juji hw
Part I: Requirements analysis
"Representative Tweets"
You will be developing a working Web site that allows your users to see a twitter user's "representative tweets". At most 10 "representative tweets" must be selected from the tweets of a twitter user. You are free to devise your own implementation of "representativeness", as long as you can articulate your justification.
On your site, when a user enters a person's twitter handle, your user expects to see her/his representative tweets, as well as the evidence of their representativeness. Feel free to improve the user experience in whatever ways you feel necessary given the time you have.
Your submission includes a link to the working Web site, a link (or attachment) to the source code, and a link (or attachment) to a document where you outline and justify your choices in design and implementation. You are free to use whatever tools, resources and libraries that you have a right to use.
Website Architecture
- Front-end: 1 page for user to input his twitter username. 1 page for displaying user's most 10 representative tweets.
- Back-end:
- received user's username as a request,
- return user's most representative tweets as response.
possible tools: spark java as website framework. MongoDB as database.
Here is what happens on our server, since user input a twitter account, until see his top-10 representative tweets:
- server received a twitter username.
- server use some twitter API to download this user's most recent 1000 twitters.
- server got the data and send them into a "Representativeness Ranker" so the tweets will be sorted by some ranking algorithm which I will discuss later.
- server stores the top-10 representative tweets into local DB, also send back this computing result to browser.
Representative Ranker
(Just an example)
-
Input: user's most recent 1000 original tweets.
-
Output: user's most representative 10 tweets.
Here the problem is how to define "representative"? What kind of tweet can mostly represent a user's personality or features?
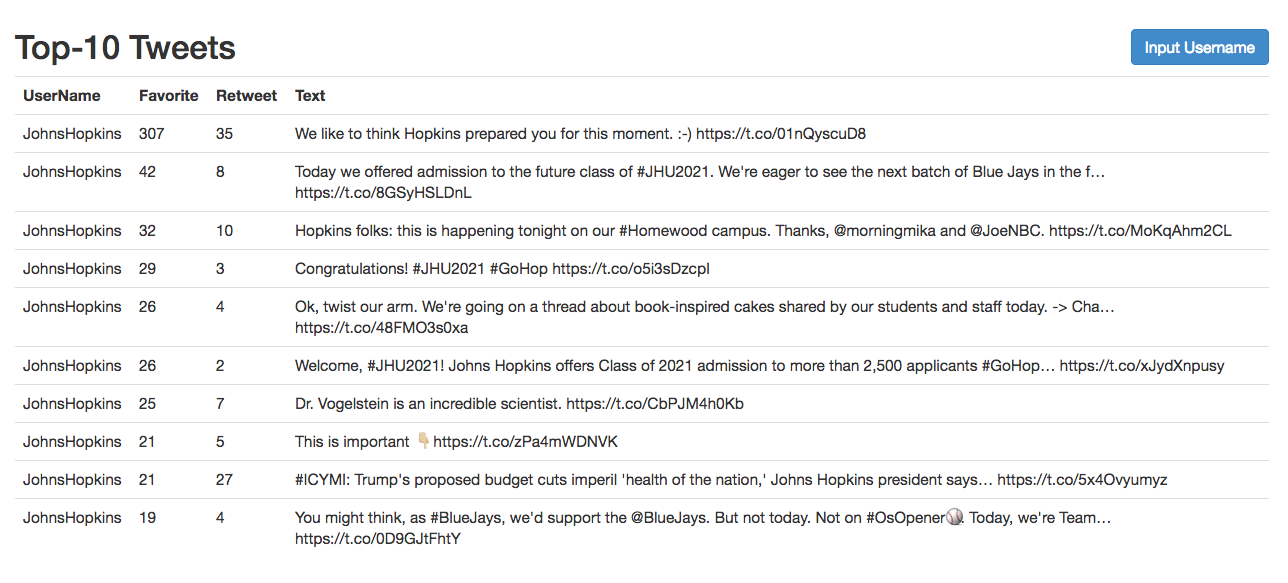
Model 1: Favorite & Retweet Amount-based:
tweets with higher "likes" and "retweets" amount.
