- 두 인접한 데이터를 비교해서, 앞에 있는 데이터가 뒤에 있는 데이터보다 크면, 자리를 바꾸는 정렬 알고리즘
- 알고리즘 분석
- 반복문이 두 개 O(n^2)
- 완전 정렬이 되어 있는 상태라면 최선은 O(n)

- 두 번째 인덱스부터 시작
- 해당 인덱스(key값) 앞에 있는 데이터(B)부터 비교해서 key값이 더 작으면 B값을 뒤 인덱스로 복사
- 이를 key값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key값을 이동
- 알고리즘 분석
- 반복문이 두 개 O(n^2)
- 완전 정렬이 되어 있는 상태라면 최선은 O(n)

- 다음과 같은 순서를 반복하며 정렬하는 알고리즘
- 주어진 데이터 중 최소값을 찾음
- 해당 최소값을 데이터 맨 앞에 위치한 값과 교체함
- 맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복함

- 알고리즘 분석
- 반복문이 두 개 O(n^2)
- 재귀용법을 활용한 정렬 알고리즘
- 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
- 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
- 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.

- 알고리즘 분석
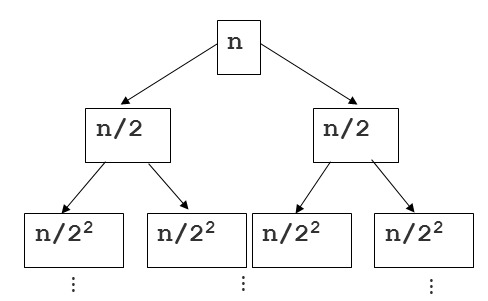
- 몇 단계 깊이까지 만들어지는지를 depth 라고 하고 i로 놓자. 맨 위 단계는 0으로 놓자
- 다음 그림에서 n/ 2^2는 2단계 깊이라고 해보자.
- 각 단계에 있는 하나의 노드 안의 리스트 길이는 n/ 2^2가 된다.
- 각 단계에는 2^𝑖개의 노드가 있다.
- 따라서, 각 단계는 항상 2^𝑖 x 𝑛/2^𝑖 = 𝑂(𝑛)
- 단계는 항상 𝑙𝑜𝑔2(𝑛)개 만큼 만들어짐, 시간 복잡도는 결국 O(log n)
- 따라서, 단계별 시간 복잡도 O(n) * O(log n) = O(n log n)
- 몇 단계 깊이까지 만들어지는지를 depth 라고 하고 i로 놓자. 맨 위 단계는 0으로 놓자
- 정렬 알고리즘의 꽃
- 기준점(pivot 이라고 부름)을 정해서, 기준점보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right)으로 모으는 함수를 작성함
- 각 왼쪽(left), 오른쪽(right)은 재귀용법을 사용해서 다시 동일 함수를 호출하여 위 작업을 반복함
- 함수는 왼쪽(left) + 기준점(pivot) + 오른쪽(right)을 리턴함
- 알고리즘 분석
- 병합정렬과 유사, 시간복잡도는 O(n log n)
- 최악의 경우
- 맨 처음 pivot이 가장 크거나 가장 작으면 모든 데이터를 비교하는 상황이 나옴 O(n^2)
- 입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결, 최종적으로 전체 문제를 해결하는 알고리즘
- 상향식 접근법으로, 가장 최하위 해답을 구한 후, 이를 저장하고, 해당 결과값을 이용해서 상위 문제를 풀어가는 방식
- Memoization 기법을 사용함
- Memoization (메모이제이션) 이란: 프로그램 실행 시 이전에 계산한 값을 저장하여, 다시 계산하지 않도록 하여 전체 실행 속도를 빠르게 하는 기술
- 문제를 잘게 쪼갤 때, 부분 문제는 중복되어, 재활용됨
- 문제를 나눌 수 없을 때까지 나누어서 각각을 풀면서 다시 합병하여 문제의 답을 얻는 알고리즘
- 하양식 접근법으로, 상위의 해답을 구하기 위해, 아래로 내려가면서 하위의 해답을 구하는 방식
- 일반적으로 재귀함수로 구현
- 문제를 잘게 쪼갤 때, 부분 문제는 서로 중복되지 않음
- 예: 병합 정렬, 퀵 정렬 등
- 탐색은 여러 데이터 중에서 원하는 데이터를 찾아내는 것을 의미
- 데이터가 담겨있는 리스트를 앞에서부터 하나씩 비교해서 원하는 데이터를 찾는 방법
- 알고리즘 분석
- 최악의 경우 리스트 길이가 n일 때, n번 비교해야 함 O(n)
- 탐색할 자료를 둘로 나누어 해당 데이터가 있을만한 곳을 탐색하는 방법
- Divide: 리스트를 두 개의 서브 리스트로 나눈다.
