KNN based regressor designed to tackle heterogenous concept drift by using a biology inspired short-/long-term memory model. By:
- Augustin Harter (University of Bielefeld) aharter@techfak.uni-bielefeld.de
- Yannik Sander (University of Bielefeld) ysander@techfak.uni-bielefeld.de
Based on Self Adapting Memory (SAM) kNN classifier developed at University of Bielefeld (Paper1)
Starting with a drift adapting classifier algorithm, we were looking for a way to turn this findings into a method for regression on streaming data.
The architecture of such SAM-kNN is already described in the paper but breaks down into the following:
- Instead of one (transient) storage three kinds of storage are assessed using a distance weighted kNN to calculate a prediction.
- The Short Term Memory (STM) is used to model the most recent concept
- The Long Term Memory (LTM) holds information about general and past concepts
- A combination of both is used to properly exploit both Memories for prediction gains
To help with adapting the STM of size n its performance is assessed on the *n/2, n/4, n/8, ..., 50 latest elements. If a smaller set yields better results than the full one the older part gets discarded.
Instead of just dropping these items, those that still comply with the STM are moved into the LTM.
To keep the LTM of size m at a reasonable size a kmeans++ clustering is conducted on it using m/2 clusters as the ltm reaches a maximum size.
To decide which memory actually gets used to make predictions, the current performance of each memory ois tracked everytime new training samples are presented. The best performing memory is subsequently used to make upcoming predictions (unless new trainig data gives another memory the edge).
More detailed steps can be found in the linked paper1
