- The NB was originally developed on Kaggle: https://www.kaggle.com/code/yogendrayatnalkar/promtless-taskspecific-finetuning-segment-anything
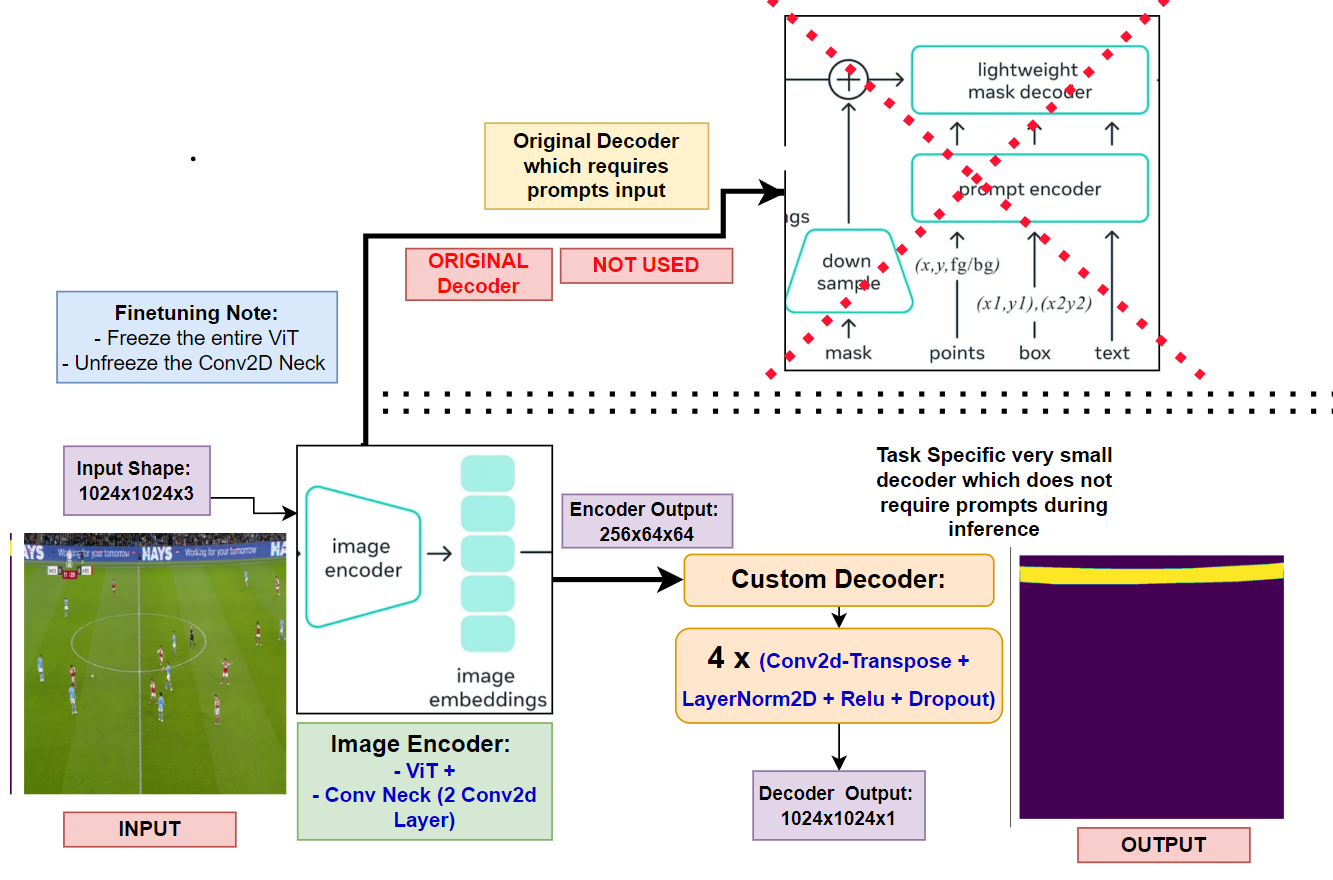
- Sam Encoder --> ViT + Neck-Module (Consisting of 2 Conv2D layers used for downsampling the channels of the ViT output)
- The Encoder ViT has a patch-size of 16x16.
- Input: 1024x1024x3
- With the above patch-size and input-image-size, the number patches formed are: 64x64
- Output of Encoder: 256x64x64
- This output goes into the decoder with Prompt Input and generates the output
- Removed the decoder
- Freeze the ViT part of encoder and un-freeze the Conv2d Neck
- Add a custom decoder having multiple blocks of: Conv2d-Transpose + LayerNorm2D + Relu + Dropout --> Added 4 such blocks
- The input to the decoder will be of shape: 256x64x64 and the output will be of shape: 1024x1024x1
- I trained this SAM+Custom-Decoder model on a open kaggle dataset consisting of binary segmentation
- Dataset has 1620 images.
- To prove SAM's capability, I trained this model only on 135 images, ie around 8.3% of the total data just for 11 epochs
-
With a 91% IOU score on a completely random test-set, the model's results are highly promising, suggesting its potential for real-world applications.
-
IMPORTANT NOTE: When the same dataset (with same train-test split) was trained using U2Net,
- with 1346 image (83% of the entire dataset)
- and 75 epochs,
- the IOU score achieved was 91%.
-
Check the result:

-
(Left-most image is the ground-truth, middle image is the model prediction, right-most image is the input)