존 실행 쿼리
SELECT c.id AS covid_id, h.name AS hospital_name, p.hobby AS hobby, p.dev_type AS dev_type, p.years_coding AS years_coding FROM ( SELECT sp.id, sp.hobby, sp.dev_type, sp.years_coding FROM programmer sp WHERE sp.hobby = 'Yes' AND (sp.dev_type = 'Student' OR sp.years_coding = '0-2 years') ) AS p INNER JOIN covid c ON c.programmer_id = p.id INNER JOIN hospital h ON c.hospital_id = h.id ORDER BY p.id;
- 실행 계획
- 실행 결과
- 실행 시간 : 0.092 sec
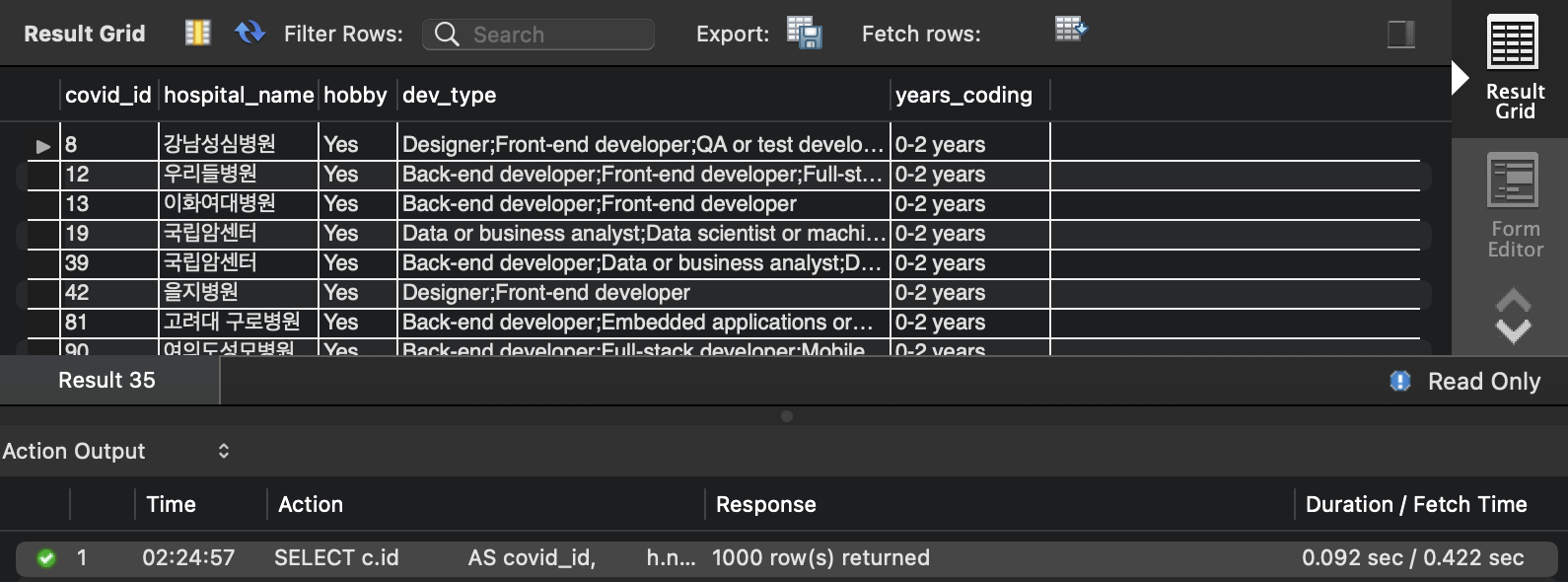
- 추가 인덱싱의 필요가 없고 기존의 인덱싱 활용
- 실행 계획


Answer 4) 서울대병원에 다닌 20대 India 환자들을 병원에 머문 기간별로 집계 (covid.Stay)