To make use of this concept in a regressor we had to make some adjustments.
First we had to find a way to track the accummulated error of each memory. While in the classifier this is quite easy, we needed to accommodate to the continual nature in a regressor. We are using the Mean Absolute Error. This makes it possible to compare memories with diffrent sizes.
Cleaning discarded items was another issue. We had to find another way to tell if elements comply with the STM. We look at the next k neighbours of each element e in the (cleaned) STM. We use these to determine a maximum distance. The difference of each item is weighted using an inverse exponential function of their distance. We use these to find a normalized maximum difference. In our discarded set we query all items around the point of e, normalize their difference and finally drop each which has a normalized difference greater than the previously determined max_difference (For every point of the STM). This one is actually discussable as we could also drop items as soon as they are not in range of at least one items of the STM.
The same technique is applied to clean the LTM instead of the kmeans++ in the original one.
To form a prediction inverse distance weighting2 is used.
-
./dataset.pyA testsuite from thescikit-multiflowproject. Uses 10 years of weather data3 (2006 - 2016, Humidity, Wind, Temperature, Air Pressure,...). See the data plotted here, as well as the value being predicted and the parameters It tries to find the real temperature given the average humidity, air pressure and wind speed. Our tests showed that using our algorithm results nearly 25 per cent smaller summed squared errors than the Hoeffding Tree implementations that come with scikit-multiflow.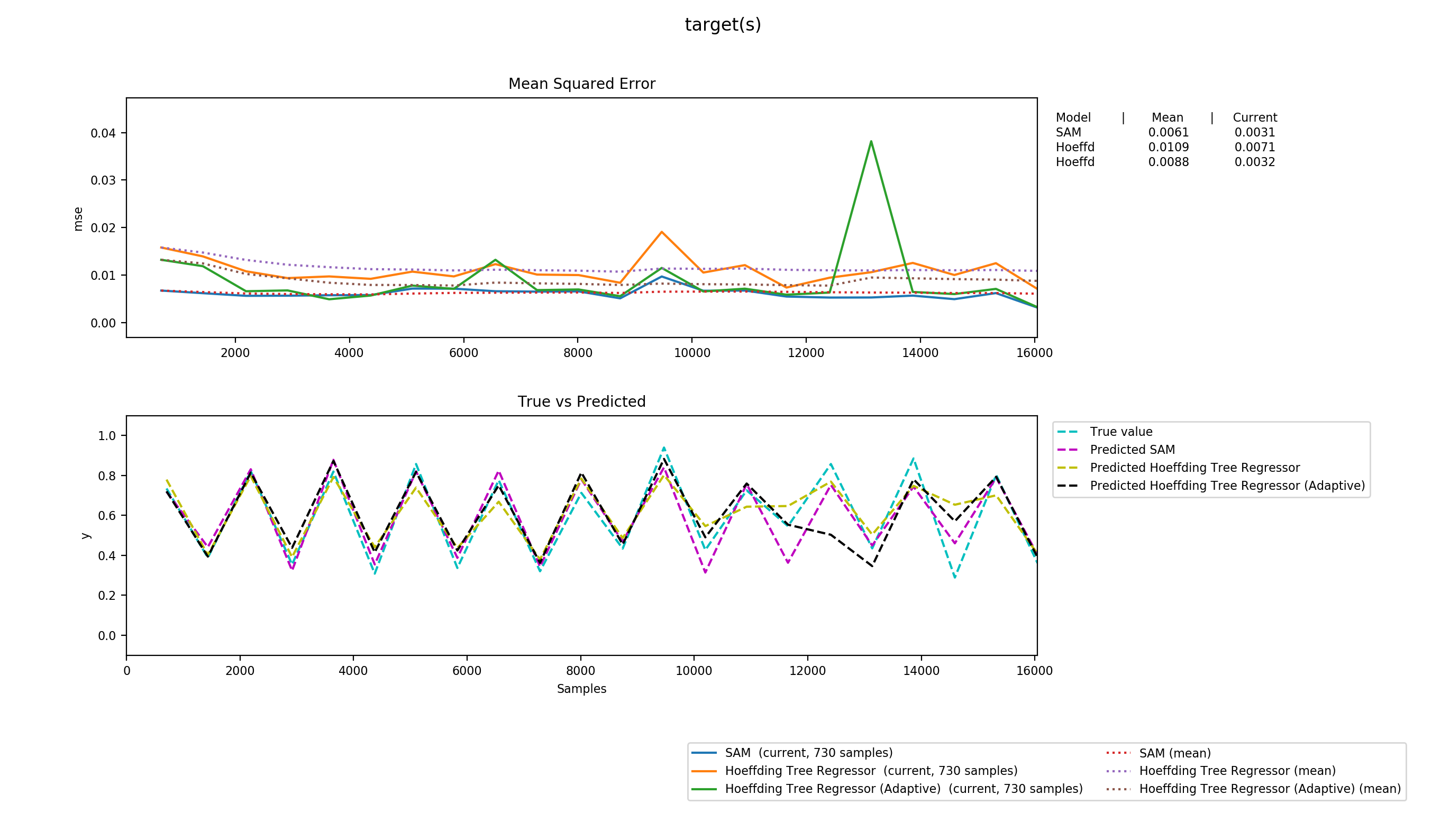 Noticably, SAM-kNN has almost always smaller error spikes than its contenders if at all.