I select "like" and "retweet" amount as a representative features based on the following tuitive assumptions:
- The input data is user's original tweets (not just copy or retweet from somewhere else).
- A user's original tweets usually coordinate with his personality and features.
- Followers follow this user usually because they appreciate his personality or features.
- Most "like" and "retweet" are from user's direct followers, or followers' followers within 2 connections.
Model 2: Tweet text content - based
Representative words always appear in a user's representative tweets. Here we simply use word frequency to measure the representativeness of a word.
This model considers the following assumption:
- A user with constant personality usually have obvious tendency on using some words instead of others.
- A word with high frequency of user's tweets usually representa user's self-evaluation, or issues what he really cares about.
Part II. Implementation
Data format
The data get from twitter is formated as @username - favorate - Retweet - Tweet text:
For example if a twitter looks like this:

Then the data what I really concern is:
@realDonaldTrump - Favorated number: 21621 - Retweeted number: 82846 -
- Did Hillary Clinton ever apologize for receiving the answers to the debate? Just asking!
Representativeness
First collect user's most recent 300 tweets from twitter API. Collector.java
Model 1: Favorite & Retweet amount-based
- Sort them based on favorite number and retweet number. Ranker1.java
- Return top-10 tweets as response and display at browser side.
- Add the top-10 into database.
Keyword Extractor
Before processed to model 2, testing the performance of KeyWordExtractor, here is a key words extraction test on given text document RFC 793 Part 1&2 . The input is a raw text, and output will be some key words.
Keyword Number : 591 Text Length: 26810
introduct
transmiss
control
protocol
tcp
intend
us
highli
reliabl
between
host
comput
commun
network
interconnect
system
document
describ
function
perform
program
implement
From the extracted key word, this document is easy to be represented as: "Introduction of reliable transmission protocol in network system communication." So I believe it is resonable to use text key words to represent tweets. In other word, if a tweet contains many key words, it should be more representative than others.
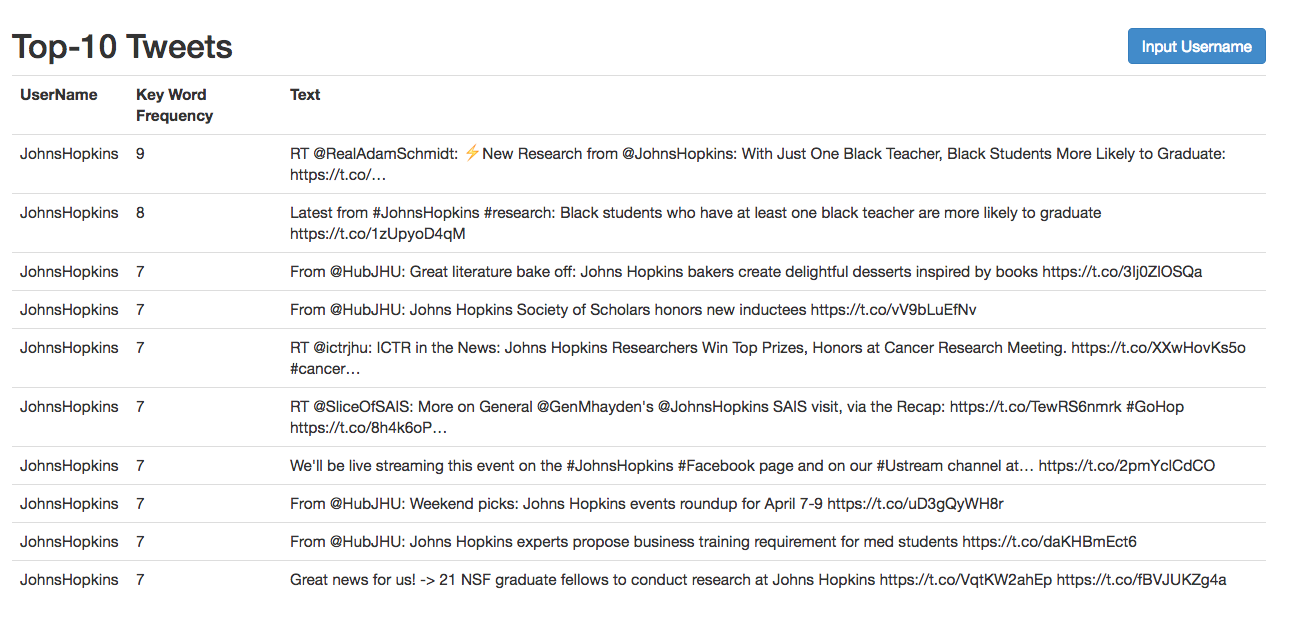
Model 2: Tweet text-based
- Append all tweets text content into a document.