- 기존 실행 쿼리
SELECT c.stay AS '머문 기간', COUNT(c.stay) AS '머문 사람 수' FROM covid c INNER JOIN hospital h ON c.hospital_id = h.id INNER JOIN programmer p ON c.programmer_id = p.id INNER JOIN member m ON c.member_id = m.id WHERE h.name = '서울대병원' AND p.country = 'India' AND m.age BETWEEN 20 AND 29 GROUP BY c.stay;
- 실행 계획
- 실행 결과
- 실행 시간 : 0.235 sec
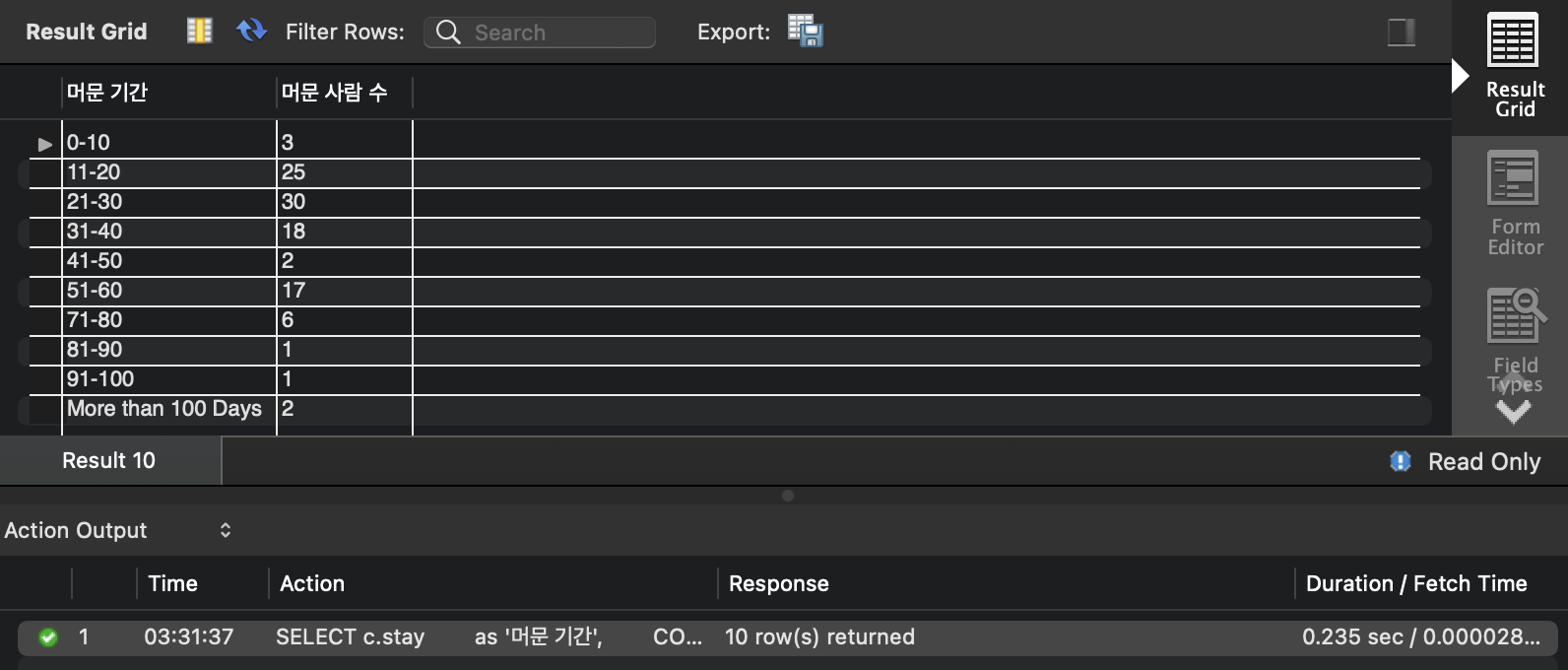
- Answer 5)부터 수행하였고, 추가 인덱싱의 필요가 없고 Answer 1),2),3)에 적용한 기존의 인덱싱 활용
- 실행 계획


Answer 5) 서울대병원에 다닌 30대 환자들을 운동 횟수별로 집계 (user.Exercise)
- 기존 실행 쿼리