Noticably, SAM-kNN has almost always smaller error spikes than its contenders if at all. -
./stairs.pyA simulated test that does three sweeps over the range [0..1]. Each time the lower half is constructed using the same linear function (with some gaussian noise). The uper half is computed using a random slope.Figures Explanation 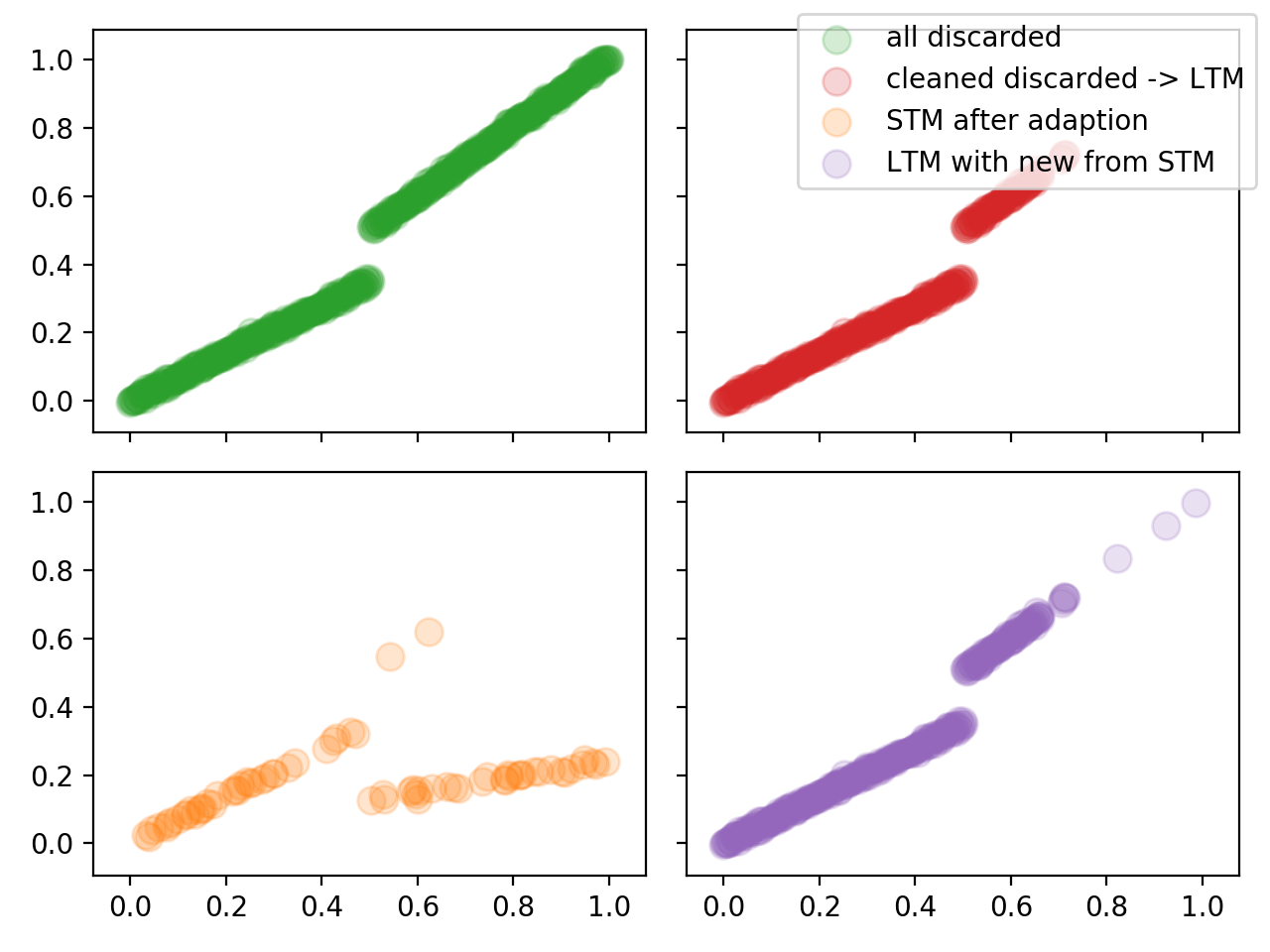
The first adaption takes place when the second random slope (new concept) becomes present enough to justify dropping 496 elements from STM. It also shows the effect of some data in the STM that act like an anchor for some of the dropped data in the upper right. 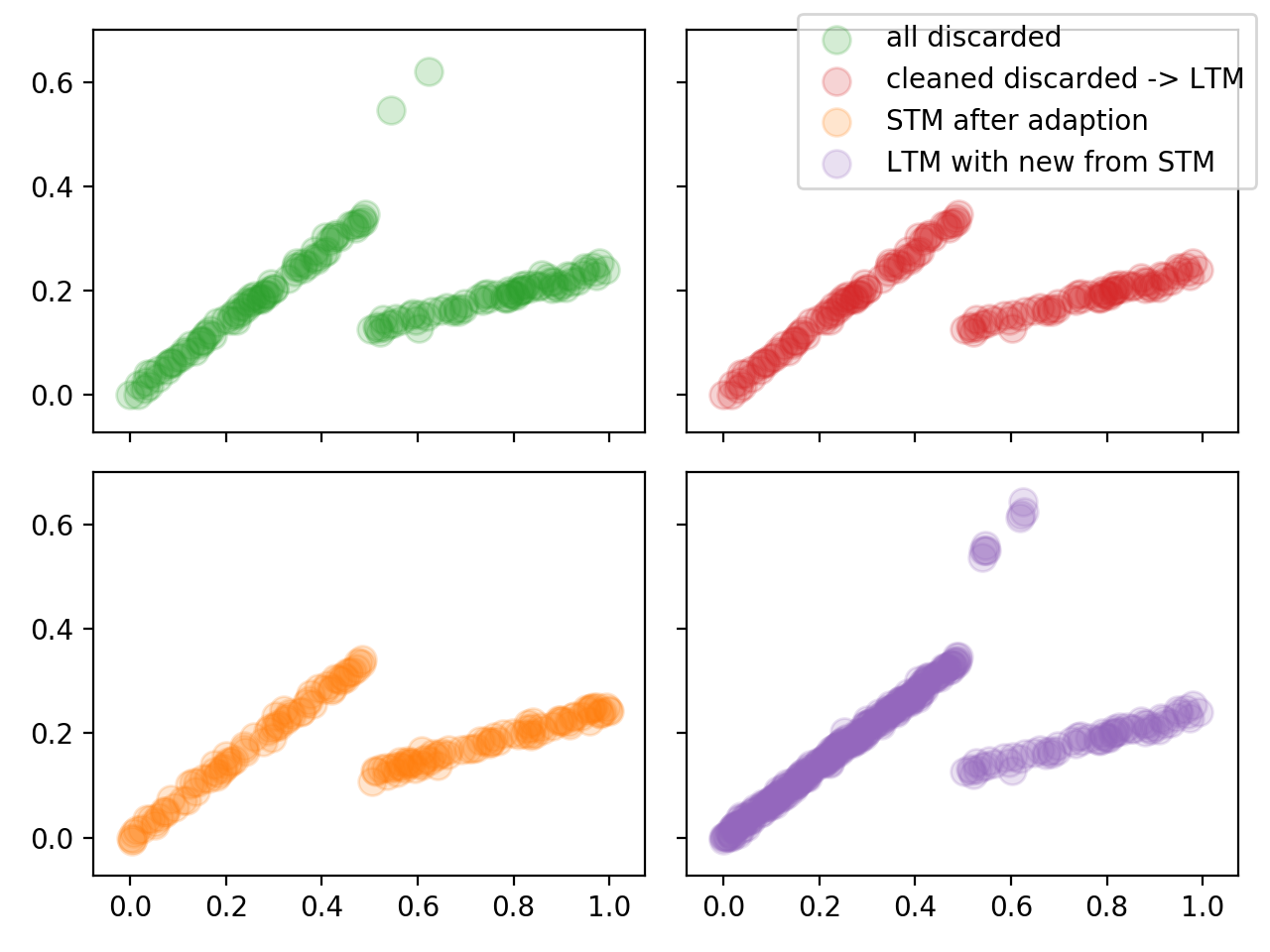
Likewise the second figure shows the second concept beeing fully adapted to. Also the LTM got cleaned intermediately as well. 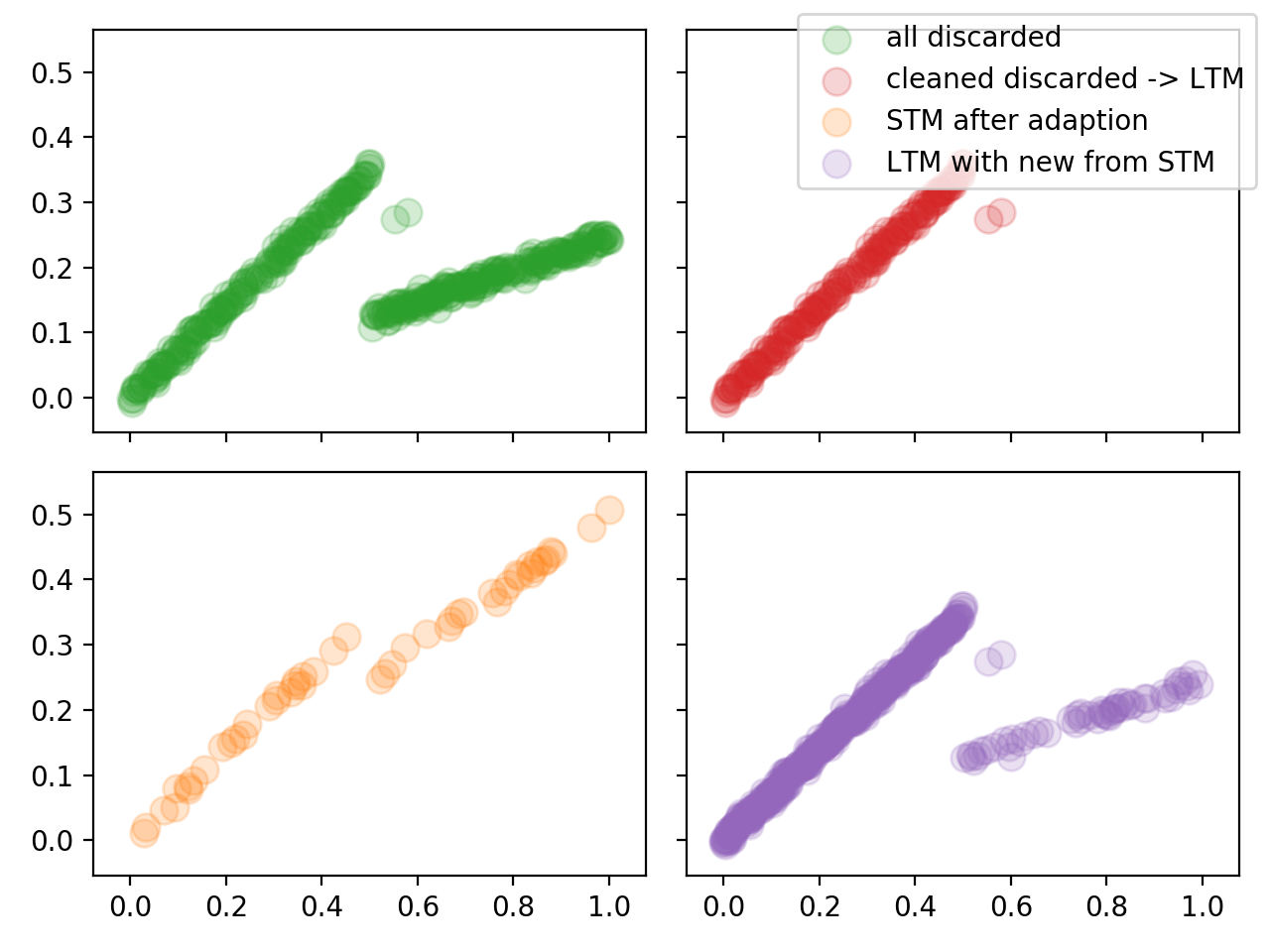