- Comquer
- 검색할 숫자 (search) > 중간값 이면, 뒷 부분의 서브 리스트에서 검색할 숫자를 찾는다.
- 검색할 숫자 (search) < 중간값 이면, 앞 부분의 서브 리스트에서 검색할 숫자를 찾는다.
- 알고리즘 분석
- n개의 리스트를 매번 2로 나누어 1이 될 때까지 비교연산을 k회 진행
- O(𝑙𝑜𝑔2𝑛 + 1)이고, 2와 1, 상수는 삭제 되므로, O(𝑙𝑜𝑔 𝑛)
- 그래프는 실제 세계의 현상이나 사물을 정점(Vertex) 또는 노드(Node) 와 간선(Edge)로 표현하기 위해 사용
- 노드 (Node): 위치를 말함, 정점(Vertex)라고도 함
- 간선 (Edge): 위치 간의 관계를 표시한 선으로 노드를 연결한 선이라고 보면 됨 (link 또는 branch 라고도 함)
- 인접 정점 (Adjacent Vertex) : 간선으로 직접 연결된 정점(또는 노드)
- 그래프 종류
- 무방향 그래프 : 방향이 없는 그래프, 간선을 통해 노드는 양방향으로 갈 수 있음
- 방향 그래프 : 간선에 방향이 있는 그래프
- 가중치 그래프 : 간선에 비용 또는 가중치가 할당된 그래프
- 연결 그래프/비연결 그래프
- 연결 그래프 : 무방향 그래프에 있는 모든 노드에 대해 항상 경로가 존재하는 경우
- 비연결 그래프 : 무방향 그래프에서 특정 노드에 대해 경로가 존재하지 않는 경우
- 사이클/비순환 그래프
- 사이클 : 단순 경로의 시작 노드와 종료 노드가 동일한 경우
- 비순환 : 사이클이 없는 그래프
- 완전 그래프 : 모든 노드가 서로 연결되어 있는 그래프
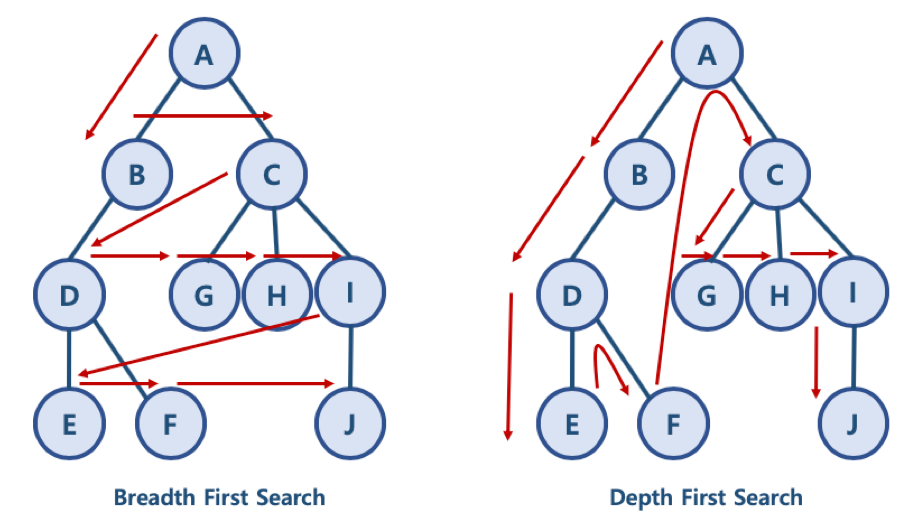
- 정점들과 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 탐색하는 방식
- 시간 복잡도 : O(V+E)
- V : 노드 수, E : 간선 수
- 정점의 자식들을 먼저 탐색하는 방식
- 시간 복잡도 : O(V+E)
- 최적의 해에 가까운 값을 구하기 위해 사용됨
- 여러 경우 중 하나를 결정해야할 때마다, 매순간 최적이라고 생각되는 경우를 선택하는 방식으로 진행해서, 최종적인 값을 구하는 방식
- 한계
- 탐욕 알고리즘은 근사치 추정에 활용
- 반드시 최적의 해를 구할 수 있는 것은 아니기 때문에 최적의 해에 가까운 값을 구하는 방법 중의 하나임
- 두 노드를 잇는 가장 짧은 경로를 찾는 문제
- 가중치 그래프 (Weighted Graph) 에서 간선 (Edge)의 가중치 합이 최소가 되도록 하는 경로를 찾는 것이 목적
- 종류
- 단일 출발 및 단일 도착
- 단일 출발 최단 경로 문제 : 그래프 내의 특정 노드 u 와 그래프 내 다른 모든 노드 각각의 가장 짧은 경로를 찾는 문제
- 전체 쌍(all-pair) 최단 경로: 그래프 내의 모든 노드 쌍 (u, v) 에 대한 최단 경로를 찾는 문제
- 다익스트라 알고리즘 : 하나의 정점에서 다른 모든 정점 간의 각각 가장 짧은 거리를 구하는 문제