SELECT p.exercise AS '운동 횟수', COUNT(p.exercise) AS '환자의 수' FROM covid c INNER JOIN hospital h ON c.hospital_id = h.id INNER JOIN member m ON c.member_id = m.id INNER JOIN programmer p ON c.programmer_id = p.id WHERE h.name = '서울대병원' AND m.age BETWEEN 30 AND 39 GROUP BY p.exercise;
- 실행 계획
- 실행 결과
- 실행 시간 : 72.969 sec
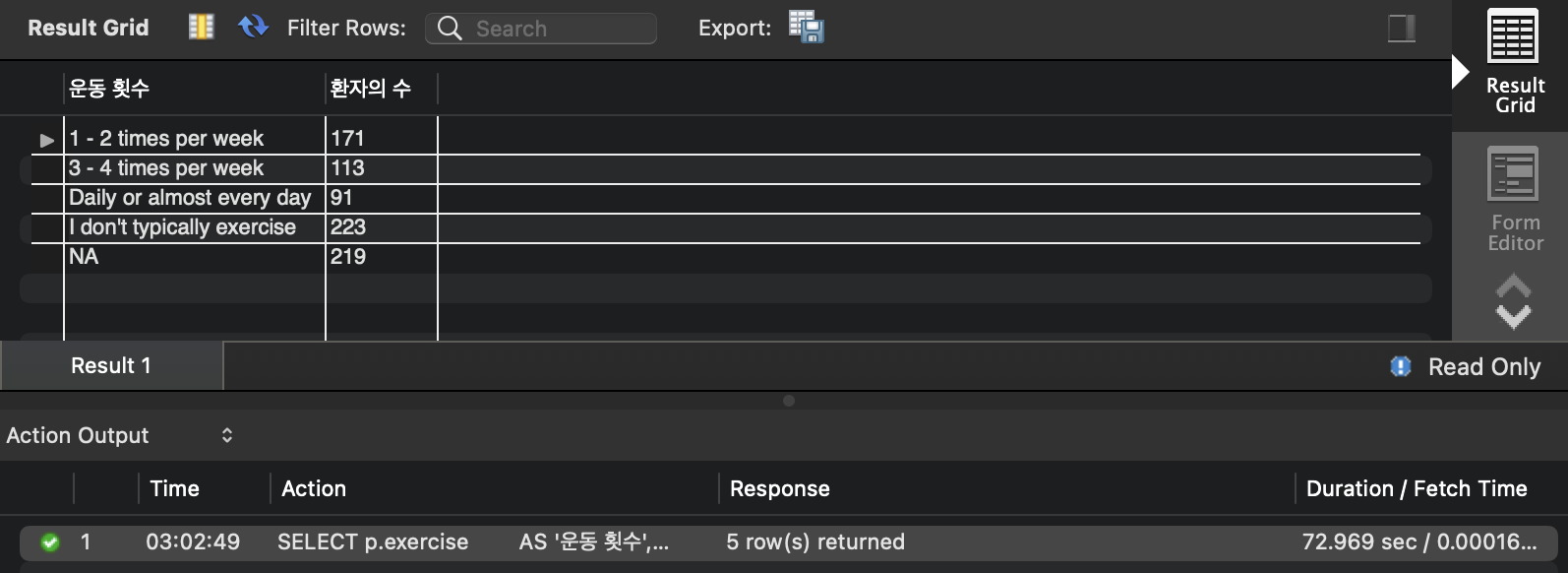
- 실행 계획
- 인덱싱 추가
-
ALTER TABLE member ADD PRIMARY KEY (id); CREATE INDEX idx__hospital_name ON hospital (name);
- 실행 계획
- 실행 결과
- 실행 시간 : 0.267 sec
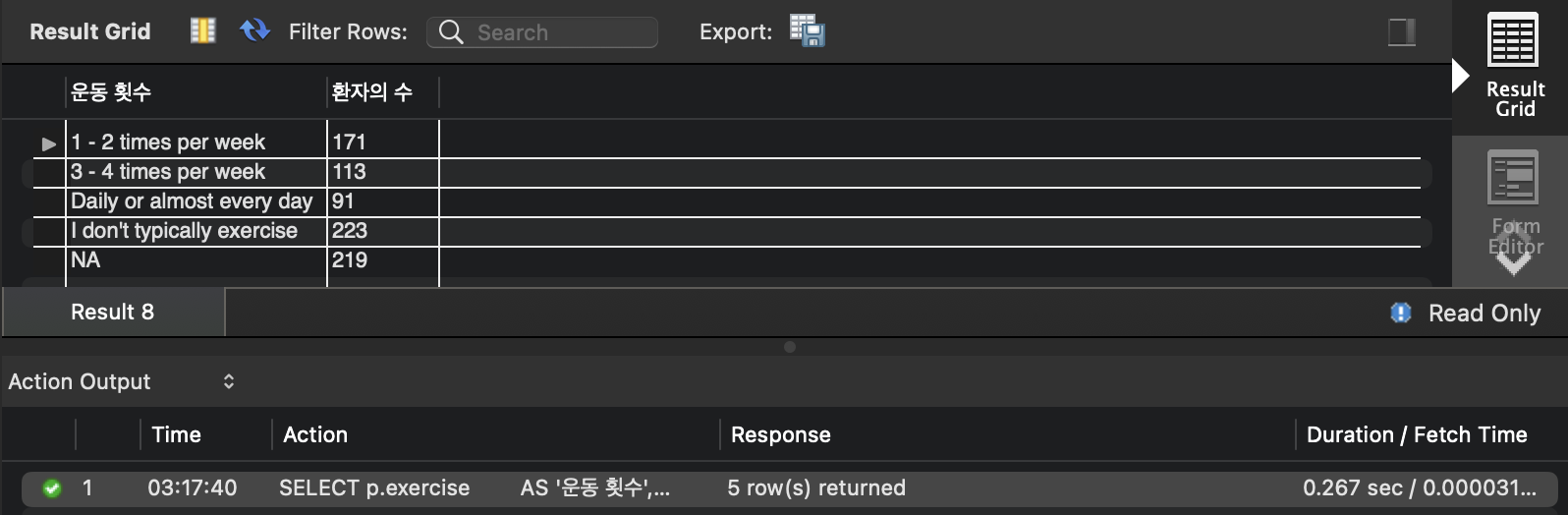
-
- 개선 시간
- 72.969 sec -> 0.267 sec : 99.63% 개선




- 페이징 쿼리를 적용한 API endpoint를 알려주세요