Again, the third adaption happens after the introduction of a third concept 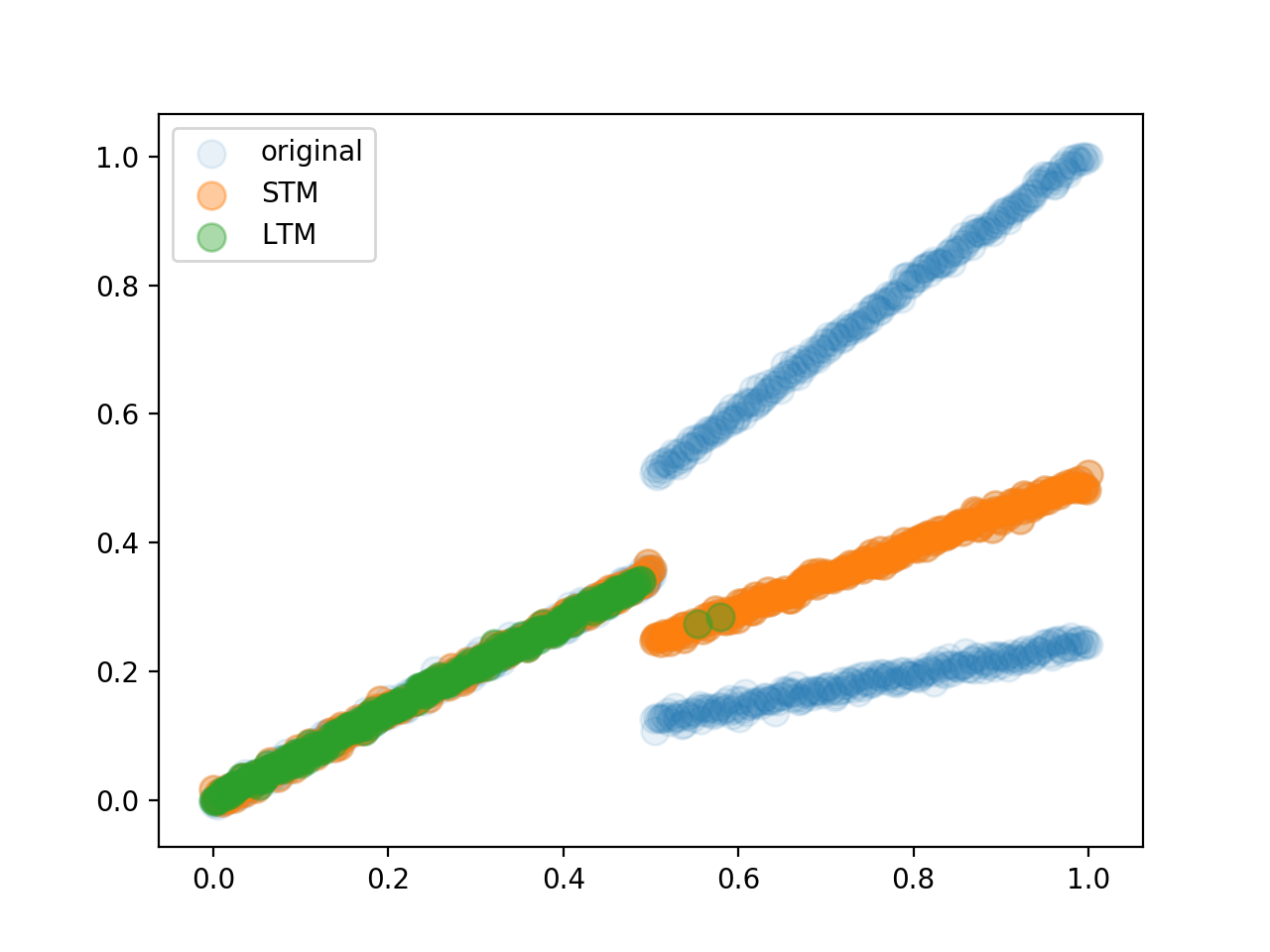
The fourth figure shows the distribution of all points other the whole input as well as the final state of LTM and STM. It proves that the model successfully kept the stable concept of the lower half in the LTM. Also the STM is perfectly adapted to the third concept, which contradicts the other concepts in the upper half. From our Log we can also see, that before Adaption the combined memory has the smallest error, and then after adaption the STM is again the most accurate. This makes sense, since the STM is smaller and with the introduction of a new concept its error increases faster, and the combined memory is used to make predictions. After adaption the STM is again the one with the smallest error and used again to make predictions.
Its still debatable if the LTM should still hold at least the previous concept in part.