- 첫 정점을 기준으로 연결되어 있는 정점들을 추가해 가며, 최단 거리를 갱신하는 기법
- 다익스트라 알고리즘은 너비우선탐색(BFS)와 유사
- 첫 정점부터 각 노드간의 거리를 저장하는 배열을 만든 후, 첫 정점의 인접 노드 간의 거리부터 먼저 계산하면서, 첫 정점부터 해당 노드간의 가장 짧은 거리를 해당 배열에 업데이트
- 시간 복잡도 : O(E log E)
- 가능한 Spanning Tree 중에서, 간선의 가중치 합이 최소인 Spanning Tree
- Kruskal’s algorithm (크루스칼 알고리즘)
- 모든 정점을 독립적인 집합으로 만든다.
- 모든 간선을 비용을 기준으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교한다.
- 두 정점의 최상위 정점을 확인하고, 서로 다를 경우 두 정점을 연결한다. (최소 신장 트리는 사이클이 없으므로, 사이클이 생기지 않도록 하는 것임)
- 시간 복잡도 : O(E log E)
- Prim's algorithm (프림 알고리즘)
- 시작 정점을 선택한 후, 정점에 인접한 간선중 최소 간선으로 연결된 정점을 선택하고, 해당 정점에서 다시 최소 간선으로 연결된 정점을 선택하는 방식으로 최소 신장 트리를 확장해가는 방식
- 임의의 정점을 선택, '연결된 노드 집합'에 삽입
- 선택된 정점에 연결된 간선들을 간선 리스트에 삽입
- 간선 리스트에서 최소 가중치를 가지는 간선부터 추출해서,
- 해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 이미 들어 있다면, 스킵함(cycle 발생을 막기 위함)
- 해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 들어 있지 않으면, 해당 간선을 선택하고, 해당 간선 정보를 '최소 신장 트리'에 삽입
- 추출한 간선은 간선 리스트에서 제거
- 간선 리스트에 더 이상의 간선이 없을 때까지 3-4번을 반복
- 시간 복잡도 : 최악의 경우, while 구문에서 모든 간선에 대해 반복하고, 최소 힙 구조를 사용하므로 O(𝐸 𝑙𝑜𝑔 𝐸)
- 제약 조건 만족 문제 (Constraint Satisfaction Problem) 에서 해를 찾기 위한 전략
- 해를 찾기 위해, 후보군에 제약 조건을 점진적으로 체크하다가, 해당 후보군이 제약 조건을 만족할 수 없다고 판단되는 즉시 backtrack (다시는 이 후보군을 체크하지 않을 것을 표기)하고, 바로 다른 후보군으로 넘어가며, 결국 최적의 해를 찾는 방법
- 실제 구현시, 고려할 수 있는 모든 경우의 수 (후보군)를 상태공간트리(State Space Tree)를 통해 표현
- 각 후보군을 DFS 방식으로 확인
- 상태 공간 트리를 탐색하면서, 제약이 맞지 않으면 해의 후보가 될만한 곳으로 바로 넘어가서 탐색
- Promising: 해당 루트가 조건에 맞는지를 검사하는 기법
- Pruning (가지치기): 조건에 맞지 않으면 포기하고 다른 루트로 바로 돌아서서, 탐색의 시간을 절약하는 기법