- Tokenize, remove stopwords, and stemming documents, finally extract "Top-K" key words (Apache lucene).KeyWord.java
- Rank tweet based on comprehensive key words from all tweets text. To simplify this process and reduce unnecessary computation, I just use top-25 key words to training a ranker. 25 may not be an optimal number, but we can adjust it or pass as parameters when refactoring the whole project later. Ranker2.java
Sample Running Result: (Top-10 representative tweets based on keywords frequency)
Tweet Amount: 300
------- Key Words @realDonaldTrump -------
todai
co
my
great
stori
american
http
fake
job
big
trump
honor
our
media
we
veri
countri
russia
have
just
so
new
presid
make
you
@realDonaldTrump - Tweet Score:8
- content: Today on #NationalAgDay, we honor our great American farmers & ranchers. Their hard work & dedication are ingrained… https://t.co/IpGRhly2zj
@realDonaldTrump - Tweet Score:7
- content: Today we honored our true American heroes on the first-ever National Vietnam War Veterans Day.
#ThankAVeteran… https://t.co/deOHapcV4J
@realDonaldTrump - Tweet Score:7
- content: Don't let the FAKE NEWS tell you that there is big infighting in the Trump Admin. We are getting along great, and getting major things done!
@realDonaldTrump - Tweet Score:7
- content: '16 Fake News Stories Reporters Have Run Since Trump Won' https://t.co/0dHld5kiVc
@realDonaldTrump - Tweet Score:6
- content: Thank you Louisville, Kentucky. Together, we will MAKE AMERICA SAFE AND GREAT AGAIN! https://t.co/qGgWEWUvek
@realDonaldTrump - Tweet Score:6
- content: It is the same Fake News Media that said there is "no path to victory for Trump" that is now pushing the phony Russia story. A total scam!
@realDonaldTrump - Tweet Score:6
- content: Great news. We are only just beginning. Together, we are going to #MAGA! https://t.co/BSp685Q9Qf https://t.co/K7yeBZsf6r
@realDonaldTrump - Tweet Score:6
- content: Today, I was thrilled to announce a commitment of $25 BILLION & 20K AMERICAN JOBS over the next 4 years. THANK YOU… https://t.co/nWJ1hNmzoR
@realDonaldTrump - Tweet Score:6
- content: It was an honor to host our American heroes from the @WWP #SoldierRideDC at the @WhiteHouse today with @FLOTUS, @VP… https://t.co/u5AI1pupVV
@realDonaldTrump - Tweet Score:6
- content: We must fix our education system for our kids to Make America Great Again. Wonderful day at Saint Andrew in Orlando. https://t.co/OTJaHcvLzf
Final Webpages
- User input:

-
Ranker 1: based on favorite and retweet numbers.
-
Ranker 2: based on tweet text analysis.


Part III: Some concerns
Network latency
The bottleneck of responding time is server read data from twitter API. One possible solution is timestamp. Each time server only request the new posted tweets, instead of all recent tweets. I am not sure if this problem need twitter streaming API, which is used for monitoring a twitter account and update any activity of this account.
Text analysis accuracy
Based on my observation, text cleaning result is not very well. Some stopword are still extracted as key words, which is actually meaningless. In Donald trump example, some key words are meaningful: honor, america, job, great, staty, countri, etc. But also some key words is meaningless like our, yours.
Database or not
One concern about database is how frequent a user post a new tweet or delete an old one. If this kind of updating activities frequently happen, then each time computing user's representative features, we need to download all most recent data. However, if our users seldom delete old tweets and post in a low frequency, then a database is useful, because there maybe only a little new content since last time processing user's request.