-
./blopps.py [n dimensions]Generates arbitrarily dimensioned samples, with each feature following an indepedent normal distribution with randomized mean and variance. Then the features get passed into a randomized polynom to compute a corresponding target value. After a specified number of samples the distributions and the polynom are randomized again, to simulate an abrupt drift with completely new concept and feature distributions.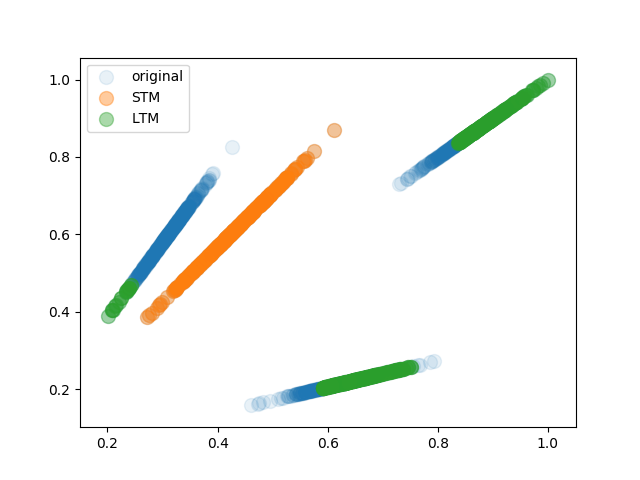
Here all polynoms happened to be linear. One dimensional input samples were generated. You can see clearly that the LTM covers the original samples in a way that they don't contradict each other and the STM covers only the newest concept. Looking at the Adaptions Adaption 1, Adaption 2 and Adaption 3 one can see that the LTM used to cover more original samples, but when the STM contradicted the LTM the contradicting samples were succesfully cleaned from the LTM.
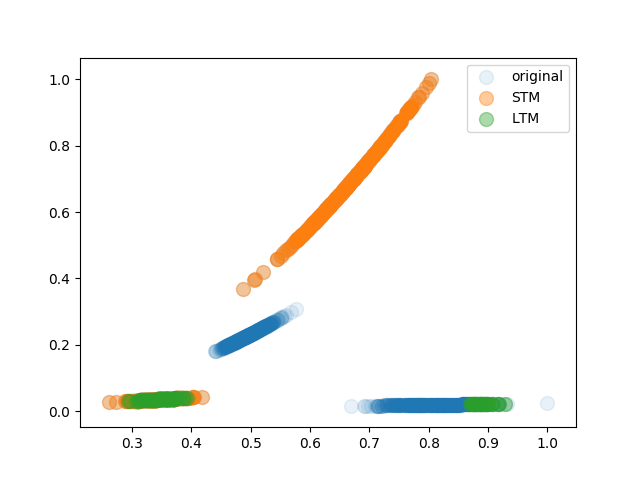
Another Example which demonstrates the succesfull cleaning of the LTM. The newest concept, represented by the STM, contradicts parts of old concepts which are still remembered in the LTM. The contradicting samples are cleaned, so that we end up with non contradicting memories.
ADAPTING: old size & error: 566 0.031908149280463025 new size & error: 70 0.02675182593747353 Added 331 of 496 to LTM. ADAPTING: old size & error: 309 0.010498344707585998 new size & error: 154 0.010302496652124097 Added 151 of 155 to LTM. ADAPTING: old size & error: 402 0.015025775010344506 new size & error: 50 0.014857742991631865 Added 173 of 352 to LTM. LTM size: 357 STM size: 497 Errors: STM: 3.1072852475465735 LTM: 100.69982470840895 COMB: 36.423858618567415Best Memory: COMB ADAPTING: old size & error: 567 0.012433790695194631 new size & error: 70 0.012336326312762044 Added 248 of 497 to LTM. Best Memory: STM ADAPTING: old size & error: 127 0.008743407322529801 new size & error: 63 0.00813022065375674 Added 64 of 64 to LTM. Best Memory: COMB ADAPTING: old size & error: 501 0.03225870387533818 new size & error: 62 0.02348357538024763 Added 250 of 439 to LTM. Best Memory: STM ADAPTING: old size & error: 121 0.014561025620511247 new size & error: 60 0.01447358256443726 Added 60 of 61 to LTM. LTM size: 341 STM size: 439 Errors: Complete Model: [0.01731821] STM: 1.650210669830953e-05 LTM: 0.03618848479111652 COMB: 0.017634074959812642







Installation with pip:
$ pip install git+https://github.com/ysndr/sam-knn-regressor.gitDevelopment using nix4
$ nix-shell
or use pinned version
$ nix-shell --arg pinned './.nixpkgs-version.json'
this will drop you into a shell with all needed dependencies installed.
Download weather data if needed from https://www.kaggle.com/budincsevity/szeged-weather or https://github.com/ssarkar445/Weather-in-Szeged-2006-20